Kiến trúc dữ liệu lớn là gì? Thành phần của kiến trúc dữ liệu lớn?
BÀI LIÊN QUAN
Kiến trúc dữ liệu lớn là gì? Thành phần của kiến trúc dữ liệu lớn?Tìm hiểu về các tài liệu học Big data và lộ trình học cơ bảnTìm hiểu những ứng dụng Big Data trong kinh doanhKiến trúc dữ liệu lớn là gì?

Kiến trúc dữ liệu lớn là nền tảng cho việc phân tích dữ liệu lớn. Đây là hệ thống bao quát được sử dụng để quản lý một lượng lớn dữ liệu để nó có thể được phân tích cho các mục đích kinh doanh, chỉ đạo phân tích dữ liệu và cung cấp một môi trường trong đó các công cụ phân tích dữ liệu lớn có thể trích xuất thông tin kinh doanh quan trọng từ những dữ liệu không rõ ràng khác.
Khung kiến trúc dữ liệu lớn đóng vai trò là bản thiết kế tham chiếu cho cơ sở hạ tầng và giải pháp dữ liệu lớn, xác định một cách hợp lý cách các giải pháp dữ liệu lớn sẽ hoạt động, các thành phần sẽ được sử dụng, cách thông tin sẽ lưu chuyển và các chi tiết bảo mật.
Các giải pháp dữ liệu lớn thường liên quan đến một hoặc nhiều loại khối lượng công việc sau:
+ Xử lý hàng loạt các nguồn dữ liệu lớn ở trạng thái còn lại.
+ Xử lý dữ liệu lớn đang chuyển động theo thời gian thực.
+ Khám phá tương tác dữ liệu lớn.
+ Phân tích dự đoán và học máy.
Thành phần của kiến trúc dữ liệu lớn
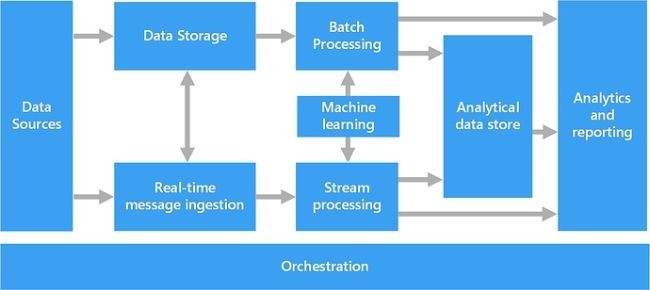
Để triển khai một giải pháp dữ liệu lớn, thì kiến trúc của nó thường bao gồm các thành phần (một số hoặc là tất cả):
Data Sources (Dữ liệu nguồn) Là nơi dữ liệu được sinh ra, gồm dữ liệu có cấu trúc (structure), dữ liệu phi cấu trúc (un-structure) và dữ liệu bán cấu trúc (semi-structure). Dữ liệu có thể đến từ nhiều nguồn khác nhau như là dữ liệu từ các ứng dụng, cơ sở dữ liệu quan hệ (giao dịch mua hay bán hàng từ một hệ thống bán lẻ, giao dịch gửi tiền vào ngân hàng, v.v…), hoặc là dữ liệu file được tạo ra bởi các log của ứng dụng (hay dữ liệu log ghi lại thời gian xử lý của hệ thống, …), hay như dữ liệu thời gian thực từ các thiết bị IoT (hình ảnh theo dõi từ camera, cảm biến nhiệt độ, độ ẩm, v.v….)
Data Storage (nơi lưu trữ dữ liệu): Được thiết kế để lưu trữ lại khối lượng rất lớn các loại dữ liệu với những định dạng khác nhau được sinh ra bởi dữ liệu nguồn (Data Source) ở trong mô hình xử lý dữ liệu theo lô (Batch Processing).
Hiện nay, trong Hadoop hay những giải pháp dữ liệu lớn khác, mô hình được triển khai phổ biến nhất cho thành phần Data Storage này đó là các hệ thống lưu trữ dữ liệu dạng file phân tán trên nhiều node khác nhau ở trong 1 cụm cluster, nhằm để đảm bảo cho khả năng xử liệu rất lớn và an toàn (replica). Apache Hadoop HDFS ( HDFS : Hadoop distributed file system ) đang sử dụng phổ biến để implement thành phần này trong các hệ thống Big Data.
Batch Processing (Xử lý dữ liệu theo lô): Đây là thành phần cho phép xử lý một lượng lớn dữ liệu thông qua việc đọc dữ liệu từ những file nguồn, lọc dữ liệu theo những điều kiện nhất định, tính toán trên dữ liệu, và ghi kết quả xuống 1 file đích. Trong thành phần này bạn có thể sử dụng Spark, Hive, MapReduce, v.v… với nhiều ngôn ngữ lập trình khác nhau như là Java, Scala hoặc Python.
Real-time Message Ingestion (Thu thập dữ liệu thời gian thực): Như đã nói trên, dữ liệu được sinh ra từ nguồn (Data Source) có thể gồm dữ liệu thời gian thực (ví dụ như từ các thiết bị IoT) do vậy thành phần này cho phép một hệ thống Big Data có thể thu thập và lưu trữ những loại dữ liệu trong thời gian thực phục vụ cho việc xử lý dữ liệu theo luồng (Streaming Processing).
Công nghệ phổ biến nhất chắc các bạn hay nghe đến đó là Kafka, ngoài ra còn có những cái tên khác như RabbitMQ, ActiveMQ,…
Stream Processing (Xử lý dữ liệu theo luồng ): Tương tự như xử lý dữ liệu theo lô (Batch Processing), sau khi thu thập dữ liệu thời gian thực, dữ liệu cũng cần được lọc theo các điều kiện nhất định, tính toán trên dữ liệu, và ghi kết quả dữ liệu sau khi đã được xử lý. Chúng ta có thể nhắc đến như Apache Storm, Spark Streaming,…
Analytical Data Store (Nơi lưu trữ dữ liệu phân tích): Chịu trách nhiệm lưu trữ dữ liệu đã được xử lý theo định dạng có cấu trúc để giúp phục vụ cho những công cụ phân tích dữ liệu (BI Tools). Dữ liệu có thể lưu trữ dưới dạng OLAP trong thiết kế Kimball hay còn có tên khác đó là "Star Schema - Mô hình dữ liệu lược đồ hình sao" (dành cho bạn nào chưa biết thì Kimball là một trong ba phương pháp luận khi thiết kế 1 data warehouse: Inmon, Kimball và Data Vault) hoặc là dữ liệu có thể lưu trữ bằng các công nghệ NoQuery như là HBase, Cassandra, …
Analysis and Reporting (Phân tích và báo cáo): Đây là thành phần đáp ứng việc tự khai thác dữ liệu data self-service. Cho phép người dùng cuối trực quan hóa dữ liệu (data visualization), phân tích dữ liệu và kết xuất các báo cáo khác nhau.
Công nghệ được sử dụng ở tầng này khá là đa dạng, có thể là các open source tool như D3.JS, Dygaphs, v.v… đến những công cụ commercial như Tableau, Power BI,…, hay bạn có thể tự code bằng các ngôn ngữ như Python, R, …
Orchestration (Điều phối): Thành phần này có nhiệm vụ điều phối những công việc trong một hệ thống Big Data để giúp đảm bảo luồng xử lý dữ liệu được thông suốt, từ việc thu thập dữ liệu, lưu trữ dữ liệu đến lọc và tính toán trên dữ liệu. Apache Oozie, Airflow, v.v…
Cách xây dựng kiến trúc dữ liệu lớn

Thiết kế kiến trúc dữ liệu lớn, tuy phức tạp, nhưng cần tuân theo cùng một quy trình chung:
Phân tích vấn đề: Đầu tiên xác định xem doanh nghiệp có thực sự gặp vấn đề về dữ liệu lớn hay không, xem xét các tiêu chí như đa dạng dữ liệu, tốc độ và thách thức với hệ thống hiện tại. Các trường hợp sử dụng phổ biến bao gồm lưu trữ dữ liệu, giảm tải quy trình, triển khai hồ dữ liệu, xử lý dữ liệu phi cấu trúc và hiện đại hóa kho dữ liệu.
Chọn nhà cung cấp: Hadoop là một trong những công cụ kiến trúc dữ liệu lớn được công nhận rộng rãi nhất để quản lý kiến trúc đầu cuối cho dữ liệu lớn. Các nhà cung cấp phổ biến để phân phối Hadoop bao gồm Amazon Web Services, BigInsights, Cloudera, Hortonworks, Mapr và Microsoft.
Chiến lược triển khai: Việc triển khai có thể là tại chỗ, có xu hướng an toàn hơn; dựa trên đám mây, hiệu quả về chi phí và cung cấp tính linh hoạt về khả năng mở rộng; hoặc một chiến lược triển khai hỗn hợp.
Lập kế hoạch năng lực: Khi lập kế hoạch định cỡ phần cứng và cơ sở hạ tầng, hãy xem xét khối lượng nhập dữ liệu hàng ngày, khối lượng dữ liệu cho tải lịch sử một lần, khoảng thời gian lưu giữ dữ liệu, triển khai đa trung tâm dữ liệu và khoảng thời gian mà nhóm được định kích thước
Kích thước cơ sở hạ tầng: Điều này dựa trên lập kế hoạch năng lực và xác định số lượng cụm/môi trường cần thiết và loại phần cứng được yêu cầu. Xem xét loại đĩa và số lượng đĩa trên mỗi máy, các loại bộ nhớ xử lý và kích thước bộ nhớ, số CPU và lõi cũng như dữ liệu được giữ lại và lưu trữ trong mỗi môi trường.
Lập kế hoạch khôi phục sau thảm họa: Khi phát triển kế hoạch sao lưu và khôi phục thảm họa, hãy xem xét mức độ nghiêm trọng của dữ liệu được lưu trữ, các yêu cầu Mục tiêu về điểm khôi phục và thời gian khôi phục, khoảng thời gian sao lưu, triển khai nhiều trung tâm dữ liệu và liệu khôi phục thảm họa Active-Active hay Active-Passive là thích hợp nhất.
Lời kết
Khi dữ liệu, phân tích và AI được sử dụng nhiều hơn vào các hoạt động hàng ngày của hầu hết các tổ chức, rõ ràng là cần phải có một cách tiếp cận hoàn toàn khác đối với kiến trúc dữ liệu để tạo và phát triển doanh nghiệp tập trung vào dữ liệu. Các nhà lãnh đạo doanh nghiệp nên có những cách tiếp cận mới để công ty của họ để trở nên nhanh nhẹn, linh hoạt hơn.
Hy vọng bài viết đã mang đến những thông tin cần thiết cho bạn đọc đang tìm hiểu về kiến trúc dữ liệu lớn. Chúc bạn thành công!