Overfitting là gì? Làm thế nào để tránh overfitting
BÀI LIÊN QUAN
Machine Teaching là gì? Học máy và Dáy máy khác nhau như thế nào?Moral Machine là gì? Cách con người quyết định đạo đức của máy mócDịch máy là gì? Từ A - Z về Machine Translation dành cho bạnOverfitting là gì?
Overfitting là gì có lẽ một điều khó hiểu với dân kỹ thuật không chuyên. Đây là một khái niệm trong khoa học dữ liệu, xảy ra khi một mô hình thống kê khớp chính xác với dữ liệu được đào tạo của nó. Khi các nhà khoa học dữ liệu ứng dụng một số các mô hình học máy để từ đó đưa ra các dự đoán khác nhau, trước tiên họ tiến hành đào tạo mô hình dựa trên một tập các thông tin dữ liệu đã biết.
Sau đó, dựa trên thông tin này, mô hình sẽ cố gắng thực hiện việc dự đoán kết quả cho những tập thông tin dữ liệu mới. Overfitting có thể đưa ra những điều dự đoán không thực sự chính xác và không thể thực hiện được tốt cho tất cả những loại thông tin dữ liệu mới.
Khi các thuật toán máy học được thiết kế xây dựng, chúng tận dụng một tập dữ liệu mẫu để từ đó huấn luyện mô hình. Tuy nhiên, khi mô hình đào tạo quá lâu dựa trên dữ liệu mẫu hoặc khi mô hình diễn ra quá phức tạp, nó có thể bắt đầu tìm hiểu vấn đề bất ổn xảy ra ở đâu hoặc thông tin không liên quan trong tập dữ liệu. Khi mô hình ghi nhớ nhiễu và quá khớp với tập huấn luyện, mô hình sẽ trở nên “quá khớp” và không thể khái quát hóa tốt cho dữ liệu mới. Nếu một mô hình không thể khái quát hóa tốt dữ liệu mới, thì nó sẽ không thể thực hiện các nhiệm vụ phân loại hoặc dự đoán mà nó được dự định.
Tỷ lệ lỗi thấp và phương sai cao là những chỉ báo tốt về vấn đề trang bị quá khớp. Để ngăn chặn loại hành vi này, một phần của tập dữ liệu được đào tạo thường được dành riêng làm “tập kiểm tra” để kiểm tra xem có quá khớp hay không. Nếu dữ liệu đào tạo có tỷ lệ lỗi thấp và dữ liệu thử nghiệm có tỷ lệ lỗi cao, nó báo hiệu quá khớp.
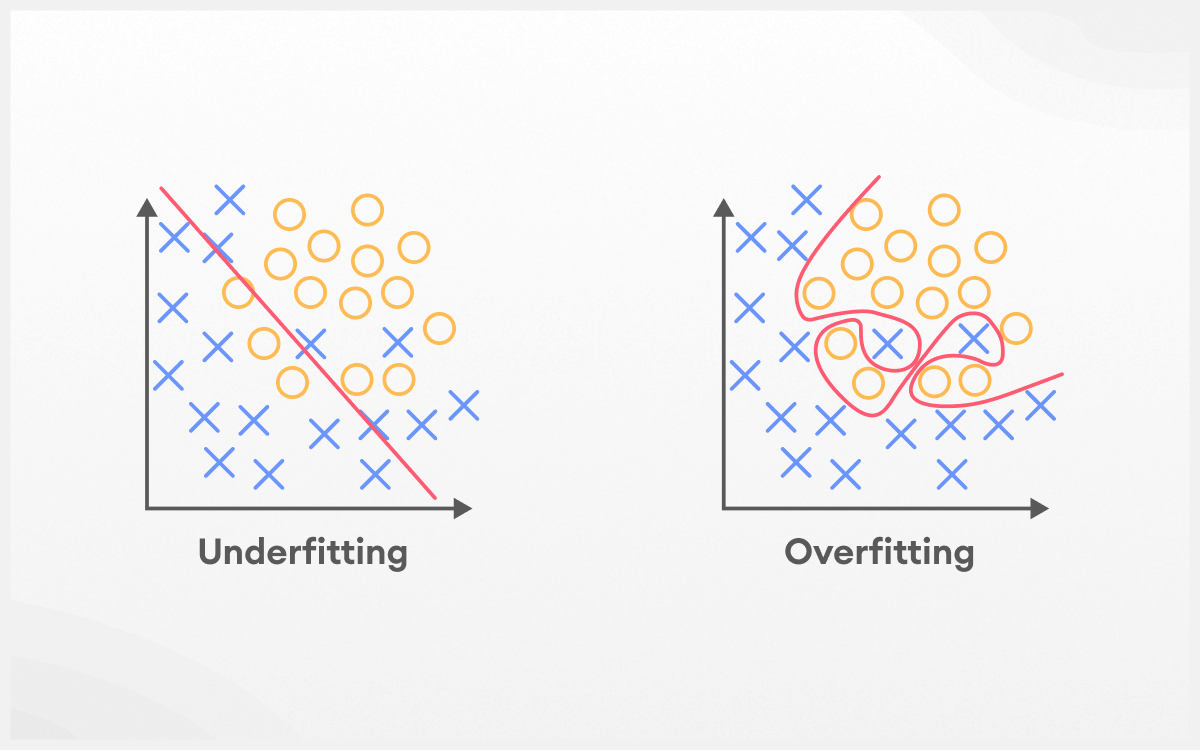
Tại sao hiện tượng Overfitting lại xảy ra?
Người dùng sẽ chỉ nhận được những dự đoán có tính chính xác cao nếu mô hình máy học có khả năng khái quát hóa tất cả những loại dữ liệu nằm ở trong phạm vi xử lý của nó. Hiện tượng quá khớp xảy ra khi mà mô hình học máy không thể thực hiện khái quát hóa mà thay vào đó, khớp quá sát với các tập thông tin dữ liệu đào tạo. Hiện tượng quá khớp có thể xảy ra bởi một số các nguyên nhân, khác nhau, chẳng hạn như:
- Kích thước của dữ liệu đào tạo quá nhỏ và không có chứa đầy đủ các mẫu dữ liệu để thể hiện một cách chính xác tất cả những giá trị dữ liệu đầu vào có tính khả thi.
- Dữ liệu đào tạo có chứa một lượng lớn các loại thông tin không liên quan đến nhau, chúng được gọi là các dữ liệu nhiễu.
- Mô hình đào tạo quá lâu trên một tập dữ liệu mẫu duy nhất.
- Do có độ phức tạp tương đối cao, mô hình học sẽ có cả những phần nhiễu trong dữ liệu đào tạo.
Làm thế nào để phát hiện Overfitting?
Gần như không thể phát hiện overfitting trước khi bạn kiểm tra dữ liệu. Nó có thể giúp giải quyết đặc điểm vốn có của việc trang bị quá khớp, đó là không có khả năng khái quát hóa các tập dữ liệu. Do đó, dữ liệu có thể được tách thành các tập hợp con khác nhau để dễ dàng huấn luyện và kiểm tra. Dữ liệu được chia thành hai phần chính, tức là tập kiểm tra và tập huấn luyện.
Đào tạo dữ liệu đại diện cho phần lớn dữ liệu có sẵn (khoảng 80%) và mô hình đào tạo. Tập kiểm tra đại diện cho một phần nhỏ của tập dữ liệu (khoảng 20%) và được sử dụng để kiểm tra độ chính xác của dữ liệu mà nó chưa từng tương tác trước đó. Bằng cách phân đoạn tập dữ liệu, chúng ta có thể kiểm tra hiệu suất của mô hình trên từng tập hợp dữ liệu để phát hiện hiện tượng quá khớp khi nó xảy ra, cũng như xem quy trình đào tạo hoạt động như thế nào.
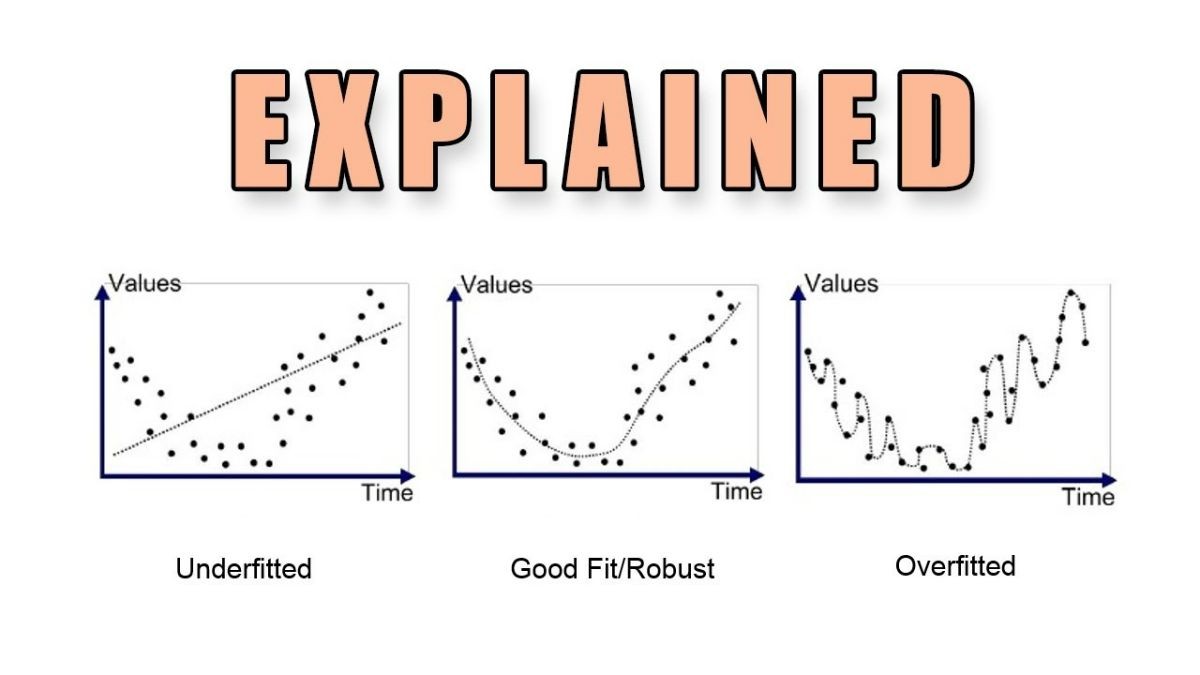
Hiệu suất có thể được đo lường bằng cách sử dụng tỷ lệ phần trăm độ chính xác quan sát được trong cả hai bộ dữ liệu để kết luận về sự hiện diện của trang bị thừa. Nếu mô hình hoạt động tốt hơn trên tập huấn luyện so với trên tập kiểm tra, điều đó có nghĩa là mô hình có khả năng bị quá khớp.
Làm thế nào để ngăn chặn Overfitting
Dưới đây là một số cách để ngăn chặn Overfitting:
Dừng sớm
Kỹ thuật dừng sớm sẽ tạm dừng giai đoạn đào tạo dữ liệu trước cả khi mô hình máy học học được thêm cả phần nhiễu có trong dữ liệu. Tuy nhiên, việc dừng đúng thời điểm là điều hết sức quan trọng, nếu không mô hình vẫn sẽ không thể đưa ra được những kết quả đúng chính xác.
Huấn luyện với nhiều dữ liệu hơn
Một trong những cách để ngăn chặn việc trang bị quá khớp là đào tạo với nhiều dữ liệu hơn. Tùy chọn này giúp các thuật toán dễ dàng phát hiện tín hiệu tốt hơn để giảm thiểu lỗi. Khi người dùng cung cấp thêm dữ liệu đào tạo vào mô hình, nó sẽ không thể khớp quá khớp tất cả các mẫu và sẽ buộc phải tổng quát hóa để thu được kết quả.
Người dùng nên liên tục thu thập thêm dữ liệu như một cách để tăng độ chính xác của mô hình. Tuy nhiên, phương pháp này được coi là tốn kém và do đó, người dùng nên đảm bảo rằng dữ liệu được sử dụng là phù hợp và rõ ràng.
Tăng cường dữ liệu
Một giải pháp thay thế cho việc đào tạo với nhiều dữ liệu hơn là tăng cường dữ liệu, cách này ít tốn kém hơn so với cách trước. Nếu bạn không thể liên tục thu thập thêm dữ liệu, bạn có thể làm cho các tập dữ liệu có sẵn trở nên đa dạng.
Tăng cường dữ liệu làm cho dữ liệu mẫu trông hơi khác mỗi khi được mô hình xử lý. Quá trình làm cho mỗi tập dữ liệu xuất hiện duy nhất cho mô hình và ngăn mô hình tìm hiểu các đặc điểm của tập dữ liệu.
Một tùy chọn khác hoạt động theo cách tương tự như tăng cường dữ liệu là thêm nhiễu vào dữ liệu đầu vào và đầu ra. Thêm nhiễu vào đầu vào giúp mô hình trở nên ổn định, không ảnh hưởng đến chất lượng dữ liệu và quyền riêng tư, trong khi thêm nhiễu vào đầu ra giúp dữ liệu đa dạng hơn. Tuy nhiên, việc thêm nhiễu cần được thực hiện một cách vừa phải để mức độ của nhiễu không quá nhiều làm cho dữ liệu bị sai lệch hoặc quá chênh lệch.
Đơn giản hóa dữ liệu
Việc khớp quá khớp có thể xảy ra do sự phức tạp của một mô hình, do đó, ngay cả với khối lượng dữ liệu lớn, mô hình vẫn có thể khớp quá khớp với tập dữ liệu huấn luyện. Phương pháp đơn giản hóa dữ liệu được sử dụng để giảm quá khớp bằng cách giảm độ phức tạp của mô hình để làm cho nó đủ đơn giản để không bị quá khớp.
Một số hành động có thể được thực hiện bao gồm cắt tỉa cây quyết định, giảm số lượng tham số trong mạng thần kinh và sử dụng tính năng bỏ học trên mạng trung tính. Đơn giản hóa mô hình cũng có thể làm cho mô hình nhẹ hơn và chạy nhanh hơn.
Tổng hợp
Tổng hợp là một kỹ thuật học máy hoạt động bằng cách kết hợp các dự đoán từ hai hoặc nhiều mô hình riêng biệt. Các phương pháp tập hợp phổ biến nhất bao gồm tăng cường và đóng bao.
Tăng cường hoạt động bằng cách sử dụng các mô hình cơ sở đơn giản để tăng độ phức tạp tổng hợp của chúng. Nó đào tạo một số lượng lớn những người học yếu kém được sắp xếp theo một trình tự, sao cho mỗi người học trong trình tự đó học hỏi từ những sai lầm của người học trước nó.
Tăng cường kết hợp tất cả những người học yếu trong chuỗi để đưa ra một người học mạnh. Phương pháp kết hợp khác là đóng bao, ngược lại với tăng tốc. Tính năng đóng gói hoạt động bằng cách đào tạo một số lượng lớn những người học giỏi được sắp xếp theo một mẫu song song và sau đó kết hợp chúng để tối ưu hóa các dự đoán của họ.
Xác thực chéo
Xác thực chéo là một biện pháp mạnh mẽ để ngăn chặn quá khớp. Bộ dữ liệu hoàn chỉnh được chia thành nhiều phần. Trong xác thực chéo K-fold tiêu chuẩn, chúng ta cần phân vùng dữ liệu thành k nếp gấp. Sau đó, chúng tôi huấn luyện lặp lại thuật toán trên k-1 nếp gấp trong khi sử dụng nếp gấp giữ lại còn lại làm tập kiểm tra. Phương pháp này cho phép chúng tôi điều chỉnh các siêu tham số của mạng thần kinh hoặc mô hình máy học và kiểm tra nó bằng cách sử dụng dữ liệu hoàn toàn không nhìn thấy được.
Thêm nhiễu vào dữ liệu đầu vào
Một tùy chọn tương tự khác khi tăng cường dữ liệu đó chính là thêm nhiễu vào dữ liệu đầu vào và đầu ra. Việc thêm nhiễu vào đầu vào giúp mô hình ổn định mà không ảnh hưởng đến chất lượng dữ liệu và quyền riêng tư trong khi thêm nhiễu vào đầu ra giúp dữ liệu đa dạng hơn. Việc bổ sung nhiễu nên được thực hiện trong giới hạn để không làm cho dữ liệu bị sai hoặc quá khác biệt.
Hiện tượng chưa khớp là gì?
Chưa khớp cũng là một dạng lỗi khác xảy ra khi mà mô hình không thể xác định mối quan hệ có ý nghĩa giữa dữ liệu đầu vào và đầu ra. Bạn có thể sẽ nhận được các mô hình chưa khớp nếu như chúng chưa được đào tạo dữ liệu đủ khoảng thời gian cần thiết ở trên một số lượng lớn những điểm dữ liệu.
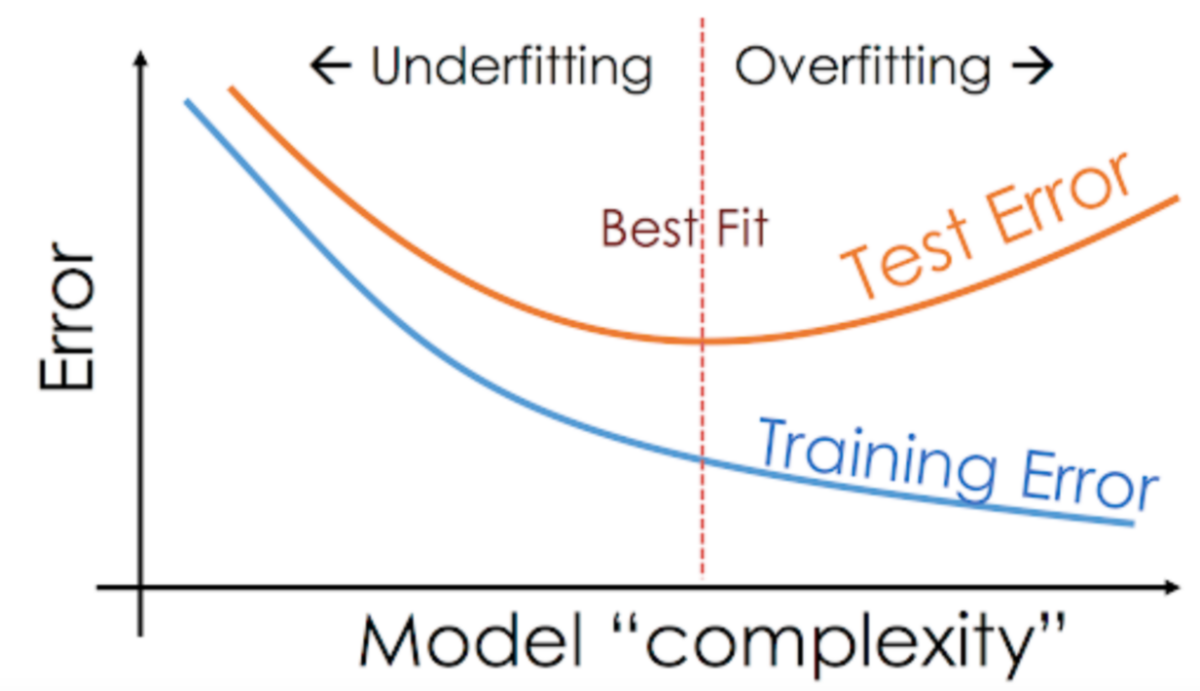
Chưa khớp so với quá khớp
Các mô hình chưa khớp có độ lệch khá cao, chúng sẽ đưa ra khá nhiều những kết quả thiếu chính xác cho cả tập dữ liệu đào tạo và tập dữ liệu kiểm thử. Mặt khác, các mô hình quá khớp có phương sai cao, chúng đưa ra kết quả chính xác cho tập dữ liệu đào tạo còn đối với tập kiểm thử thì không. Thêm các kết quả đào tạo mô hình với các độ lệch thấp hơn nhưng sẽ khiến cho phương sai có thể tăng. Các nhà khoa học dữ liệu hiện nay đang nhắm đến việc tìm ra được điểm cân bằng giữa mô hình chưa khớp và quá khớp khi thực hiện đào tạo mô hình. Một mô hình vừa khớp có thể nhanh chóng thiết lập ra được những xu hướng chính cho các tập dữ liệu đã được biết và chưa được biết.
Với nội dung trên đây bạn đã có thể hiểu được Overfitting là gì. Trong quá trình quản lý thông tin dữ liệu thì việc dữ liệu quá khớp là điều hoàn toàn có thể xảy ra.