Hiểu rõ hơn về classification trong data mining
BÀI LIÊN QUAN
Anomaly detection là gì? Các ưu nhược điểm khi sử dụng anomaly detecrionHệ thống clustering là gì? Ứng dụng trong quản lý cơ sở dữ liệuRegression Analysis là gì? Ý nghĩa, phân loại và ví dụ cụ thểĐịnh nghĩa về Data Mining và Classification
Khai thác dữ liệu (Data Mining): Khai thác dữ liệu có nghĩa là khai thác hay đào sâu vào các dữ liệu ở những dạng khác nhau để sở hữu được các mẫu và còn có được kiến thức về mẫu đó. Trong suốt quá trình khai thác dữ liệu, những tệp dữ liệu lớn trước hết sẽ được sắp xếp và sau đó các mẫu được xác định những mối quan hệ được thiết lập để thực hiện phân tích dữ liệu và giải quyết các vấn đề.
Phân loại (Classification): Đây là 1 nhiệm vụ Phân tích dữ liệu, có nghĩa là quá trình tìm kiếm 1 mô hình mô tả và nhận biết các lớp và khái niệm về dữ liệu. Phân loại là vấn đề xác định tập hợp những danh mục (hay quần thể con), 1 dữ liệu quan sát mới thuộc về những loại nào, dựa trên cơ sở 1 tập dữ liệu huấn luyện có chứa các quan sát và các loại thành viên như đã biết.

Tại sao cần phải phân loại dữ liệu?
Dữ liệu chính là 1 kho tàng tài nguyên khổng lồ của một doanh nghiệp. Bởi vì có rất nhiều dữ liệu nếu như mà không được sắp xếp phân nhóm thì sẽ dễ bị mất và phải mất rất nhiều thời gian cho việc tìm kiếm hoặc thực hiện mã hóa Encryption và việc sử dụng sau này.
Bên cạnh đấy, việc thực hiện phân loại dữ liệu còn giúp cho doanh nghiệp dễ dàng quản lý hệ thống dữ liệu tránh việc thất thoát. Từ đó tiết kiệm được chi phí đáng kể cho những giải pháp Data Loss Prevention trong tương lai.

Sau đây là những lợi ích mà việc phân loại dữ liệu mang lại:
- Xác định được những loại data có giá trị trong các tổ chức, doanh nghiệp.
- Việc phân loại rõ ràng và cụ thể dữ liệu này sẽ giúp cho việc lựa chọn giải pháp bảo vệ những dữ liệu được nhanh chóng và phù hợp hơn
- Dữ liệu phân loại rõ ràng sẽ giúp cho các doanh nghiệp và tổ chức dựa vào đó để thiết lập các hệ thống phân quyền truy cập cho cá nhân, từ đấy sẽ tạo ra được hiệu quả trong việc sử dụng các dữ liệu.
- Việc tiến hành phân loại dữ liệu sẽ thể hiện được sự chuyên nghiệp của tổ chức, doanh nghiệp trong việc bảo vệ hệ thống tài nguyên dữ liệu có giá trị của khách hàng và ngay cả chính doanh nghiệp.
Tiêu chí giúp cho quá trình phân loại dữ liệu – classification trở nên dễ dàng
Phân loại data nghe thì đơn giản nhưng thật ra lại rất phức tạp nếu như không tìm ra được một quá trình phân loại cụ thể cũng như các tiêu chí kèm theo.
Dưới đây là các tiêu chí sẽ giúp cho quá trình classification dễ dàng và thuận tiện hơn:
- Thời gian, thời hạn của dữ liệu;
- Tính hữu dụng của từng loại dữ liệu;
- Giá trị của dữ liệu;
- Mức độ ảnh hưởng của thiệt hại khi bị rò rỉ, đánh mất hay bị đánh cắp;
- Người giám sát và bảo quản dữ liệu;
- Vị trí lưu trữ và phương pháp lưu trữ;
- Người có quyền và không có quyền đối với dữ liệu.
Các bước tiến hành thực hiện classification
Để cho việc phân loại dữ liệu trở nên hiệu quả và nhanh chóng hơn cần phải tuân thủ theo 1 quy trình nhất định như sau:
Bước 1: Cần xác định ai là người bảo vệ có trách nhiệm với data.
Bước 2: Đề ra những tiêu chí, yếu tố để phân loại
Bước 3: Tiến hành phân loại và dán nhãn cho mỗi loại data
Bước 4: Ghi nhận những trường hợp khác không nằm trong tiêu chí, tiến hành bổ sung thêm vào bộ tiêu chí
Bước 5: Sau khi kết thúc, chọn lựa những phương thức để bảo vệ dữ liệu cho phù hợp
Bước 6: Quy trình chuyển dữ liệu cho những đối tượng có trách nhiệm
Bước 7: Xây dựng chương trình tập huấn data classification cho tổ chức.
Các hình thức phân loại classification
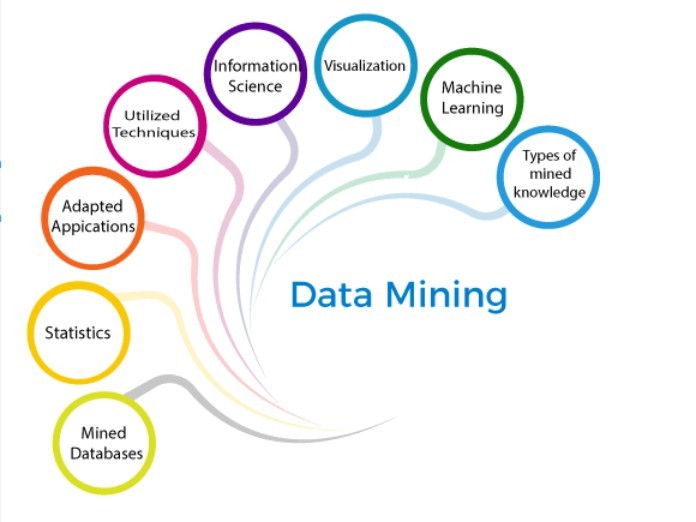
Để hiểu thêm về hệ thống và đáp ứng được các yêu cầu mong muốn, data mining sẽ có thể được Classification thành các hệ thống sau:
-
Classification dựa trên các cơ sở dữ liệu đã khai thác
-
Classification dựa trên loại kiến thức được khai thác
-
Classification dựa trên các số liệu thống kê
-
Classification dựa trên học máy
-
Classification dựa trên trực quan
-
Classification dựa trên khoa học - thông tin
-
Classification dựa trên các kỹ thuật được sử dụng
-
Classification dựa trên các ứng dụng đã điều chỉnh
-
Classification dựa trên cơ sở dữ liệu đã khai thác
Một hệ thống data mining sẽ được Classification dựa trên các loại cơ sở dữ liệu đã được khai thác. Một hệ thống cơ sở dữ liệu có thể được phân đoạn sâu hơn dựa trên những nguyên tắc riêng biệt, ví dụ như kiểu dữ liệu, mô hình dữ liệu, v.v., hỗ trợ thêm cho Classification hệ thống khai thác dữ liệu.
Phân tích một số hình thức phân loại Classification
Nếu bạn muốn Classification cơ sở dữ liệu dựa trên các mô hình dữ liệu, thì cần chọn hệ thống khai thác quan hệ, giao dịch hoặc kho dữ liệu. Chúng ta hãy cùng phân tích chi tiết một số hình thức phân loại Classification dưới đây.
Classification dựa trên loại kiến thức được khai thác
Một hệ thống khai thác dữ liệu được Classification dựa trên các loại trí tuệ tri thức có các chức năng sau:
-
Đặc tính hóa
-
Phân biệt
-
Phân tích sự liên kết và tương quan
-
Classification
-
Sự dự đoán
-
Phân tích ngoại lệ
-
Phân tích sự tiến hóa
Classification dựa trên kỹ thuật được sử dụng
Một hệ thống khai thác dữ liệu sẽ được Classification dựa trên các loại kỹ thuật đang được kết hợp. Các kỹ thuật này được đánh giá dựa trên mức độ tương tác của người dùng có liên quan hoặc những phương pháp phân tích được sử dụng.

Classification dựa trên ứng dụng đã điều chỉnh
Các hệ thống khai thác dữ liệu sẽ được Classification dựa trên các ứng dụng được điều chỉnh phù hợp như sau:
- Tài chính
- Viễn thông
- DNA
- Thị trường chứng khoán
Các phương án tích hợp của hệ thống Database và Data warehouse
No Coupling
Trong No Coupling hệ thống data mining không sử dụng bất cứ chức năng nào của hệ thống kho dữ liệu hoặc cơ sở dữ liệu.
Loose Coupling
Trong Loose Coupling, data mining sẽ sử dụng một số chức năng của hệ thống cơ sở dữ liệu hay kho dữ liệu. Dữ liệu ở đây sẽ được lấy chủ yếu từ kho dữ liệu và được quản lý bởi các hệ thống này. Sau đó thực hiện bước data mining, kết quả sẽ được lưu trong tệp hoặc ở bất kỳ nơi nào được chỉ định trong kho dữ liệu hoặc cơ sở dữ liệu.
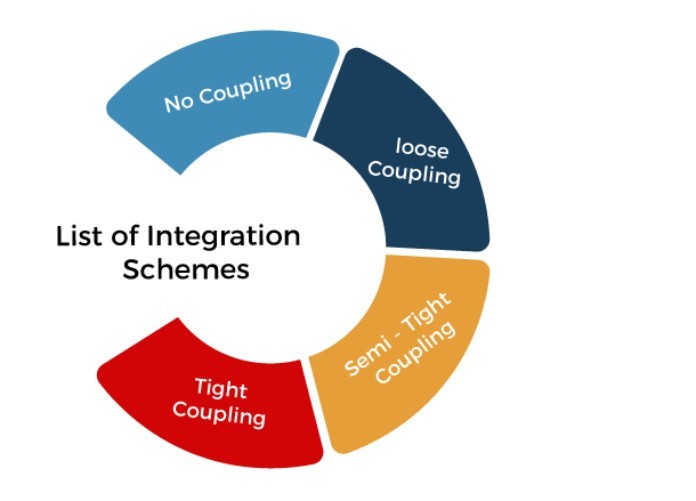
Semi-Tight Coupling
Trong Semi-Tight Coupling, data mining được liên kết với hệ thống DW hoặc DB và cung cấp triển khai hiệu quả những nguyên thủy data mining trong cơ sở dữ liệu hoặc kho dữ liệu.
Tight Coupling
Một hệ thống data mining có thể được kết hợp một cách dễ dàng với hệ thống cơ sở dữ liệu hoặc kho dữ liệu trong Tight Coupling.
Các yêu cầu đối với dữ liệu sau khi phân loại
Dữ liệu sau khi đã phân nhóm để đảm bảo tính khả dụng thì cần đáp ứng đầy đủ các yếu tố sau:
- Dữ liệu phải có tính minh bạch, rõ ràng và phù hợp với luật lệ.
- Đảm bảo được tính chính xác của dữ liệu.
- Thông tin của dữ liệu phải là những thông tin cần thiết và phục vụ cho công việc.
Ứng dụng của Classification trong thực tiễn
Sau đây là một số ứng dụng thực tiễn của Classification trong đời sống hàng ngày:
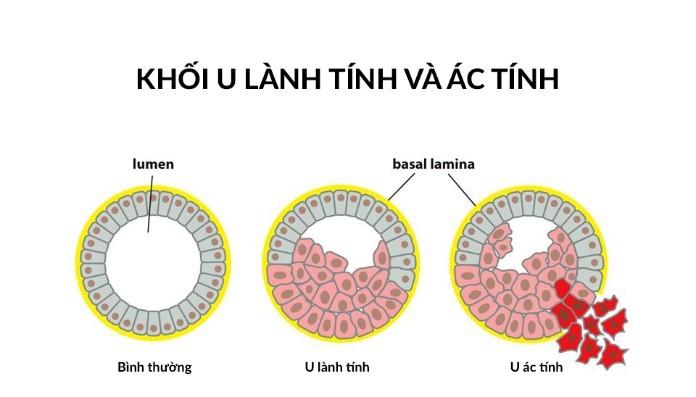
- Classification giúp xác định được các tế bào khối u là lành tính hay ác tính.
- Classification phát hiện các giao dịch thẻ tín dụng là hợp pháp hay gian lận.
- Classification có cấu trúc bậc hai của protein như các chuỗi xoắn alpha, tấm beta hay cuộn dây ngẫu nhiên.
- Classification tin bài thành những danh mục riêng biệt như thời tiết, giải trí, tài chính, thể thao, v.v.
Phân loại dữ liệu là công việc cần thiết tại bất kỳ cơ quan tổ chức nào. Hiệu quả của quá trình classification trong data mining sẽ giúp cho bộ máy của doanh nghiệp hoạt động thông suốt và việc sử dụng dữ liệu để phục vụ cho công việc sẽ trở nên dễ dàng hơn bao giờ hết.