Data splitting là gì? Tỷ lệ Train/Dev/Test phù hợp nhất
BÀI LIÊN QUAN
Data Definition Language (DDL) là gì? Những tính năng hữu ích của DDLData historian là gì? Cơ sở hạ tầng của data historianMaster data là gì? Phương pháp giúp quản trị Master data đạt hiệu quả caoData splitting là gì?
Data splitting là dữ liệu được chia thành hai hay nhiều tập con. Thông thường, nếu dữ liệu được chia thành hai phần, một phần trong đó sẽ được dùng để đánh giá hoặc kiểm tra (test), phần còn lại dùng để huấn luyện mô hình (training).
Data splitting là một kỹ thuật quan trọng của khoa học dữ liệu, đặc biệt là trong quá trình tạo mô hình dựa trên dữ liệu. Kỹ thuật này giúp đảm bảo các mô hình và quy trình sử dụng các mô hình dữ liệu - chẳng hạn học máy - được tạo lập một cách chính xác.
Các thành phần trong data splitting
- Tập huấn luyện: Training set là tập dữ liệu được sử dụng để huấn luyện, giúp mô hình tìm hiểu các tính năng/mẫu ẩn trong dữ liệu.
- Tập tối ưu: Validation Set, đôi khi được gọi là development set hay dev set, là tập dữ liệu tách biệt với tập huấn luyện, được sử dụng để xác thực hiệu suất mô hình trong quá trình đào tạo.
- Tập thử nghiệm: Test set là một tập dữ liệu riêng biệt được sử dụng để kiểm tra mô hình sau khi hoàn thành quá trình huấn luyện.
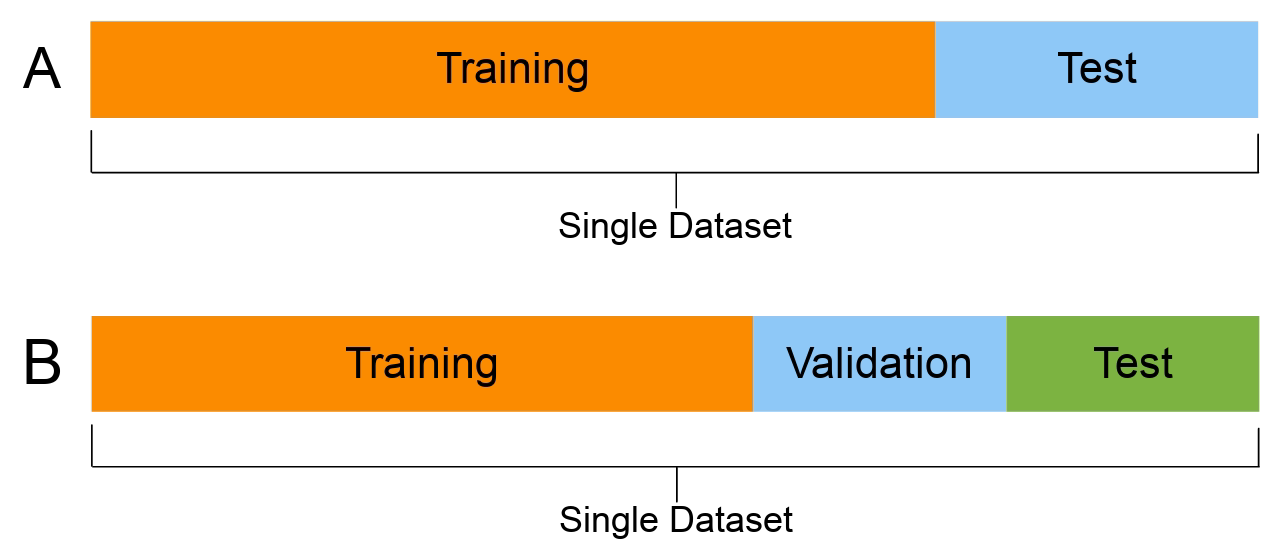
Data splitting hoạt động như thế nào?
Trong data splitting cơ bản (dữ liệu chia làm hai phần), tập dữ liệu huấn luyện (training set) được sử dụng để đào tạo và phát triển các mô hình. Mục đích sử dụng là để ước tính các tham số hoặc để so sánh hiệu suất giữa các mô hình khác nhau.
Tập dữ liệu thử nghiệm (test set) được sử dụng sau khi mô hình hoàn tất đào tạo. Dữ liệu huấn luyện được đem ra so sánh với dữ liệu thử nghiệm nhằm kiểm tra độ chính xác của mô hình cuối cùng. Với học máy (machine learning), dữ liệu thường được chia thành ba phần trở lên: training data, testing data và validation Set (tập tối ưu).
Không có quy tắc cụ thể nào về cách phân tách dữ liệu; nó có thể tùy thuộc vào kích thước của nhóm dữ liệu gốc hay lượng yếu tố dự đoán trong một mô hình dự đoán. Bạn có thể phân tách dữ liệu dựa trên các phương pháp lấy mẫu dữ liệu (data sampling) sau:
- Lấy mẫu ngẫu nhiên: Phương pháp này bảo vệ quy trình lập mô hình khỏi sự thiên vị giữa các đặc điểm khác nhau của dữ liệu. Tuy nhiên, việc chia ngẫu nhiên có thể dẫn đến việc phân phối dữ liệu không đồng đều.
- Lấy mẫu phân tổ ngẫu nhiên: Phương pháp này chọn ngẫu nhiên các mẫu dữ liệu trong các tham số cụ thể. Nó đảm bảo dữ liệu được phân bổ chính xác trong các tập huấn luyện và thử nghiệm.
- Lấy mẫu phi ngẫu nhiên: Phương pháp này thường được sử dụng khi người lập mô hình dữ liệu muốn dữ liệu gần nhất làm tập thử nghiệm.
Với data splitting, các tổ chức không phải lựa chọn giữa sử dụng dữ liệu để phân tích hay phân tích thống kê vì họ có thể sử dụng một dữ liệu cùng lúc cho những quy trình khác nhau.
Mẹo để chọn tỷ lệ Train/Dev/Test set
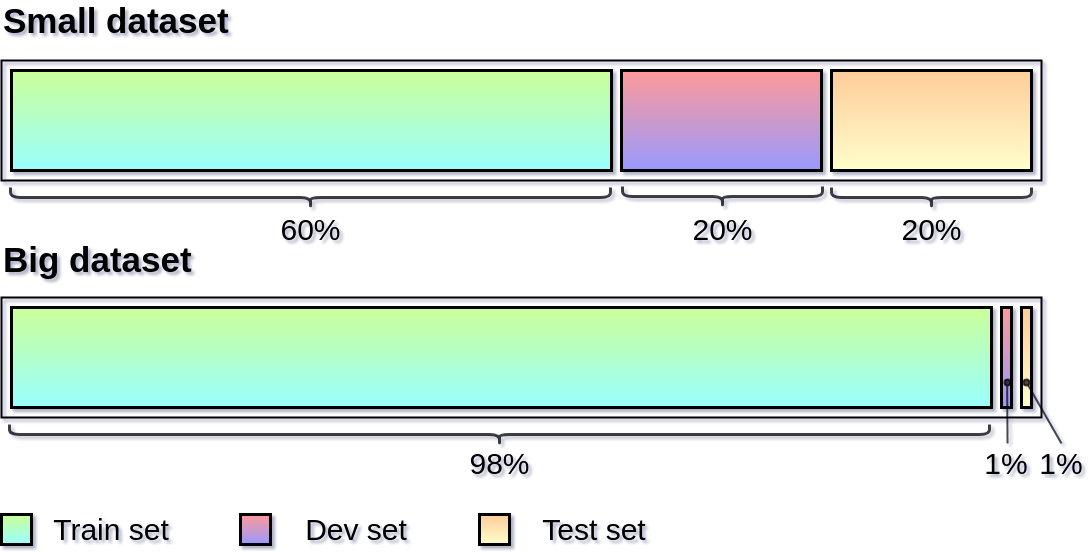
- Kích thước của tập huấn luyện, tập tối ưu và tập thử nghiệm vẫn là một trong những chủ đề gây tranh cãi. Mặc dù đối với Học máy nói chung, tỷ lệ Train/Dev/Test có thể được chấp nhận ở mức 60/20/20. Tuy nhiên trong thế giới Big data (dữ liệu lớn) như ngày nay, chỉ con số 20% thôi cũng đã tương đương với một tập dữ liệu khổng lồ. Chúng tôi có thể dễ dàng sử dụng lượng dữ liệu Dev/Test ấy để đào tạo mô hình và giúp chúng tìm hiểu đa dạng tính năng hơn. Do đó, trong trường hợp tập dữ liệu lớn (nơi có đến hàng triệu bản ghi), tỷ lệ phân chia đào tạo/tối ưu/thử nghiệm 98/1/1 đã là đủ bởi 1% cũng là một lượng dữ liệu khổng lồ.
- Giờ đây chúng ta có thể chia tập dữ liệu bằng Thư viện học máy - Turicreate. Thư viện này sẽ giúp chúng tôi chia dữ liệu thành training set, test set và dev set.
- Training set có thể đến từ một kênh phân phối khác dev set và test set.
- Dev set và Test set phải tách từ cùng một kênh phân phối. Bạn nên xáo trộn toàn bộ dữ liệu, sau đó chia ngẫu nhiên chúng thành tập tối ưu và tập thử nghiệm.
- Bạn nên chọn dev set và test set thể hiện dữ liệu bạn muốn nhận được trong tương lai và dữ liệu mà bạn cho là quan trọng cần thực hiện tốt. Tập tối ưu và tập thử nghiệm phải là thành tố giúp mô hình của bạn trở nên mạnh mẽ hơn.
Phải làm gì trong trường hợp Train set không khớp Dev/Test set?
Sẽ có một số trường hợp tập huấn luyện và tập tối ưu/thử nghiệm đến từ những kênh phân phối khác nhau. Ví dụ: Chúng ta đang xây dựng một ứng dụng trên thiết bị di động với mục đích phân loại hoa thành. Người dùng sẽ nhấp vào hình ảnh của bông hoa và ứng dụng sẽ đưa ra tên của bông hoa tương ứng.
Bây giờ, giả sử trong bộ dữ liệu (dataset), chúng ta có 200.000 hình ảnh lấy từ nhiều trang web và 10.000 hình ảnh được tạo từ máy ảnh của điện thoại di động. Trong trường hợp này, 2 tùy chọn có thể xảy ra:
- Tùy chọn 1: Chúng ta có thể xáo trộn dữ liệu một cách ngẫu nhiên và chia dữ liệu thành Train/ Dev/Test như 205000/2500/2500. Trong trường hợp này, tất cả các tập huấn luyện, tập tối ưu và tập thử nghiệm đều từ cùng một kênh phân phối nhưng vấn đề là tập tối ưu và tập thử nghiệm sẽ dính lượng lớn hình ảnh từ web mà chúng ta không quan tâm.
- Tùy chọn 2: Chúng ta có thể lấy tất cả các hình ảnh từ web và 5.000 ảnh từ máy ảnh cho vào Training set, 5.000 ảnh từ máy ảnh còn lại sẽ dùng để lập tập tối ưu và thử nghiệm. Với cách phân phối như trường hợp này, chúng ta nhắm được mục tiêu phân phối (hình từ máy ảnh), do đó, dẫn đến hiệu suất sẽ tốt hơn.
Tại sao Data splitting quan trọng?
Việc đào tạo mô hình học máy không thể dựa trên một tập dữ liệu duy nhất. Thậm chí chúng ta cố gắng đào tạo trên một tập dữ liệu đi chăng nữa thì cũng sẽ không thể đánh giá hiệu suất của mô hình học máy đó. Chính vì lẽ đó, chúng ta phải chia dữ liệu nguồn thành các tập dữ liệu đào tạo, thử nghiệm và tối ưu.
Chẳng hạn giáo viên dạy sinh viên về một thuật toán. Để giải thích, cô ấy sử dụng một số ví dụ, những ví dụ ở đây chính là Training set. Còn sinh viên trong trường hợp này là mô hình Học máy và các ví dụ là một phần của tập dữ liệu. Bởi, sinh viên đang học thông qua những ví dụ.
Sau đó, để kiểm tra sinh viên đã nắm đúng các khái niệm về thuật toán hay chưa, giáo viên cho họ làm một số bài tập thực hành. Bằng cách giải các bài toán đó, sinh viên sẽ được đánh giá khả năng tiếp thu và nếu có bất kỳ vướng mắc nào, họ có thể hỏi giáo viên để được hướng dẫn. Những câu hỏi của sinh viên chính là Phản hồi của mô hình (Feedback of model). Khi giáo viên cố gắng giải thích các vướng mắc của sinh viên theo một cách khác, đó được gọi là Tinh chỉnh các tham số (Fine-tuning of parameters). Sinh viên có thể cải thiện việc học bằng cách giải nhiều bài tập hơn nữa (Validation).
Khi đến kỳ thi, sinh viên sẽ không thể nhận được sự trợ giúp nào, dù họ đã học được gì, họ cần sử dụng nó để giải quyết những câu hỏi trong bài kiểm tra (Test). Và kết quả sinh viên nhận được sẽ là sự xác nhận chính xác nhất về việc học sinh đó đã học tốt như thế nào.

Ứng dụng phổ biến của data splitting
Các cách sử dụng data splitting phổ biến bao gồm:
Mô hình dữ liệu (Data modeling)
Trong mô hình dữ liệu, data splitting được sử dụng để đào tạo mô hình. Ví dụ như trong mô hình thử nghiệm hồi quy (regression testing modeling), nhà phát triển sử dụng mô hình để dự đoán phản ứng của hệ thống khi được vận hành với các giá trị tạo sẵn. Trong bộ giá trị ấy, nhà phát triển sẽ chọn ra một phần dữ liệu để làm dữ liệu huấn luyện. Sau đó, họ sẽ so sánh những kết quả đó với dữ liệu thử nghiệm giúp xác định độ chính xác của mô hình hồi quy.
Học máy (Machine learning)
Học máy cũng sử dụng data splitting để đào tạo các mô hình. Dữ liệu huấn luyện được thêm vào mô hình nhằm cập nhật các tham số đào tạo của nó. Sau khi huấn luyện kết thúc, dữ liệu từ tập thử nghiệm sẽ được đo lường dựa trên cách mô hình xử lý các quan sát mới.
Tách mật mã (Cryptographic splitting)
Tách mật mã là một quá trình khác với những trường hợp sử dụng data splitting ở trên. Nó là một kỹ thuật được sử dụng với mục tiêu bảo mật dữ liệu mạng máy tính. Việc phân tách mật mã nhằm bảo vệ hệ thống khỏi các vi phạm bảo mật thông qua mã hóa dữ liệu, chia dữ liệu được mã hóa thành các phần nhỏ và lưu trữ các phần đó tại những vị trí khác nhau.
Data splitting trong học máy
Trong học máy, việc chia nhỏ dữ liệu thường được thực hiện để tránh hiện tượng quá khớp (Overfitting). Overfitting là trường hợp một mô hình máy học đạt độ chính xác quá cap với tập dữ liệu đào tạo trước đó, dẫn đến không thể khớp với các dữ liệu bổ sung.
Dữ liệu gốc trong mô hình Machine learning thường được chia thành 3 hoặc 4 tập. 3 tập thường được sử dụng là tập huấn luyện, tập tối ưu và tập thử nghiệm:
- Tập huấn luyện là phần dữ liệu được sử dụng để huấn luyện mô hình. Mô hình sẽ quan sát và học hỏi từ tập huấn luyện, tối ưu hóa bất kỳ tham số nào của nó.
- Tập tối ưu là tập dữ liệu gồm các ví dụ được sử dụng để thay đổi các tham số của quá trình học. Nó còn được gọi là bộ xác thực chéo hoặc xác thực mô hình. Bộ dữ liệu này có mục đích là xếp hạng độ chính xác của mô hình và có thể hỗ trợ việc lựa chọn mô hình.
- Tập thử nghiệm là phần dữ liệu được kiểm chứng trong mô hình cuối cùng và được so sánh với các bộ dữ liệu trước đó. Tập thử nghiệm đóng vai trò đánh giá chế độ và thuật toán cuối cùng.
Nhìn chung, Data splitting là điều cần thiết để đánh giá khách quan về hiệu suất dự đoán. Hy vọng bài viết đã cung cấp thông tin hữu ích về Data splitting và cách chọ tỷ lệ phân tách dữ liệu phù hợp. Truy cập Meey Land để tìm đọc nhưng khái niệm khác về thế giới công nghê đầy lý thú!