Thuật toán BFS là gì? Định nghĩa, Quy tắc và Ví dụ
BÀI LIÊN QUAN
Rust là gì? Những thông tin cần biết về ngôn ngữ lập trình Rust đầy đủ nhấtKhái niệm ngôn ngữ máy là gì? Những thông tin cơ bản về loại hình ngôn ngữ nàyPHP là gì? Ứng dụng của ngôn ngữ PHP trong lập trình là gì?Breadth-First Search Algorithm là gì?
Thuật toán Tìm kiếm theo chiều rộng, tiếng Anh là Breadth-First Search Algorithm, viết tắt là Thuật toán BFS.
Breadth-First Search là một thuật toán trong trí tuệ nhân tạo, được sử dụng để vẽ biểu đồ thị dữ liệu hoặc tìm kiếm cấu trúc cây hoặc duyệt. Hình thức đầy đủ của BFS là tìm kiếm theo chiều rộng.
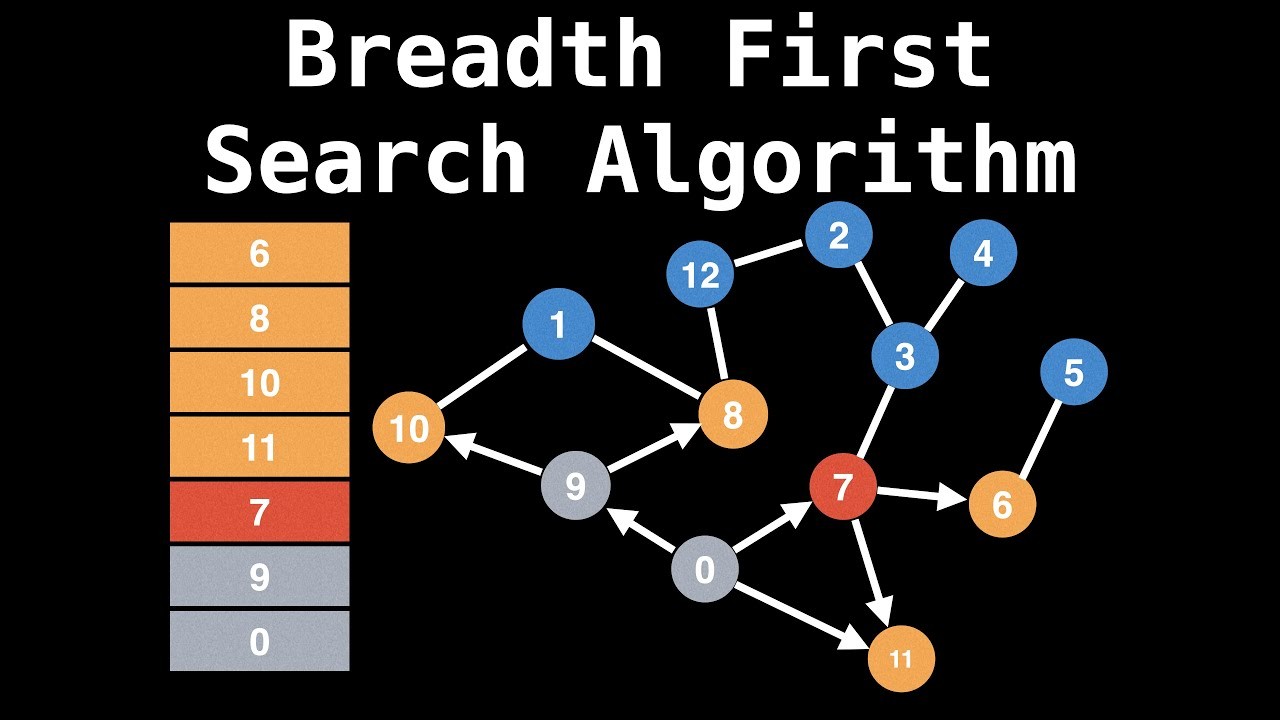
Thuật toán BFS truy cập và đánh dấu hiệu quả tất cả các nút (node) chính trong biểu đồ theo chiều rộng chính xác. Thuật toán này chọn một nút duy nhất (điểm ban đầu hoặc điểm nguồn) trong biểu đồ và sau đó truy cập tất cả các nút liền kề thông qua nút đã chọn. Lưu ý: BFS truy cập từng nút một.
Khi thuật toán truy cập và đánh dấu nút bắt đầu, sau đó nó sẽ di chuyển tới các nút chưa được truy cập gần nhất và phân tích chúng. Sau khi truy cập, tất cả các nút được đánh dấu. Các bước sẽ tiếp tục được lặp này cho đến khi tất cả các nút của biểu đồ được truy cập và đánh dấu là thành công.
Duyệt đồ thị là gì?
Duyệt đồ thị (Graph traversal) là một phương pháp thường được sử dụng để xác định vị trí đỉnh trong đồ thị. Đây là một thuật toán tìm kiếm nâng cao có thể phân tích biểu đồ với tốc độ và độ chính xác cao cũng như đánh dấu trình tự của các đỉnh đã truy cập. Quá trình này cho phép bạn nhanh chóng truy cập từng nút trong biểu đồ mà không bị khóa trong một vòng lặp vô hạn.
Kiến trúc của Breadth-First Search Algorithm
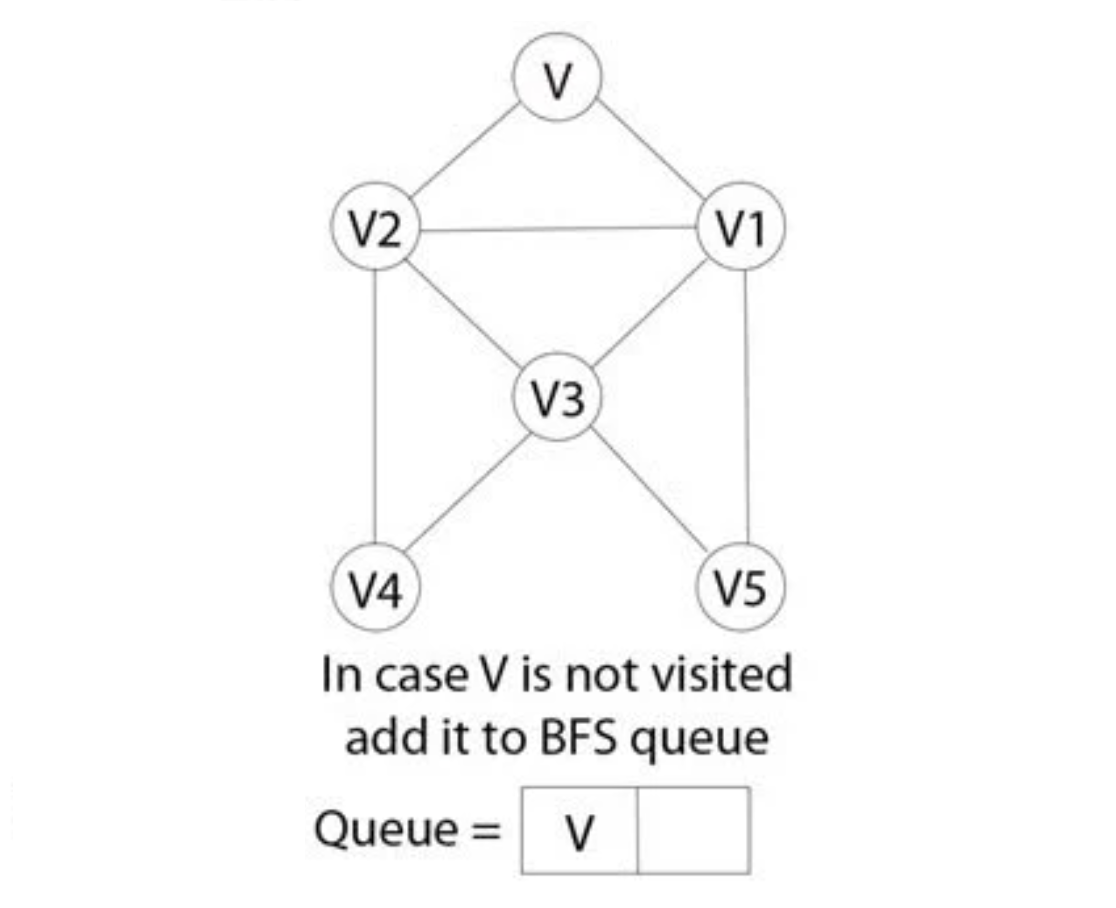
- Trong các cấp độ khác nhau của dữ liệu, bạn có thể đánh dấu bất kỳ nút nào là nút bắt đầu hoặc nút ban đầu để bắt đầu duyệt. BFS sẽ truy cập nút và đánh dấu nó là đã truy cập và đưa nó vào hàng đợi.
- Bây giờ BFS sẽ truy cập các nút gần nhất, chưa được truy cập và đánh dấu chúng. Các giá trị này cũng được thêm vào hàng đợi. Hàng đợi hoạt động trên mô hình FIFO.
- Theo cách tương tự, các nút gần nhất và chưa được truy cập còn lại trên biểu đồ được phân tích đánh dấu và thêm vào hàng đợi. Các mục này sẽ bị xóa khỏi hàng đợi khi nhận và in kết quả.
Tại sao chúng ta cần Thuật toán BFS?
Có nhiều lý do để sử dụng Breadth-First Search Algorithm khi bạn tìm kiếm tập dữ liệu. Một số khía cạnh quan trọng nhất khiến thuật toán này trở thành lựa chọn hàng đầu là:
- BFS rất hữu ích để phân tích các nút trong biểu đồ và xây dựng đường đi ngắn nhất để đi qua các nút này.
- BFS có thể duyệt qua một biểu đồ với số lần lặp nhỏ nhất.
- Kiến trúc của thuật toán BFS đơn giản và mạnh mẽ.
- Kết quả của thuật toán BFS có độ chính xác cao hơn so với các thuật toán khác.
- Các bước lặp BFS diễn ra liền mạch và không có khả năng thuật toán này vướng vào vấn đề vòng lặp vô hạn.
Thuật toán BFS hoạt động như thế nào?
Duyệt đồ thị yêu cầu thuật toán truy cập, kiểm tra và/hoặc cập nhật từng nút chưa được truy cập trong cấu trúc dạng cây. Các giao dịch duyệt đồ thị được phân loại theo thứ tự mà chúng truy cập vào các nút trên biểu đồ.
Thuật toán BFS bắt đầu hoạt động từ nút đầu tiên hoặc nút bắt đầu trong biểu đồ và duyệt qua nó một cách triệt để. Khi BFS thành công đi qua nút ban đầu, thì đỉnh không đi qua tiếp theo trong đồ thị sẽ được ghé thăm và đánh dấu.
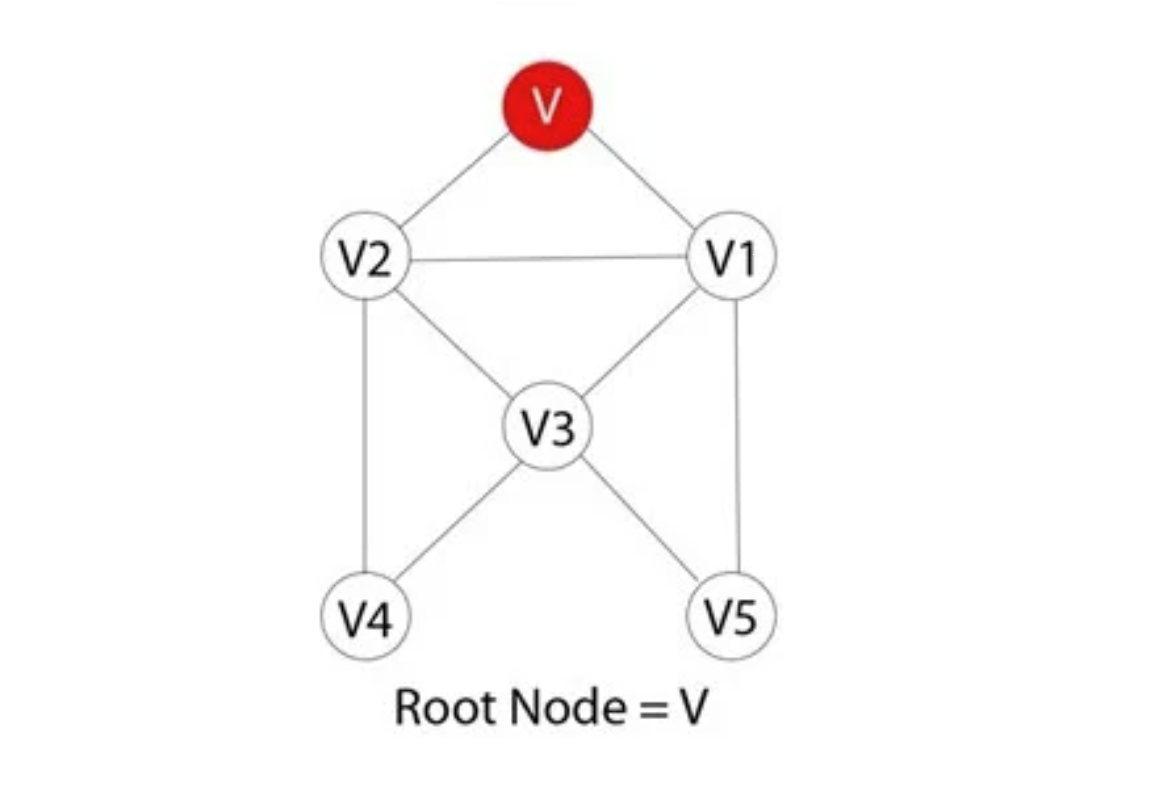
Do đó, bạn có thể nói rằng tất cả các nút liền kề với đỉnh hiện tại đều được thăm và duyệt trong lần lặp đầu tiên. Một phương pháp đơn giản được sử dụng để triển khai hoạt động của Breadth-First Search Algorithm gồm các bước sau:
Bước 1
Bước 2
Bước 3
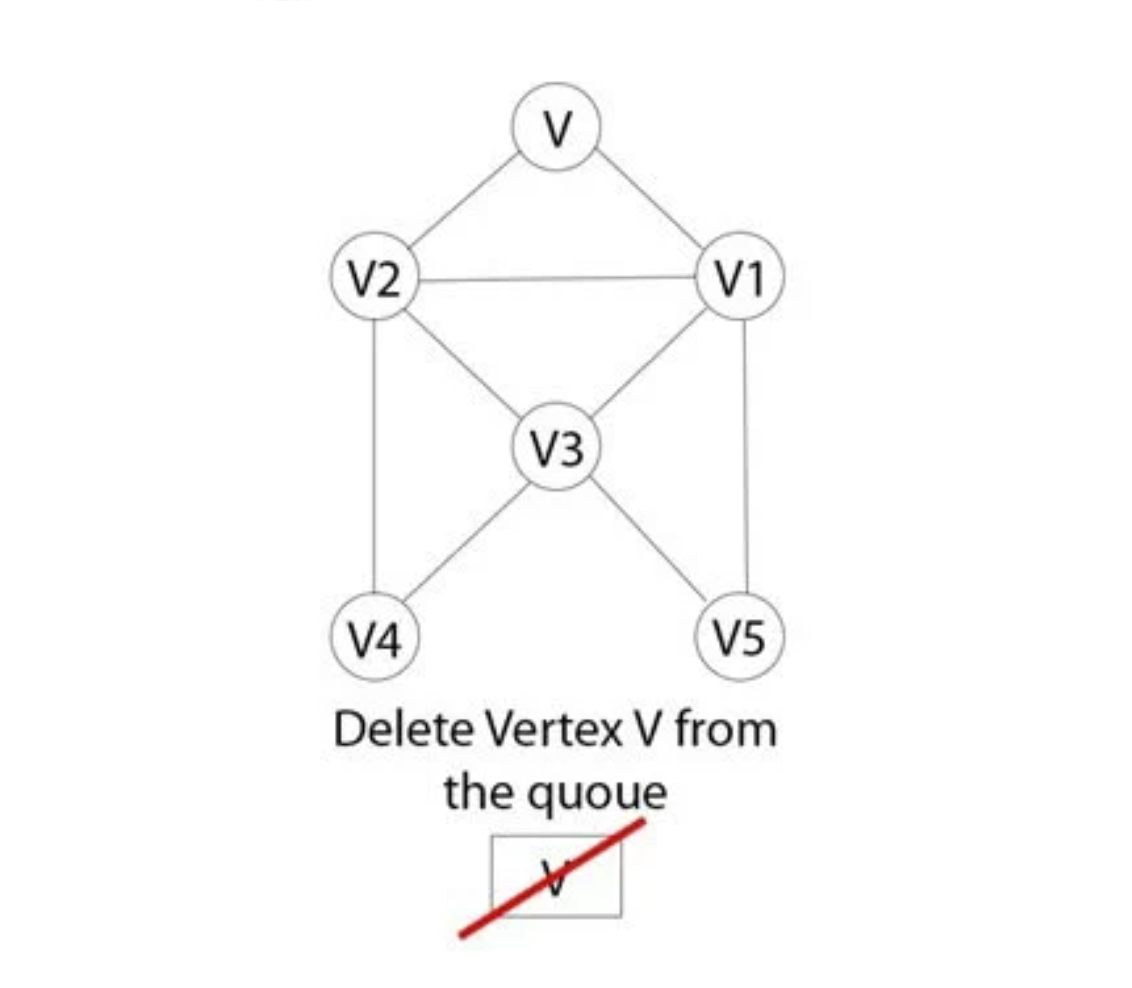
Bước 4
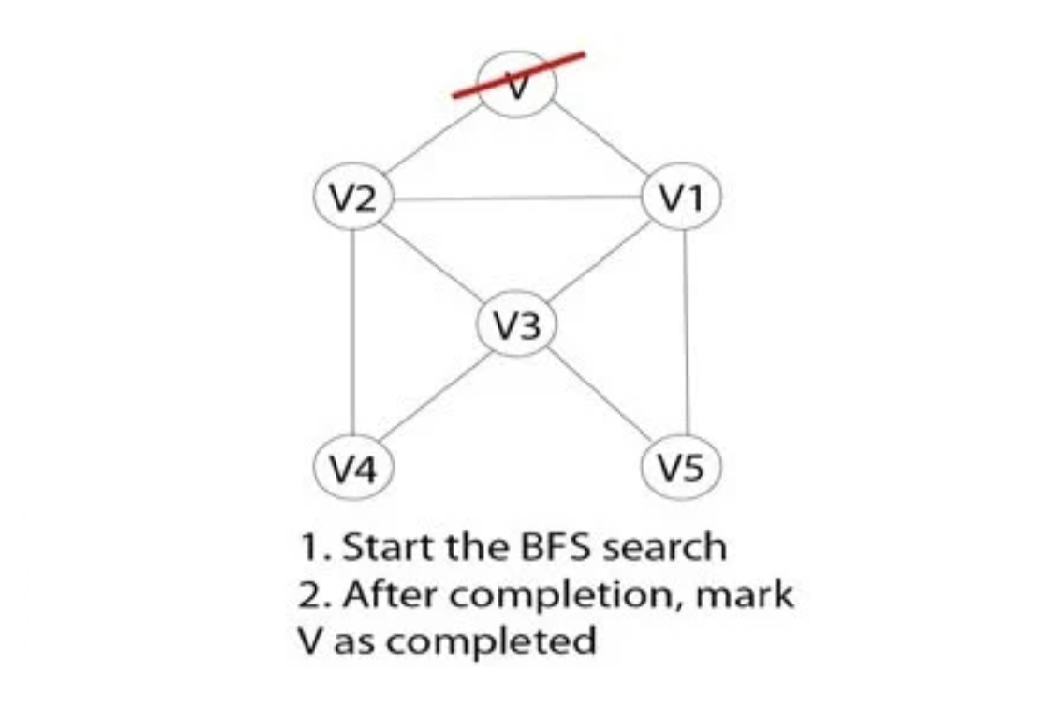
Bước 5
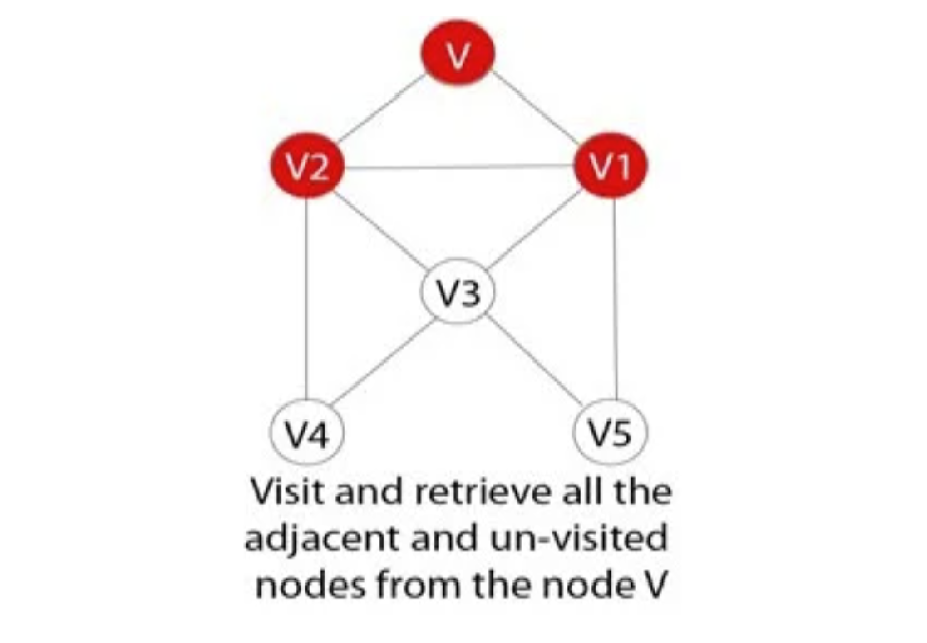
Bước 6
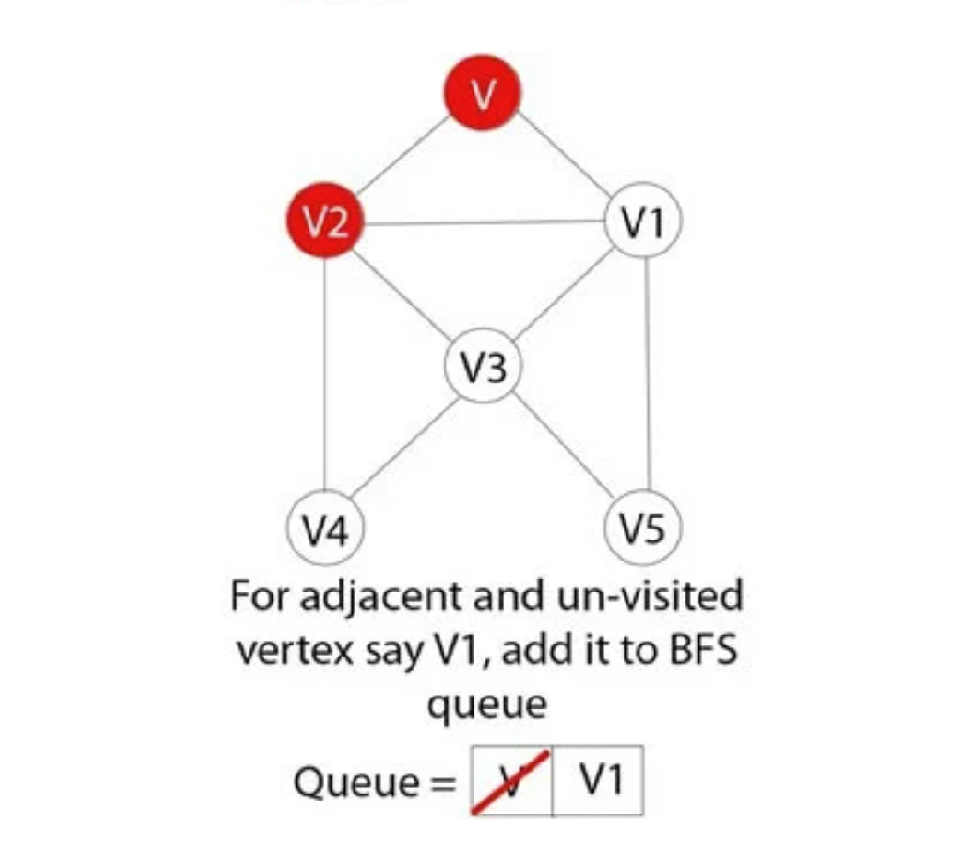
Bước 7
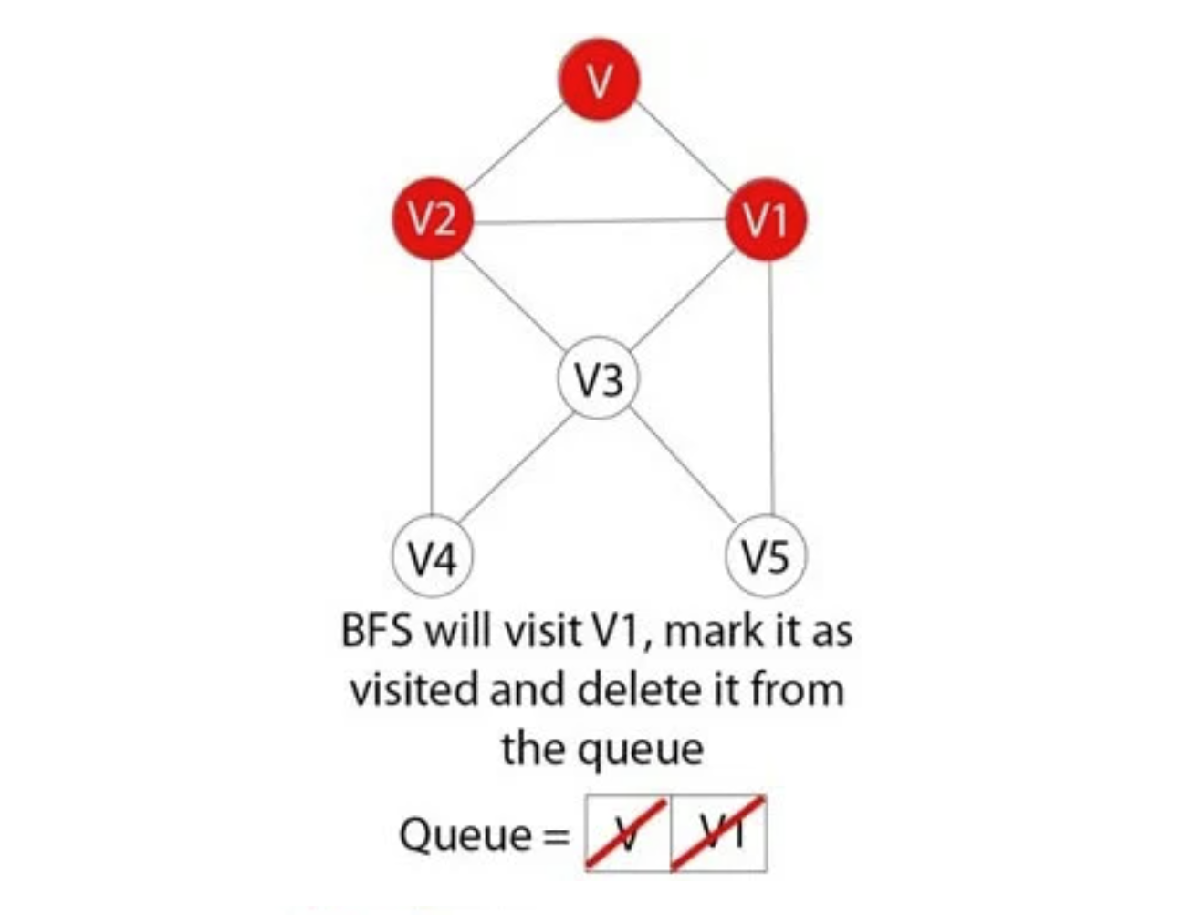
Quy tắc của thuật toán BFS
Dưới đây là các quy tắc quan trọng để sử dụng Breadth-First Search Algorithm:
- Cấu trúc dữ liệu hàng đợi (FIFO-First in First Out) được BFS sử dụng.
- Bạn có thể đánh dấu bất kỳ nút nào trong biểu đồ là gốc và bắt đầu duyệt dữ liệu từ nút đó.
- BFS đi qua tất cả các nút trong biểu đồ và tiếp tục loại bỏ chúng khi hoàn thành.
- BFS truy cập một nút chưa được truy cập liền kề, đánh dấu và chèn nó vào hàng đợi.
- Xóa đỉnh trước đó khỏi hàng đợi trong trường hợp không tìm thấy đỉnh liền kề.
- Thuật toán BFS lặp lại cho đến khi tất cả các đỉnh trong biểu đồ được duyệt thành công và được đánh dấu là đã hoàn thành.
- Không có vòng lặp nào do BFS gây ra trong quá trình duyệt dữ liệu từ bất kỳ nút nào.
Các ứng dụng của Breadth-First Search Algorithm
Đồ thị không trọng số (Un-weighted Graphs)
Thuật toán BFS có thể dễ dàng tạo ra đường đi ngắn nhất và cây bao trùm tối thiểu để thăm tất cả các đỉnh của đồ thị trong thời gian ngắn nhất có thể với độ chính xác cao.
Mạng P2P (P2P Networks)
BFS có thể được triển khai để định vị tất cả các nút gần nhất hoặc lân cận trong mạng ngang hàng. Điều này giúp tìm thấy dữ liệu cần thiết nhanh hơn.
Trình thu thập dữ liệu web (Web Crawlers)
Công cụ tìm kiếm hoặc trình thu thập dữ liệu web có thể dễ dàng xây dựng nhiều cấp chỉ mục bằng cách sử dụng BFS. Việc triển khai BFS bắt đầu từ nguồn, đó là trang web, sau đó nó truy cập tất cả các liên kết từ nguồn đó.
Hệ thống định vị (Navigation Systems)
BFS có thể giúp tìm tất cả các vị trí lân cận từ vị trí chính hoặc nguồn.
Sự khác biệt chính giữa BFS và DFS
DFS (Depth First Search) là một thuật toán để tìm hoặc duyệt các đồ thị hoặc cây theo hướng có chiều sâu. Việc thực hiện thuật toán bắt đầu tại nút gốc và khám phá từng nhánh trước khi quay lại. Nó sử dụng cấu trúc dữ liệu ngăn xếp để ghi nhớ, để lấy đỉnh tiếp theo và để bắt đầu tìm kiếm, bất cứ khi nào ngõ cụt xuất hiện trong bất kỳ lần lặp nào.
Sự khác biệt chính giữa hai thuật toán BFS và DFS là
- BFS tìm đường đi ngắn nhất đến đích, trong khi DFS đi đến cuối cây con, sau đó quay lại.
- Hình thức đầy đủ của BFS là Tìm kiếm theo chiều rộng, trong khi hình thức đầy đủ của DFS là Tìm kiếm theo chiều sâu.
- BFS sử dụng hàng đợi để theo dõi vị trí tiếp theo sẽ truy cập. Trong khi DFS sử dụng ngăn xếp để theo dõi vị trí tiếp theo sẽ truy cập.
- BFS di chuyển theo cấp độ cây, trong khi DFS di chuyển theo độ sâu của cây.
- BFS được triển khai bằng danh sách FIFO; mặt khác, DFS được triển khai bằng danh sách LIFO.
- Trong BFS, bạn không bao giờ có thể bị mắc kẹt trong các vòng lặp hữu hạn, trong khi ở DFS, bạn có thể bị mắc kẹt trong các vòng lặp vô hạn.
Tóm lại
- Duyệt đồ thị là một quy trình duy nhất yêu cầu thuật toán truy cập, kiểm tra và/hoặc cập nhật từng nút chưa được truy cập trong cấu trúc dạng cây. Breadth-First Search Algorithm hoạt động trên một nguyên tắc tương tự.
- Thuật toán rất hữu ích để phân tích các nút trong biểu đồ và xây dựng đường đi ngắn nhất để đi qua các nút này.
- Thuật toán đi qua đồ thị với số lần lặp nhỏ nhất và thời gian ngắn nhất có thể.
- BFS chọn một nút duy nhất (điểm ban đầu hoặc điểm nguồn) trong biểu đồ và sau đó truy cập tất cả các nút liền kề với nút đã chọn. BFS truy cập từng nút một.
- Dữ liệu đã truy cập và được đánh dấu được đặt trong hàng đợi bởi BFS. Hàng đợi hoạt động trên cơ sở vào trước ra trước. Do đó, phần tử được đặt trong biểu đồ đầu tiên sẽ bị xóa trước và kết quả là được in.
- Thuật toán BFS không bao giờ mắc vào vòng lặp vô hạn.
- Do độ chính xác cao và khả năng triển khai mạnh mẽ, BFS được sử dụng trong nhiều giải pháp thực tế như mạng P2P, Trình thu thập dữ liệu web và Phát sóng mạng.
Trong bài viết này, chúng ta đã thảo luận về thuật toán BFS và các ứng dụng thực tế của Breadth-First Search Algorithm cho thấy nó là thuật toán cấu trúc dữ liệu quan trọng. Đó là tất cả về bài viết. Hy vọng sẽ hữu ích và cung cấp thông tin cần thiết cho bạn.