Data Classification là gì? Các kiểu phân loại dữ liệu
BÀI LIÊN QUAN
Data fabric là gì? Những điều cần biết về kết cấu dữ liệuData set là gì? Những điều cần biết về data setDatabase (DB) là gì? Những ứng dụng Database phổ biến nhấtData Classification là gì?
Data Classification hay phân loại dữ liệu là quá trình phân tách và tổ chức các dữ liệu thành các nhóm ("lớp") có liên quan với nhau dựa trên những đặc điểm chung của chúng, chẳng hạn như mức độ nhạy cảm, rủi ro mà chúng gây ra và những quy định tuân thủ để bảo vệ chúng.
Để bảo vệ dữ liệu nhạy cảm, dữ liệu đó phải được định vị, phân loại theo mức độ nhạy cảm và được gắn thẻ chính xác. Sau đó, doanh nghiệp phải xử lý chính xác, cẩn trọng từng nhóm dữ liệu theo cách đảm bảo chỉ những người được ủy quyền mới có thể truy cập vào dữ liệu, từ cả bên trong lẫn bên ngoài tổ chức, và dữ liệu luôn được xử lý tuân thủ đầy đủ tất cả những quy định có liên quan.
Phân loại dữ liệu cũng giúp loại bỏ nhiều dữ liệu trùng lặp, có thể giảm thiểu chi phí lưu trữ và sao lưu đồng thời làm tăng tốc quá trình tìm kiếm. Mặc dù quy trình phân loại nghe có vẻ mang tính kỹ thuật cao, nhưng đây là một chủ đề mà ban lãnh đạo của các tổ chức doanh nghiệp nên hiểu rõ.
Khi được thực hiện chính xác, việc phân loại dữ liệu Data Classification giúp việc sử dụng và bảo vệ dữ liệu trở nên dễ dàng và hiệu quả hơn. Tuy nhiên, quá trình này thường bị bỏ qua, đặc biệt là khi các tổ chức không hiểu đầy đủ mục đích, phạm vi và khả năng của nó.
Hướng dẫn này cung cấp thông tin tổng quan toàn diện về phân loại dữ liệu để giúp các tổ chức hiểu cách thức hoạt động và vị trí phù hợp của nó trong chương trình quyền riêng tư và bảo mật dữ liệu doanh nghiệp.

Lý do cần đến giải pháp Data Classification
Data Classification phân loại dữ liệu đã được cải thiện đáng kể theo thời gian. Ngày nay, công nghệ này được sử dụng cho nhiều mục đích khác nhau, thường là để hỗ trợ cho những sáng kiến bảo mật dữ liệu. Tuy nhiên, dữ liệu có thể được phân loại vì một số lý do khác, bao gồm khả năng truy cập dễ dàng hơn, duy trì sự tuân thủ quy định và để đáp ứng được nhiều mục tiêu kinh doanh hoặc mục tiêu cá nhân khác.
Trong một số trường hợp, phân loại dữ liệu là một yêu cầu theo quy định, vì dữ liệu phải có thể tìm kiếm và truy xuất được trong các khung thời gian đã chỉ định. Vì mục đích bảo mật dữ liệu, phân loại dữ liệu là một chiến thuật hữu ích tạo điều kiện cho các phản hồi bảo mật phù hợp dựa trên loại dữ liệu được truy xuất, truyền tải hoặc sao chép.
Các loại Data Classification
Phân loại dữ liệu thường liên quan đến vô số thẻ và nhãn xác định loại dữ liệu, tính bảo mật và tính toàn vẹn của dữ liệu. Tính khả dụng cũng có thể được xem xét trong quá trình phân loại dữ liệu. Mức độ nhạy cảm của dữ liệu thường được phân loại dựa trên các mức độ quan trọng hoặc bảo mật khác nhau, sau đó tương quan với các biện pháp bảo mật được đưa ra để bảo vệ từng cấp độ phân loại.
Có ba loại phân loại dữ liệu chính được coi là tiêu chuẩn ngành:
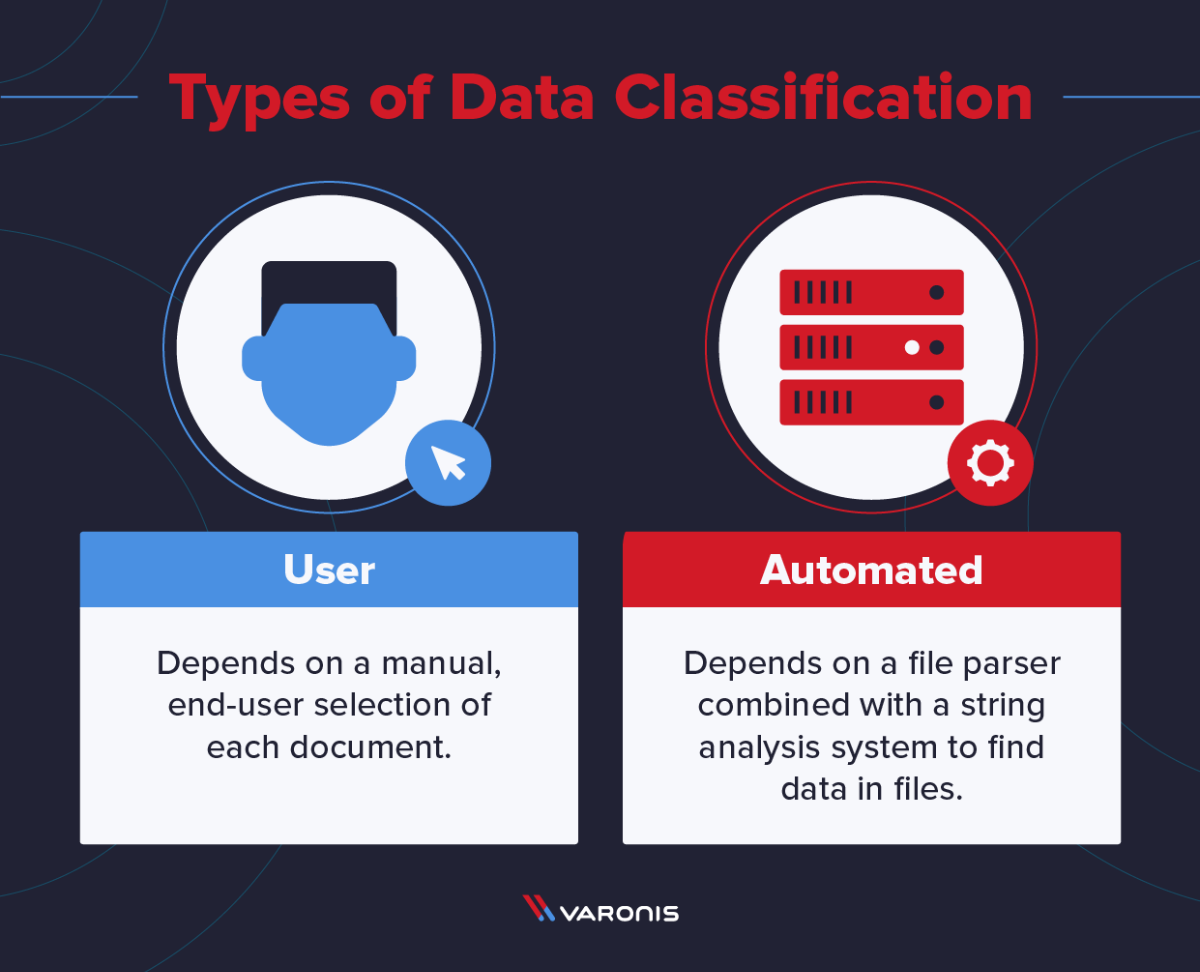
- Phân loại dữ liệu dựa trên nội dung kiểm tra và diễn giải các tệp đang tìm kiếm thông tin nhạy cảm
- Phân loại dựa trên bối cảnh xem xét của ứng dụng, vị trí hoặc người tạo trong số các biến khác dưới dạng các chỉ báo gián tiếp về thông tin nhạy cảm
- Phân loại dựa trên người dùng phụ thuộc vào lựa chọn thủ công của người dùng cuối đối với từng phân loại tài liệu. Phân loại dựa trên kiến thức và quyết định của người dùng khi tạo, chỉnh sửa, đánh giá hoặc độ phổ biến của dữ liệu để gắn cờ các tài liệu nhạy cảm.
Các cách tiếp cận dựa trên nội dung, bối cảnh và người dùng có thể đúng hoặc sai tùy thuộc vào nhu cầu mục đích kinh doanh và các loại dữ liệu.
Cấp độ nhạy cảm dữ liệu
Dữ liệu được phân loại dựa theo mức độ nhạy cảm là cao, trung bình hoặc thấp.
- Dữ liệu có độ nhạy cảm cao - nếu bị xâm phạm hoặc phá hủy trong một giao dịch trái phép, sẽ có tác động nghiêm trọng đối với tổ chức hoặc cá nhân. Ví dụ, hồ sơ tài chính, dữ liệu bí mật kinh doanh, sở hữu trí tuệ, dữ liệu xác thực.
- Dữ liệu có độ nhạy cảm trung bình - chỉ dành cho mục đích sử dụng nội bộ, nhưng nếu bị xâm phạm hoặc phá hủy, sẽ không gây ra tác động nghiêm trọng nào đối với tổ chức hoặc cá nhân. Ví dụ: email và tài liệu không có dữ liệu bí mật.
- Dữ liệu có độ nhạy thấp - dành cho mục đích sử dụng chung. Ví dụ, nội dung trang web công khai.
Dựa vào các cấp độ này công cụ Data Classification có thể phân loại dữ liệu hiệu quả nhất.

Những phương pháp phân loại dữ liệu
Phân loại dữ liệu phối hợp chặt chẽ với những công nghệ khác để bảo vệ và quản lý dữ liệu tốt hơn. Nếu các doanh nghiệp, tổ chức bị vi phạm dữ liệu, việc tiến hành phân loại dữ liệu sẽ giúp cho các quản trị viên xác định được những dữ liệu bị mất và có khả năng giúp truy tìm những kẻ tội phạm mạng.
Dưới đây là các công nghệ dựa trên việc phân loại dữ liệu:
- Quản lý truy cập danh tính (IAM): Công cụ IAM cho phép quản trị viên xác định ai có thể truy cập dữ liệu. Người dùng có quyền tương tự có thể được tập hợp thành một nhóm. Các nhóm được cấp quyền và được quản lý như một đơn vị duy nhất. Khi một người dùng rời đi, người dùng đó có thể bị xóa khỏi nhóm, điều này sẽ loại bỏ tất cả các quyền của người dùng đó. Kiểu tổ chức và nhóm này hợp lý hóa việc quản lý quyền trên toàn mạng.
- Mã hóa dữ liệu: Một số nội dung dữ liệu nhất định phải được mã hóa khi ở trong trạng thái nghỉ và đang chuyển động. Dữ liệu “ở trạng thái nghỉ” là dữ liệu được lưu trữ - thường là trên ổ cứng - trên bất kỳ thiết bị lưu trữ nào. Dữ liệu "đang chuyển động" đề cập đến loại dữ liệu khi nó được truyền qua mạng. Mã hóa dữ liệu khiến cho chúng không thể đọc được khi kẻ tấn công truy cập vào hệ thống dữ liệu.
- Tự động hóa: Tự động hóa hoạt động với các công cụ giám sát để tìm, phân loại và dán nhãn dữ liệu để xem xét việc quản trị. Một số công cụ tích hợp trí tuệ nhân tạo (AI) và máy học (ML) để tự động phát hiện, gắn nhãn và phân loại dữ liệu. Các công nghệ này cũng có thể giúp xác định được những mối đe dọa có thể xảy ra để đánh cắp chúng. Với dữ liệu được gắn nhãn, quản trị viên có thể sử dụng IAM để phân quyền và ngăn chặn hiệu quả các mối đe dọa trong việc có kẻ xấu giành quyền truy cập vào những dữ liệu được lưu trữ.
- Điều tra dữ liệu: Điều tra là quá trình xác định những gì đã xảy ra và ai đã có hành vi vi phạm mạng. Sau khi vi phạm dữ liệu, đội ngũ pháp y dữ liệu thu thập và lưu giữ bằng chứng để điều tra thêm. Điều tra dữ liệu thường là một quá trình gồm hai phần. Trước tiên, các công cụ tự động hóa sẽ thu thập dữ liệu, sau đó một nhà phân tích sẽ xác định các điểm bất thường và điều tra.
Quy trình Data Classification phân loại dữ liệu
Khi các doanh nghiệp quyết định đã đến lúc áp dụng Data Classification để đáp ứng các tiêu chuẩn tuân thủ, bước đầu tiên là triển khai các quy trình hỗ trợ xác định vị trí, phân loại dữ liệu và xác định những biện pháp an ninh mạng phù hợp. Việc thực hiện từng quy trình tùy thuộc vào các tiêu chuẩn tuân thủ của tổ chức doanh nghiệp và hệ thống cơ sở hạ tầng bảo mật dữ liệu tốt nhất. Các bước phân loại dữ liệu chung là:
- Thực hiện đánh giá rủi ro: Đánh giá rủi ro, xác định độ nhạy cảm của dữ liệu và xác định cách mà kẻ tấn công có thể vi phạm hệ thống an ninh phòng thủ mạng.
- Phát triển các chính sách và tiêu chuẩn phân loại: Nếu bạn tạo dữ liệu bổ sung trong tương lai, chính sách phân loại cho phép hợp lý hóa quy trình lặp lại, giúp nhân viên dễ dàng hơn trong khi thao tác công việc, giảm thiểu sai sót trong quy trình.
- Phân loại dữ liệu: Với việc đánh giá rủi ro, hãy phân loại dữ liệu của bạn dựa trên độ nhạy cảm của dữ liệu, ai sẽ có thể truy cập dữ liệu đó và đặt ra các hình phạt tuân thủ nào đó nếu dữ liệu đó được tiết lộ công khai.
- Tìm vị trí lưu trữ dữ liệu của bạn: Trước khi triển khai các biện pháp bảo vệ an ninh mạng phù hợp, bạn cần biết chính xác dữ liệu được lưu trữ ở đâu. Việc xác định vị trí lưu trữ dữ liệu sẽ có phép chỉ ra phương án an ninh mạng cần thiết để bảo vệ dữ liệu.
- Xác định và phân loại dữ liệu của bạn: Với dữ liệu đã được xác định, giờ đây người dùng có thể phân loại được các dữ liệu đó một cách đơn giản hơn. Phần mềm của bên thứ ba giúp bạn trong bước này có thể dễ dàng phân loại dữ liệu và theo dõi nó chính xác hơn.
- Triển khai các quyền điều khiển: Các quy trình điều khiển mà bạn sử dụng sẽ yêu cầu việc xác thực và yêu cầu truy cập ủy quyền từ tất cả các đối tượng người dùng. Quyền truy cập đó phải dựa trên cơ sở “cần biết”, nghĩa là người dùng chỉ nhận được quyền truy cập nếu họ cần xem dữ liệu để thực hiện chức năng công việc.
- Giám sát quyền truy cập và dữ liệu: Giám sát dữ liệu là một yêu cầu đối với việc tuân thủ và bảo mật dữ liệu của bạn. Nếu không giám sát thường xuyên, kẻ tấn công có thể bỏ ra thời gian nhiều tháng để lấy dữ liệu từ mạng. Các biện pháp kiểm soát giám sát phù hợp sẽ phát hiện các điểm bất thường và giảm thiểu thời gian cần thiết để phát hiện vấn đề bất thường và loại bỏ những mối đe dọa.
Trên đây là nội dung Data Classification là gì và lý do tại sao nên áp dụng việc phân loại dữ liệu. Khi thực hiện phân loại dữ liệu doanh nghiệp có thể bảo vệ các dữ liệu an toàn hơn.