Tổng quan về Apache Hadoop
BÀI LIÊN QUAN
Tìm hiểu những thông tin cơ bản về NoSQL DatabasesTất tần tật những điều cần biết về Data lakesApache Spark là gì? Những ưu điểm nổi bật của apache SparkApache Hadoop là gì?
Hadoop là một Apache framework mã nguồn mở cho phép phát triển tất cả các ứng dụng phân tán để lưu trữ và quản lý các tập thông tin, dữ liệu lớn. Apache Hadoop hiện thực mô hình MapReduce, được ứng dụng chia nhỏ thành nhiều phân đoạn khác nhau chạy song song trên nhiều node khác nhau. Hadoop được viết bằng ngôn ngữ Java, tuy nhiên vẫn hỗ trợ Python, C++, Perl bằng cơ chế streaming.
Hadoop thường được sử dụng để giải quyết một số vấn đề như:
- Xử lý và làm việc với khối lượng dữ liệu khổng lồ tính bằng Petabyte.
- Xử lý dữ liệu trong môi trường phân tán, lưu trữ ở nhiều phần cứng khác nhau, yêu cầu xử lý đồng bộ.
- Xử lý các lỗi thường xuyên xuất hiện.
- Băng thông giữa các phần cứng vật lý chứa dữ liệu phân tán có giới hạn.

Ưu điểm của Apache Hadoop
Hadoop được nhiều người sử dụng bởi cho phép người dùng nhanh chóng kiểm tra được tiến trình hoạt động của các dữ liệu phân tán. Nhờ có cơ chế xử lý cùng lúc của các lõi CPU được cài đặt sẵn, một lượng dữ liệu lớn sẽ được phân phối xuyên suốt liên tục mà không bị gián đoạn do quá tải hay vì bất kỳ lý do gì.
Apache Hadoop không bị ảnh hưởng bởi cơ chế chịu lỗi của FTHA (Fault-Tolerance and High Availability). Công cụ này có khả năng xử lý các lỗi riêng nhờ các thư viện được thiết kế đặc biệt nhằm phát hiện lỗi ở các lớp ứng dụng. Chính vì vậy, trong trường hợp không may có lỗi xảy ra, Hadoop sẽ nhanh chóng nhận dạng và xử lý lỗi đó trong thời gian sớm nhất nhờ cơ chế chủ động của mình để không ảnh hưởng đến hệ thống.
Một ưu điểm tiếp theo của Hadoop chính là khả năng triển khai được rất nhiều Master - Slave song song để xử lý các phần dữ liệu khác nhau. Vì có nhiều server master nên công việc hoạt động sẽ không bị trì hoãn dù không may có một master nào bị lỗi nhờ chức năng của Hadoop.
Ngoài ra, do công cụ Hadoop được xây dựng từ ngôn ngữ Java nên chúng có khả năng tương thích cao với nhiều hệ thống nền tảng và hệ điều hành khác nhau như: Window, MacOs, Linux,...

Kiến trúc của Apache Hadoop
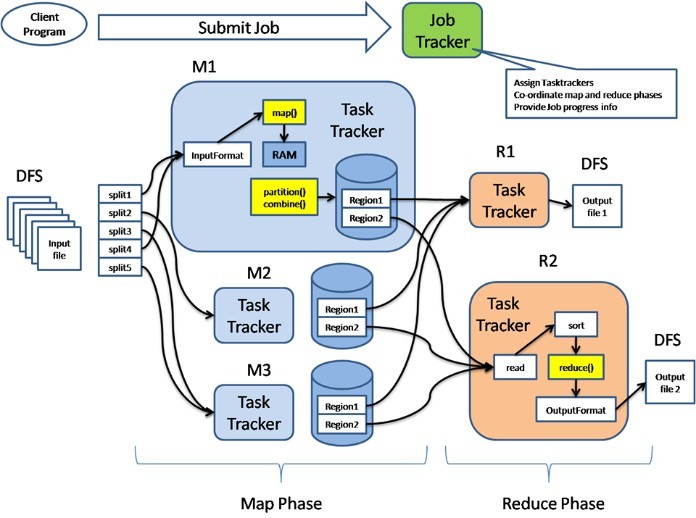
Một cụm Hadoop gồm có 1 master node và nhiều worker/slave node. Toàn bộ các cụm chứa 2 lớp, một lớp là HDFS Layer và lớp kia là MapReduce. Mỗi lớp đều có những thành phần liên quan riêng. Master node gồm có TaskTracker, JobTracker, DataNode, NameNode. Slave/Worker node gồm TaskTracker và Data Node.
Kiến trúc của apache hadoop gồm có 4 module:
Hadoop Distributed File System (HDFS)
HDFS là hệ thống file phân tán cung cấp truy cập thông lượng cao cho các ứng dụng khai thác dữ liệu, đây là một hệ thống tập tin ảo. Khi chúng ta di chuyển một tập tin trên HDFS, nó sẽ tự động chia thành nhiều mảnh nhỏ hơn. Các đoạn nhỏ của tệp tin đó sẽ được nhân rộng và lưu trữ trên nhiều hệ thống máy chủ khác để tăng sức chịu lỗi và có tính sẵn sàng cao.
Hadoop Distributed File System sử dụng kiến trúc Master/Slave, trong đó Master gồm có một NameNode để quản lý hệ thống file Metadata. Và có thêm một hoặc nhiều Slave DataNodes với nhiệm vụ lưu trữ dữ liệu thực tại.
Một tập tin dưới định dạng HDFS được chia thành nhiều khối khác nhau và những khối này sẽ lưu trữ trong một tập các DataNodes. Trong khi đó, NameNode sẽ có chức năng định nghĩa ánh xạ từ các khối đến các DataNode. Nhiệm vụ chính của DataNode là điều hành tác vụ đọc, ghi lại dữ liệu lên hệ thống các file. Bên cạnh đó, chúng cũng quản lý việc tạo, hủy và nhân rộng các khối thông qua chỉ thị từ NameNode.

Hadoop Common
Apache Hadoop Common được dùng như một thư viện lưu trữ tiện ích và cần thiết của Java. Tại đây có những tính năng quan trọng để các modules khác trong Hadoop sử dụng. Những thư viện này cung cấp các hệ thống file và lớp OS trừu tượng. Đồng thời, chúng cũng lưu trữ các mã lệnh cần thiết của Java để thực hiện quá trình khởi động Hadoop.
Hadoop YARN
Phần này được sử dụng như một framework, với chức năng hỗ trợ các hoạt động quản lý thư viện tài nguyên của hệ thống lưu trữ dữ liệu và thực hiện chạy phân tích tiến trình.
Hadoop MapReduce
Hadoop MapReduce là một hệ thống hoạt động dựa trên YARN để xử lý song song các tập dữ liệu có kích thước lớn. Công cụ này cho phép chia dữ liệu lớn thành các đoạn nhỏ hơn và phân tán từ một máy chủ sang nhiều máy con.
Mỗi máy con sẽ được nhận một phần dữ liệu khác nhau và đồng thời tiến hành xử lý. Sau đó, chúng sẽ báo lại kết quả lên máy chủ, nhiệm vụ của máy chủ là tổng hợp lại thông tin và trích xuất nguồn ra theo như yêu cầu của người dùng.
MapReduce gồm có một Single Master, JobTracker và các Slave trên mỗi cluster. Master có nhiệm vụ quản lý, theo dõi quá trình tiêu thụ và lập lịch quản lý các tác vụ trên máy trạm. Các máy Slave TaskTracker chỉ thực thi các tác vụ mà máy chủ chỉ định và cung cấp lại thông tin để Master theo dõi.
Cách hoạt động theo mô hình như vậy giúp tiết kiệm nhiều thời gian để xử lý và giảm được gánh nặng lên hệ thống. Tuy nhiên, đây cũng là một điểm yếu cần phải được khắc phục ở hệ thống này, bởi nếu máy chủ bị lỗi thì toàn bộ quá trình hoạt động ở máy con sẽ bị ngưng hoàn toàn.
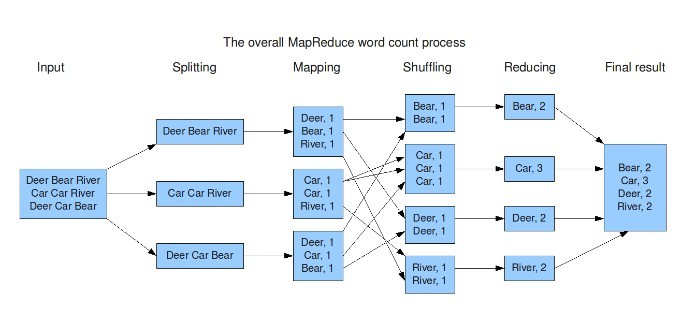
Apache Hadoop hoạt động như thế nào?
Hadoop được hoạt động gồm có 3 giai đoạn chính sau:
Giai đoạn 1
Ở giai đoạn đầu tiên này, người dùng hay một ứng dụng có thể gửi một job lên Hadoop với yêu cầu xử lý các thông tin và thao tác. Job này sẽ đi kèm với các thông tin cơ bản như:
- Nơi lưu trữ dữ liệu input, output trên hệ thống các dữ liệu phân tán.
- Các java class ở định dạng jar chứa các dòng lệnh thực thi.
- Các thông số thiết lập cụ thể liên quan đến các job truyền vào.
Giai đoạn 2
Sau khi apache hadoop nhận được các thông tin dữ liệu cần thiết, máy chủ sẽ chia khối lượng công việc đến cho các máy trạm. Khi đó, máy chủ sẽ tiến hành theo dõi và quản lý tiến trình hoạt động của các máy này. Đồng thời đưa ra các thông tin về tình trạng và các lệnh cần thiết khi phát hiện có lỗi xảy ra.
Giai đoạn 3
Bước cuối cùng trong hoạt động của Hadoop, các node khác nhau sẽ tiến hành chạy các tác vụ của hệ thống MapReduce. Thông tin dữ liệu sẽ được chia nhỏ thành các khối và thay phiên nhau xử lý. Khi Hadoop hoạt động, chúng sẽ sử dụng một tập tin nền làm địa chỉ thường trú. Những chương trình nền này có vai trò cụ thể, một số chỉ được tồn tại trên máy chủ, một số tệp có thể tồn tại được ở cả nhiều máy chủ khác..
Lời kết
Bài viết trên đây đã cung cấp rất nhiều thông tin hữu ích về công cụ Apache Hadoop xử lý Big Data. Để có thể hiểu và tận dụng được những lợi ích từ nguồn dữ liệu lớn, việc nắm chắc định nghĩa, kiến trúc và cách thức hoạt động của Hadoop là vô cùng cần thiết. Hãy tìm hiểu và áp dụng ngay công cụ này vào công việc để nhận được nhiều lợi nhuận và thành công hơn bạn nhé!