“Phần mềm Apache Mahout là gì?” Thông tin cơ bản và ứng dụng trong xử lý dữ liệu mã nguồn mở
BÀI LIÊN QUAN
Data mining là gì? Những công cụ khai phá dữ liệu hiệu quảTìm hiểu về ứng dụng của khai phá dữ liệu trong các lĩnh vựcHiểu rõ hơn về classification trong data mining1. Apache Mahout là gì?
Apache Mahout là một dự án mã nguồn mở mới đang được phát triển bởi Apache Software Foundation (Viết tắt là ASF: Quỹ phần mềm Apache). Quỹ này được thành lập với mục tiêu chính là tạo các thuật toán học máy có khả năng mở rộng, đồng thời các thuật toán này đều được miễn phí sử dụng theo giấy phép của Apache. Dự án này đang bước vào năm thứ hai của mình, với bản phát hành công khai trong phạm vi nhà phát triển Apache. Công cụ này bao gồm các việc như: thực hiện để phân cụm, phân loại, CF và lập trình tiến hóa. Hơn nữa, Mahout còn khéo léo sử dụng thư viện Apache Hadoop để cho phép mở rộng hiệu quả trong đám mây này. Đặc điểm chính của Apache Mahout là gì? Chúng ta có thể xem các tóm gọn về phần mềm này như sau:
- Dự án này thuộc nền tảng phần mềm Apache.
- Được xem như một thư viện học máy khả năng mở rộng:
- Kết nối MapReduce, theo quy mô đường thẳng với dữ liệu
- Áp dụng thuật toán tuần tự nhanh (nghĩa là quá trình thi hành không phụ thuộc vào kích thước của tập dữ liệu)
- Lọc cộng tác: bao gồm các thuật toán phân nhóm, phân loại, và khuyến nghị.
- Thuật toán học máy có thể được thi hành theo tuần tự (in-memory mode) hoặc distributed mode (MapReduce được kích hoạt)
- Hầu hết các thuật toán trong Mahout đều được thực hiện bằng cách mô hình hóa MapReduce.
- Ứng dụng này được chạy trên nền tảng Hadoop cho việc mở rộng.
- Dữ liệu của Apache Mahout được lưu trữ trong HDFS (data storage) hoặc trong bộ nhớ.
- Đây thực chất là một thư viện Java (không có giao diện người dùng).
- Phiên bản mới nhất được cập nhật là 0.12.2.
- Bản chất là một thư viện dùng chung.

2. Lịch sử hình thành Apache Mahout
Dự án Mahout được bắt đầu bởi một số người tham gia vào cộng đồng Apache Lucene. Ban đầu, cộng đồng này có một sự quan tâm tích cực trong lĩnh vực học máy và mong muốn về một không gian lưu trữ mạnh mẽ, có đầy đủ các tài liệu cần thiết. Đồng thời, có khả năng mở rộng của các thuật toán học máy phổ biến cho việc phân cụm và phân loại. Thuật toán này ban đầu được gọi là "Map-Reduce for Machine Learning on Multicore", nghĩa là Map-Reduce cho học máy theo đa lõi. Nhưng về sau dần dà phát triển để trình bày các cách tiếp cận học máy rộng hơn. Mahout ra đời cũng nhằm mục đích:
- Xây dựng và hỗ trợ một cộng đồng những người dùng và những người đóng góp. Sao cho mã này vượt trên bất kỳ tác động nào của người đóng góp cụ thể, bất kỳ công ty, hoặc quỹ tài trợ nào. Tập trung vào áp dụng thực tế trong thế giới thực, không chỉ đơn thuần dừng lại ở việc nghiên cứu các kỹ thuật mới.
- Cung cấp các nguồn tài liệu và ví dụ chất lượng.

3. Các đặc tính của Apache Mahout là gì?
Mặc dù Apache Mahout tương đối mới trong thuật ngữ mã nguồn mở, phần mềm này cũng đã có một số lượng lớn các chức năng, đặc biệt liên quan đến việc phân cụm và lọc cộng tác. Các đặc tính chính của Mahout có thể kể đến là:
- Taste CF. Taste: là một dự án mã nguồn mở cho CF, được khởi đầu bởi Sean Owen trên SourceForge. Đến năm 2008 được tặng cho Mahout.
- Một số việc thực hiện phân cụm của Mapreduce có sẵn, bao gồm k-Means, fuzzy k-Means, Canopy, Dirichlet và Mean-Shift.
- Có thể thực hiện phân loại Naive Bayes phân tán và Naive Bayes phụ.
- Tự động phân phối các hàm chức năng phù hợp cho công việc lập trình.
- Bản chất là thư viện ma trận và vectơ.

4. Ứng dụng của Apache Mahout là gì?
Nên sử dụng Apache Mahout khi phát sinh một trong những nhu cầu bên dưới:
- Bạn đang tìm kiếm một thuật toán học máy cho ngành công nghiệp, dùng hiệu năng như một yếu tố đánh giá quan trọng.
- Bạn đang tìm kiếm một giải pháp mã nguồn mở và được sử dụng miễn phí.
- Các tập dữ liệu ngày càng lớn và phát triển với tốc độ đáng báo động thì bạn nên sử dụng Mahour.
- Phát sinh nhu cầu xử lý dữ liệu hàng loạt với xử lý dữ liệu thời gian thực.
- Mong muốn tìm kiếm một thư viện hoàn chỉnh.

5. Bộ công cụ khuyến nghị với Apache Mahout
Hệ thống khuyến nghị là kỹ thuật cung cấp những gợi ý về một sản phẩm, dịch vụ nào đó đang có nhu cầu được sử dụng trên internet. Những gợi ý này được cung cấp nhằm hỗ trợ người sử dụng trong quá trình ra quyết định lựa chọn sản phẩm, dịch vụ đó. Ví dụ như những sách nào người dùng muốn mua? Những bài hát nào người dùng thích nghe? hoặc những tin tức nào người dùng muốn đọc? Một vài ứng dụng nổi tiếng về hệ thống khuyến nghị này cũng đang được sử dụng như: khuyến nghị sản phầm của Amazon.com hệ tư vấn phim của NetFlix… Hệ thống khuyến nghị đã chứng minh được lợi ích giúp cho người sử dụng trực tuyến đối phó với tình trạng quá tải thông tin.
Mahout hiện đang cung cấp các công cụ để xây dựng một máy bình luận thông qua các thư viện Taste. Đây là một máy nhanh và linh hoạt cho quá trình Lọc cộng tác. Taste hỗ trợ gợi ý bình luận cho người dùng, đi kèm với nhiều sự lựa chọn xây dựng các bình luận, cũng như các giao diện riêng tuỳ theo mục đích. Taste gồm năm thành phần chính để làm việc với User (người dùng), Item (các mục) và Preference (ratings):
- Data Model: Dùng để lưu trữ cho các User, các Item, và các Preference.
- User Similarity: Giao diện này giúp định nghĩa sự tương tác giữa hai người dùng.
- Item Similarity: Giao diện định nghĩa sự tương tác giữa hai mục khác nhau.
- Recommender: Giao diện nhằm cung cấp các bình luận.
- User Neighborhood: Giao diện để tính toán một vùng lân cận của những người dùng tương tự có thể được những người bình luận sử dụng.
Các thành phần này cùng với tác dụng riêng của chúng giúp cho phần mềm apache mahout có thể xây dựng các hệ thống bình luận phức tạp, hoặc các bình luận dựa trên thời gian thực. Thậm chí là các bình luận ngoại tuyến. Các bình luận dựa trên thời gian thực thường có thể làm việc với vài nghìn người dùng cùng lúc. Trong khi các bình luận ngoại tuyến có thể mở rộng lớn hơn rất nhiều. Ngoài ra, khi Taste đi kèm với các công cụ có sử dụng Hadoop thì có thể tính toán được số liệu các bình luận ngoại tuyến. Trong nhiều trường hợp, đây là một tiếp cận hợp lý để cho phép bạn đáp ứng các yêu cầu của một hệ thống lớn có lượt người dùng quá cao, các mục và ratings.
Mối quan hệ giữa các thành phần trong xây dựng hệ thống bình luận dựa trên người dùng trên Mahout có thể được diễn giải chi tiết như sau:
- Recommender: Là phần cốt lõi trong việc xây dựng hệ thống khuyến nghị. Từ data model có thể tạo ra hệ thống khuyến nghị.
- Mô hình dữ liệu (Data Model): Đây là giao diện với thống kê những thông tin về sở thích của người dùng. Có thể thực hiện một số bài phóng sự thực tế để rút ra được dữ liệu này từ bất kỳ nguồn nào.
- User Similarity: Đây là một giao diện thể hiện sự tương tác giữa hai người dùng. Đồng thời, đây cũng là một phần quan trọng trong hệ thống khuyến nghị. Nó được gắn kèm khi User Neighborhood thực hiện.
- User Neighborhood: Trong hệ thống khuyến nghị dựa trên người dùng, hệ thống được tạo ra bằng cách tính toán những vùng lân cận (Neighborhood) của một người dùng này với người dùng khác.
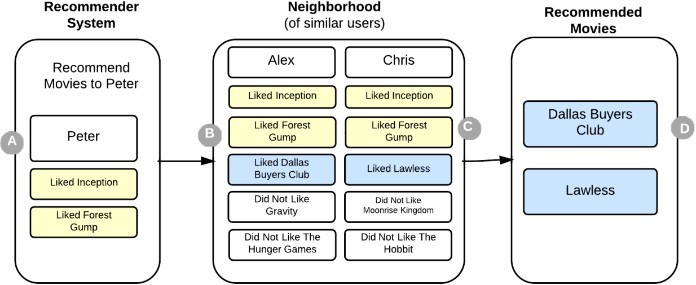
Trên đây là thông tin cơ bản về phần mềm Apache Mahout. Qua bài viết trên, các bạn đã hiểu được khái niệm Apache Mahout là gì và các thông tin cơ bản về đặc tính và ứng dụng của phần mềm này. Đồng thời, cũng hiểu được bản chất cách thức vận hành của bộ công cụ khuyến nghị Apache Mahout.