Noisy channel model là gì? Ứng dụng của mô hình kênh nhiễu
BÀI LIÊN QUAN
Các dự đám về tương lai IoT bạn không nên bỏ lỡBạn biết gì về công nghệ IoT?IoT và trí tuệ nhân tạo ứng dụng – sự kết hợp hoàn hảoNoisy channel model là gì?
Noisy channel model, mô hình kênh nhiễu hay mô hình kênh ồn ào, là một khuôn khổ máy tính sử dụng để kiểm tra chính tả, trả lời câu hỏi, nhận dạng giọng nói và thực hiện dịch máy. Noisy channel model có mục đích xác định từ chính xác nếu bạn nhập sai chính tả hoặc phát âm sai.
Noisy channel model có công dụng gì?
- Nhận dạng chữ viết tay
- Tạo văn bản
- Tóm tắt văn bản
- Dịch máy
- Sửa lỗi chính tả
Cách Noisy channel model hoạt động
Noisy channel model là một cách để khái niệm hóa nhiều hiện tượng hoặc quá trình trong xử lý, hiểu ngôn ngữ tự nhiên.
Giả sử một đoạn văn bản (w) đi qua một kênh nhiễu và tạo ra kết quả là một đoạn văn bản (y) bị cắt xén ở phía bên kia của kênh. Hoặc cũng có thể xem nó giống như một bộ mã hóa mã hóa w thành y.

Bây giờ chúng ta thử mô hình hóa kênh nhiễu này để có thể tìm ra ước tính tốt nhất của W cho phép gọi nó đã w' cho y. Hoặc trong trường hợp của kiểu giải thích thứ hai, chúng ta có thể coi nó như là mô hình hóa một bộ giải mã sẽ giải y mã w'.
Noisy channel model là một mô hình xác suất trong đó sử dụng Quy tắc Bayes để xác định xác suất của w' cho y.
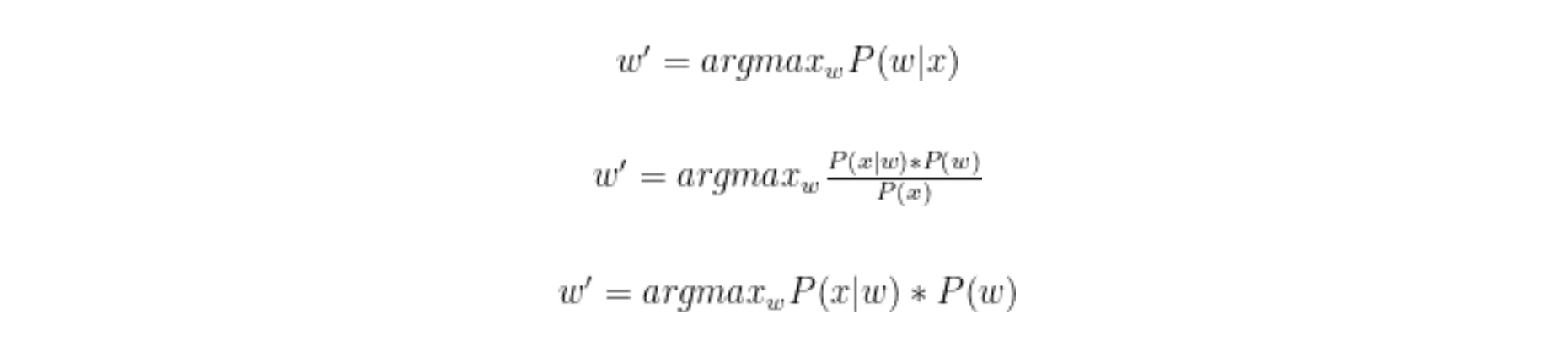
Ở đây, P(w)là mô hình ngôn ngữ cho chúng ta biết xác suất của từ trở thành w. P(x|w) là Noisy Channel Model cho chúng ta biết xác suất của văn bản gốc là x cho trước.
Một số ứng dụng Noisy channel model
Ngoài việc sửa lỗi chính tả, Noisy channel model cho phép máy tính trả lời các câu hỏi, nhận dạng giọng nói và thực hiện dịch máy.
Sử dụng Noisy channel model để sửa lỗi chính tả
Mục tiêu của Noisy channel model là tìm từ dự định cho từ xáo trộn đã nhận được.
Các phương pháp xây dựng hàm quyết định bao gồm quy tắc khả năng xảy ra tối đa, quy tắc hậu kỳ tối đa và quy tắc khoảng cách tối thiểu .
Để tính toán P(x|w), trước tiên là xây dựng một ma trận nhầm lẫn, cho biết một cặp chữ cái với các khả năng xảy ra chỉnh sửa deletion / insertion / substitution / transposition (xóa / chèn / thay thế / chuyển vị).
- Deletion (x,w) = count (xw được chuyển đổi thành x)
- Insert (x ,w) = count (w được chuyển thành xw)
- Substitution (x, w) = count (w được chuyển thành x)
- Transposition (x, w) = count (xw được chuyển thành wx)
Tiếp theo, để có xác suất P(x|w)chỉ cần chia nó cho số ký tự thực:
- Đối với Deletion: xóa (x,w) / count (xw)
- Đối với Insert: thêm (x,w) / count (w)
- Đối với Substitution: thay thế (x,w) / count (w)
- Đối với Transposition: chuyển vị (x,w) / count (xw)
Giải thích một cách dễ hiểu về ứng dụng sửa lỗi sai, Noisy channel model có thể sửa một số lỗi đánh máy, bao gồm cả các chữ cái bị thiếu (thay đổi “leter” thành “letter”), bổ sung chữ cái ngẫu nhiên (thay thế “misstake” thành “mistake”), các chữ cái bị hoán đổi (thay đổi “recieve” thành “receive”) và thay thế các chữ cái không chính xác (thay thế “fimite” thành “finite”).
Trong một số trường hợp, có thể tốt hơn là chấp nhận từ bị xáo trộn là từ dự định thay vì cố gắng tìm một từ dự định trong từ điển. Ví dụ, từ "schönfinkeling" có thể không có trong từ điển, nhưng trên thực tế có thể là từ dự định.
Sử dụng Noisy channel model để trả lời câu hỏi
Máy tính được thiết kế để trả lời các câu hỏi, thường sử dụng hai thành phần - một công cụ truy xuất thông tin (IR) và một mô-đun nhận dạng câu trả lời.
Công cụ IR truy xuất một tập hợp các tài liệu hoặc câu có thể chứa câu trả lời cho một câu hỏi nhất định. Trong khi đó, mô-đun nhận dạng câu trả lời xác định một chuỗi con của tài liệu hoặc câu để xác định các câu trả lời có thể có. Mỗi câu trả lời trong số các câu trả lời này được ấn định một số điểm, tùy thuộc vào khả năng chúng là câu trả lời chính xác.
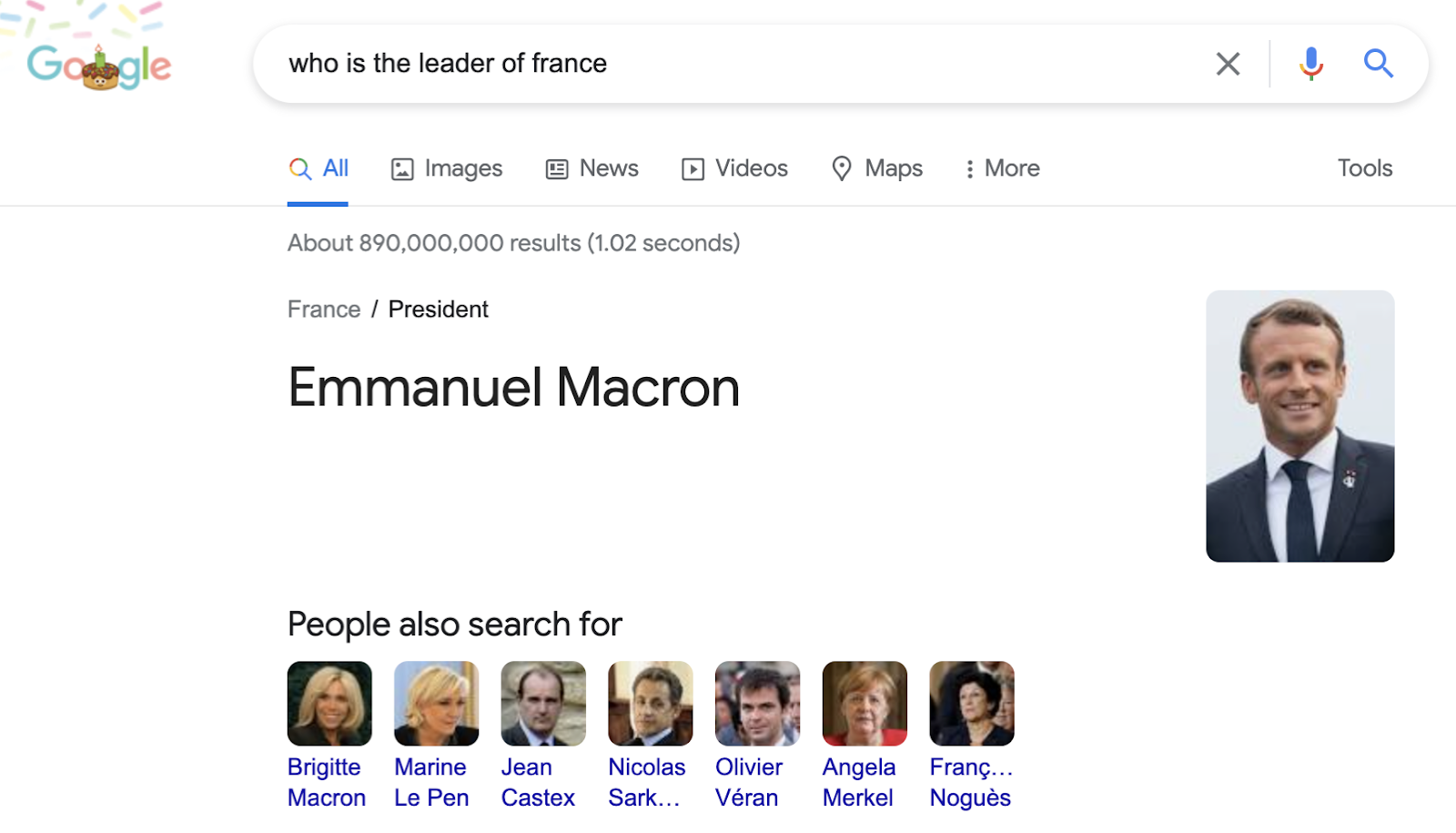
Ví dụ. Để trả lời câu hỏi "Ai là nhà lãnh đạo của nước Pháp?", Một máy tính có thể xem xét một câu trả lời như "Henri Hadjenberg, người lãnh đạo cộng đồng Do Thái của Pháp, đã tán thành việc đối đầu với bóng ma của quá khứ Vichy". Bởi vì trong văn bản có chuỗi "nhà lãnh đạo của nước Pháp" giống như câu hỏi. Tuy nhiên, điều này không thực sự chính xác, vì câu hỏi có thể đề cập đến tổng thống của đất nước. Đó là lý do tại sao các nhà phát triển đã nghĩ ra cơ sở dữ liệu (coi chúng như từ điển được tích hợp trong công cụ IR) để tạo ra một danh sách các câu trả lời.
Cơ sở dữ liệu dịch chuỗi "nhà lãnh đạo" thành "tổng thống", cho phép máy tính hoặc trình duyệt của bạn cung cấp cho bạn câu trả lời này khi bạn nhập "Ai là nhà lãnh đạo của nước Pháp?" vào trường tìm kiếm:
Sử dụng Noisy channel model để nhận dạng giọng nói
Noisy channel model để nhận dạng giọng nói hoạt động theo cách tương tự. Thay vì trang bị một máy tính với từ điển và/hoặc từ đồng nghĩa, một cơ sở dữ liệu âm thanh được kết nối. Kho này chứa các âm thanh từ mà máy dịch thành mã để hiểu những gì người nói nói.
Người nói cần phát âm các từ giống như cách họ đã được ghi lại trong cơ sở dữ liệu. Đó là lý do tại sao Siri hoặc Alexa thỉnh thoảng yêu cầu bạn lặp lại các lệnh. Bạn cần phát âm các từ theo cách mà mô-đun hiểu trước khi nó có thể cung cấp cho bạn câu trả lời cho câu hỏi của bạn hoặc làm theo lệnh của bạn.
Sử dụng Noisy channel model để dịch máy
Trong Google Dịch và các trình dịch tương tự, Noisy channel model sử dụng cơ sở dữ liệu tương đương với một từ trong tất cả các ngôn ngữ mà nó có thể dịch sang.
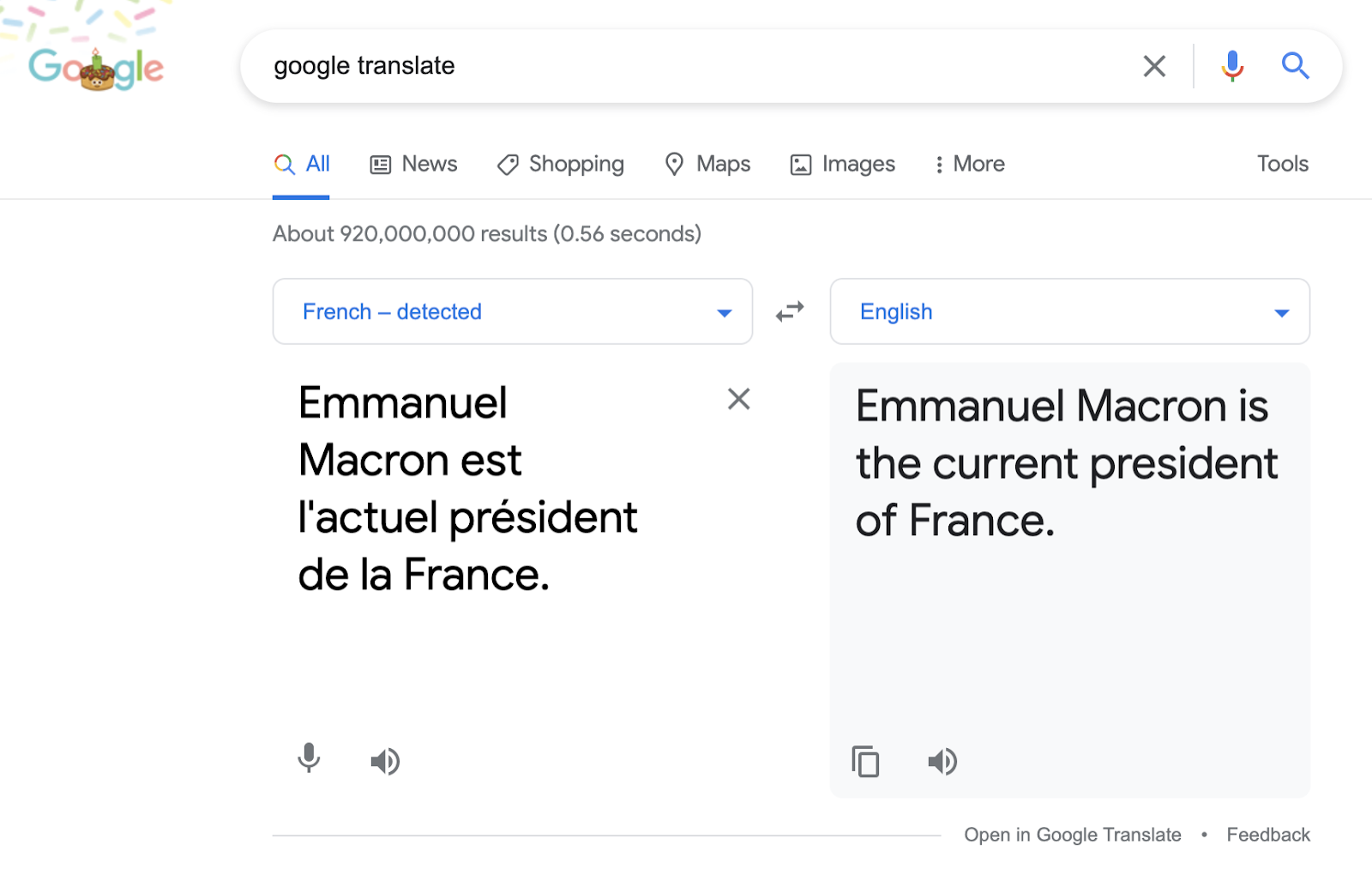
Ví dụ, để dịch một câu tiếng Pháp sang tiếng Anh, trước tiên máy tính sẽ ngắt câu đó thành các từ. Vì vậy, để dịch tuyên bố "Emmanuel Macron est l'actuel président de la France." sang tiếng Anh, ứng dụng sẽ sử dụng quy trình từng từ một:
- est = is
- l'actuel = current
- président = president
- de la = of
Sau đó, Google Dịch áp dụng các quy tắc liên hợp cho câu lệnh, mang lại cho bạn kết quả sau:
Lời kết
Trình kiểm tra chính tả, trình duyệt và các trình cung cấp câu trả lời khác, ứng dụng nhận dạng giọng nói và trình dịch ngày nay vẫn có những điểm chưa hoàn hảo, nhưng điều đó có thể được cải tiến theo hướng tốt hơn khi các công cụ và mô-đun của chúng được cải thiện theo thời gian. Hiện tại, nhờ có Noisy channel model, chúng ta có thể tận hưởng các tính năng nâng cao để viết và tìm kiếm thông tin.