Named Entity Recognition (NER) là gì? Khái niệm, Cách hoạt động và Công dụng
BÀI LIÊN QUAN
Machine-To-Machine (M2M) là gì? Vai trò quan trọng của nó trong doanh nghiệpMachine Learning là gì? Cách học máy thay đổi thế giớiVirtual machine là gì? Một số loại Virtual machine được sử dụng phổ biến hiện nayNamed Entity Recognition (NER) là gì?
Nhận dạng thực thể có tên, tiếng Anh là Named Entity Recognition, viết tắt là NER. Hay còn được gọi là nhận dạng thực thể hoặc trích xuất thực thể.
Named Entity Recognition là một kỹ thuật phân nhánh của xử lý ngôn ngữ tự nhiên - Named entity recognition (NLP). NER tự động xác định các thực thể được đặt tên trong văn bản và phân loại chúng thành những danh mục được xác định trước. Các thực thể có thể là tên của người, tổ chức, vị trí, thời gian, số lượng, giá trị tiền tệ, tỷ lệ phần trăm, v.v.
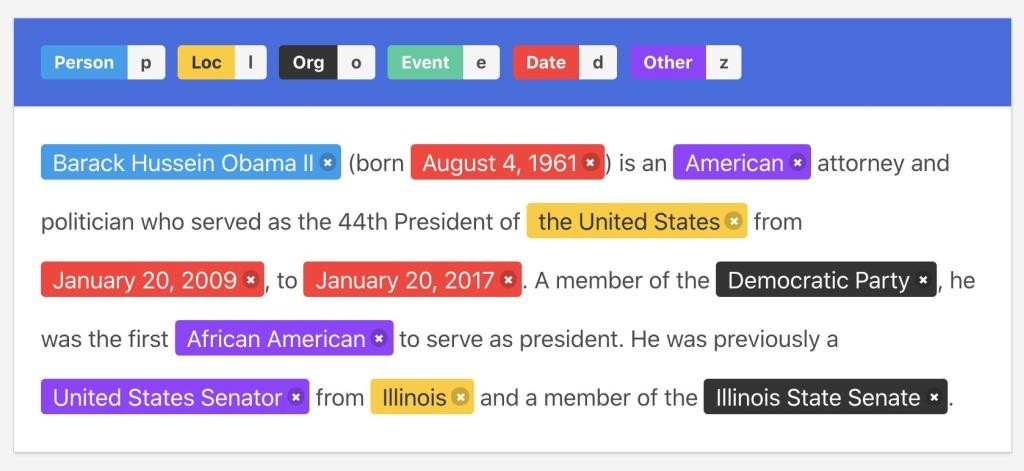
Named Entity Recognition (NER) hoạt động như thế nào?
Khi đọc một văn bản, khả năng tự nhiên của con người là có thể nhận ra các thực thể có tên như con người, giá trị, vị trí, v.v. Ví dụ, trong câu “Mark Zuckerberg là một trong những người sáng lập Facebook, công ty đến từ Hoa Kỳ”, chúng ta có thể dễ dàng xác định ba loại thực thể:
- “Người”: Mark Zuckerberg
- “Công ty”: Facebook
- “Vị trí”: Hoa Kỳ
Tuy nhiên, đối với máy tính, việc trước tiên là chúng ta cần giúp chúng nhận ra các thực thể để có thể phân loại chúng. Điều này được thực hiện thông qua Học máy (Machine learning) và Xử lý ngôn ngữ tự nhiên (NLP).
Trong đó, NLP nghiên cứu cấu trúc và quy tắc của ngôn ngữ (cú pháp) và tạo ra các hệ thống thông minh có khả năng rút ra ý nghĩa từ văn bản và lời nói, trong khi học máy giúp máy học và cải thiện theo thời gian.
Để tìm hiểu thực thể là gì, mô hình NER cần có khả năng phát hiện một từ hoặc chuỗi từ tạo thành một thực thể (ví dụ: Thành phố New York) và biết nó thuộc về loại thực thể nào.
Vì vậy, trước tiên, chúng ta cần tạo các danh mục thực thể, như Tên, Vị trí, Sự kiện, Tổ chức , v.v. và cung cấp dữ liệu đào tạo phù hợp với mô hình NER. Sau đó, bằng cách gắn thẻ một số mẫu từ và cụm từ với các thực thể tương ứng của chúng, cuối cùng bạn sẽ dạy cho mô hình NER đó cách phát hiện chính các thực thể.
Các phương pháp tiếp cận Named Entity Recognition (NER)
Nhận dạng thực thể có tên xác định và định vị các thực thể trong văn bản có cấu trúc và phi cấu trúc.
Yếu tố ngữ nghĩa của NLP, chiết xuất ý nghĩa của từ, câu và các mối quan hệ của chúng, phụ thuộc rất nhiều vào NER. Hai cách tiếp cận NER phổ biến nhất là:
NER dựa trên Ontologies
NER trước đây phụ thuộc rất nhiều vào cơ sở kiến thức. Cơ sở tri thức này được gọi là bản thể luận, là một tập hợp các tập dữ liệu chứa các từ, khái niệm và mối quan hệ qua lại của chúng. Kết quả của NER có thể rất rộng hoặc theo chủ đề cụ thể, tùy thuộc vào mức độ chuyên sâu của Ontology.
Ví dụ, để thu thập và sắp xếp tất cả dữ liệu, Wikipedia sẽ yêu cầu một Ontology cấp rất cao.
NER đặc biệt tốt trong việc xác định các cụm từ và khái niệm nổi tiếng trong các văn bản không cấu trúc hoặc bán cấu trúc, mặc dù NER phụ thuộc rất nhiều vào các phiên bản cập nhật. Nếu không được cập nhật, nó sẽ không thể theo kịp lượng thông tin đang ngày càng tăng.
NER Deep learning
Một ưu điểm đáng kể của Named Entity Recognition (NER) là tính năng học sâu (Deep Learning).
Học sâu có thể phân biệt các thuật ngữ và khái niệm không tồn tại trong Ontology. Nó có thể tự học và đánh giá cả các thuật ngữ cấp cao và cụ thể theo chủ đề. Do đó, NER có thể được sử dụng cho một loạt các ứng dụng trong học sâu.
Ví dụ, các nhà nghiên cứu có thể tận dụng thời gian tốt hơn vì học sâu xử lý phần lớn các nhiệm vụ lặp đi lặp lại. Họ sẽ có thể dành nhiều thời gian hơn để nghiên cứu.
Một số thuật toán học sâu cho NER hiện đã có sẵn. Tuy nhiên, do sự cạnh tranh của thị trường và những đổi mới liên tục, việc xác định sản phẩm tốt nhất trên thị trường là một thách thức.

Named Entity Recognition (NER) được sử dụng để làm gì?
Nhận dạng thực thể có tên (NER) giúp bạn xác định các yếu tố chính trong văn bản một cách dễ dàng, như tên người, địa điểm, thương hiệu, giá trị tiền tệ, v.v. Việc trích xuất các thực thể chính trong văn bản giúp sắp xếp dữ liệu phi cấu trúc và phát hiện thông tin quan trọng, điều này rất quan trọng nếu bạn phải xử lý các tập dữ liệu lớn.
Dưới đây là một số trường hợp sử dụng thú vị của Named Entity Recognition (NER):
Nhận thông tin chi tiết từ phản hồi của khách hàng
Đánh giá trực tuyến là nguồn phản hồi tuyệt vời của khách hàng: chúng có thể cung cấp thông tin chi tiết phong phú về những gì khách hàng thích và không thích về sản phẩm cũng như các khía cạnh cần cải thiện của doanh nghiệp.
Hệ thống Named Entity Recognition (NER) có thể được sử dụng để sắp xếp tất cả các phản hồi của khách hàng này và xác định các vấn đề lặp lại. Ví dụ: bạn có thể sử dụng NER để phát hiện Hệ thống các khiếu nại, thắc mắc và phản hồi từ khách hàng dựa trên các thông tin quan trọng như tên sản phẩm, vị trí chi nhánh, thông số kỹ thuật, v.v. Khiếu nại hoặc phản hồi được phân loại và chuyển đến đúng bộ phận bằng cách lọc các từ khóa ưu tiên. Điều này có thể giúp bạn khoanh vùng được phần cụ thể để nhanh chóng chỉnh sửa.
Đề xuất nội dung
Nhiều ứng dụng hiện đại (như Netflix và YouTube) dựa vào hệ thống đề xuất để tạo ra trải nghiệm khách hàng tối ưu. Rất nhiều trong số đó dựa vào tính năng nhận dạng thực thể có tên, có thể đưa ra đề xuất dựa trên lịch sử tìm kiếm của người dùng.
Ví dụ: nếu bạn xem nhiều phim hài trên Netflix, bạn sẽ nhận được nhiều đề xuất hơn về thể loại phim hài kịch.
Xử lý hồ sơ
Các nhà tuyển dụng phải mất nhiều giờ trong ngày để xem xét hồ sơ avf tìm kiếm ứng viên phù hợp. Mỗi sơ yếu lý lịch chứa cùng một loại thông tin, nhưng chúng thường được tổ chức và định dạng khác nhau: đây chính là một ví dụ cơ bản về dữ liệu phi cấu trúc.
Bằng cách sử dụng công cụ nhận dạng thực thể, nhóm tuyển dụng có thể trích xuất ngay lập tức thông tin tương thích nhất về ứng viên, từ thông tin cá nhân (như tên, địa chỉ, số điện thoại, ngày sinh và email), đến dữ liệu liên quan đến đào tạo và kinh nghiệm (như chứng chỉ, bằng cấp, tên công ty, kỹ năng, v.v.).
Ghi nhận các thực thể trong dữ liệu chăm sóc sức khỏe điện tử
Các mô hình NER có thể được sử dụng để tạo ra các hệ thống y tế mạnh mẽ nhận biết được chính xác các triệu chứng trong dữ liệu chăm sóc sức khỏe điện tử của cá nhân và chẩn đoán bệnh dựa trên các triệu chứng đó.
Thuật toán làm việc hiệu quả
Giả sử bạn đang làm việc trên một thuật toán tìm kiếm nội bộ cho một trang web có hàng triệu bài báo. Nếu thuật toán NLP phải tìm kiếm tất cả các thuật ngữ trong hàng triệu bài báo cho mỗi truy vấn tìm kiếm, thì quá trình này sẽ mất nhiều thời gian.
Thay vào đó, quá trình tìm kiếm có thể được đẩy nhanh đáng kể nếu Nhận dạng thực thể có tên được thực hiện một lần trên tất cả các bài báo và các thực thể (thẻ) có liên quan được liên kết với mỗi bài viết đó được lưu giữ riêng biệt.
Cụm từ tìm kiếm sẽ được so khớp với chỉ một tập hợp ngắn các thực thể được đề cập trong mỗi bài viết bằng cách sử dụng phương pháp này, dẫn đến việc thực hiện tìm kiếm nhanh hơn.
Tài liệu nghiên cứu
Tách các giấy tờ theo các chủ thể quan trọng có thể tiết kiệm thời gian chọn lọc thông tin phong phú về vấn đề này.
Với số lượng lớn dữ liệu được tạo ra bởi mạng xã hội, email, blog, tin tức và các ấn phẩm nghiên cứu, việc trích xuất, phân loại và học hỏi từ dữ liệu đó ngày càng trở nên khó khăn và cần thiết.

Cách sử dụng Named Entity Recognition (NER)
Cách dễ nhất để bắt đầu với tính năng nhận dạng thực thể có tên là sử dụng API. Về cơ bản, bạn có thể chọn giữa hai loại:
- Các API nhận dạng thực thể có tên mã nguồn mở
- Các API nhận dạng thực thể có tên SaaS
Các API nhận dạng thực thể có tên Nguồn mở
Các API nguồn mở dành cho các nhà phát triển: chúng miễn phí, linh hoạt và khá dễ để học cách sử dụng. Dưới đây là một số tùy chọn:
- Stanford Named Entity Recognizer (SNER): công cụ JAVA này được phát triển bởi Đại học Stanford được coi là thư viện tiêu chuẩn để trích xuất thực thể. Nó dựa trên Trường ngẫu nhiên có điều kiện (CRF) và cung cấp các mô hình được đào tạo trước để trích xuất người, tổ chức, vị trí và các thực thể khác.
- SpaCy: một framework Python được biết đến với tốc độ nhanh và rất dễ sử dụng. Nó có một hệ thống thống kê tuyệt vời mà bạn có thể sử dụng để xây dựng các trình trích xuất NER tùy chỉnh.
- Bộ công cụ ngôn ngữ tự nhiên (NLTK): bộ thư viện dành cho Python này được sử dụng rộng rãi cho các tác vụ NLP. NLKT có bộ phân loại riêng để nhận ra các thực thể có tên gọi là ne_chunk, nhưng cũng cung cấp một trình bao bọc để sử dụng trình gắn thẻ Stanford NER trong Python.
*Python là một ngôn ngữ lập trình bậc cao dành cho các mục đích lập trình đa năng
Các API nhận dạng thực thể có tên SaaS
Các công cụ SaaS là các giải pháp ít mã và hiệu quả về chi phí. Thêm vào đó, chúng dễ dàng tích hợp với các nền tảng phổ biến khác.
Ví dụ, MonkeyLearn là một nền tảng SaaS phân tích văn bản mà bạn có thể sử dụng cho các nhiệm vụ NLP khác nhau, một trong số đó là NER. Bạn có thể sử dụng API được xây dựng sẵn của MonkeyLearn để tích hợp các mô hình nhận dạng thực thể được đào tạo trước hoặc bạn có thể dễ dàng xây dựng trình nhận dạng thực thể có tên tùy chỉnh của riêng mình chỉ trong một vài bước đơn giản.
Tóm lại
Các công ty có thể sử dụng tính năng Named Entity Recognition (NER) để gắn nhãn dữ liệu có liên quan trong hỗ trợ khách hàng, phát hiện các thực thể được đề cập trong phản hồi của khách hàng và dễ dàng trích xuất thông tin quan trọng, như thông tin liên hệ, vị trí, ngày tháng và những thứ khác… Hy vọng bài viết đã cung cấp cho các bạn những kiến thức hữu ích về công nghệ học. Theo dõi Meey Land để tìm hiểu kiến thức chuyên sâu hơn về lĩnh vực còn nhiều bí ẩn này.