Data reduction là gì? Những phương pháp thực hiện data reduction
BÀI LIÊN QUAN
Data recovery agent (DRA) là gì? Data recovery agent hoạt động như thế nào?Data Residency là gì? Tại sao doanh nghiệp nên quan tâm?Data Recovery là gì? Những phần mềm giúp khôi phục dữ liệu miễn phí hiệu quả nhấtData reduction là gì?
Data reduction hay giảm dữ liệu là quá trình giảm dung lượng cần thiết để lưu trữ dữ liệu. Giảm dữ liệu có thể tăng hiệu quả lưu trữ và giảm chi phí. Các nhà cung cấp dịch vụ lưu trữ thường mô tả dung lượng lưu trữ dưới dạng dung lượng thô và dung lượng hiệu quả, tức là dữ liệu sau khi giảm.
Giảm dữ liệu có thể đạt được bằng một số cách khác nhau. Các loại chính là sao chép dữ liệu, nén và lưu trữ một phiên bản copy. Chống trùng lặp dữ liệu, còn được gọi là sao chép dữ liệu, loại bỏ các phân đoạn dữ liệu dư thừa trên hệ thống lưu trữ. Nó chỉ lưu trữ các phân đoạn dư thừa một lần và sử dụng một bản sao đó bất cứ khi nào có yêu cầu truy cập vào phần dữ liệu đó.
Loại bỏ dữ liệu chi tiết hơn so với lưu trữ một phiên bản. Lưu trữ một phiên bản tìm các tệp như tệp đính kèm email được gửi cho nhiều người và chỉ lưu trữ một bản sao của tệp đó. Hệ thống lưu trữ một phiên bản thay thế các bản sao bằng các con trỏ tới một bản sao đã lưu.
Một số mảng lưu trữ theo dõi khối nào được chia sẻ nhiều nhất. Những khối được chia sẻ bởi số lượng tệp lớn nhất có thể được chuyển sang bộ nhớ cache dựa trên bộ nhớ flash để chúng có thể được đọc hiệu quả nhất có thể.

Nén dữ liệu cũng hoạt động ở cấp độ tệp. Nó được thực hiện tự nhiên trong các hệ thống lưu trữ bằng cách sử dụng các thuật toán hoặc công thức được thiết kế để xác định và loại bỏ các bit dữ liệu dư thừa. Nén dữ liệu đề cập cụ thể đến phương pháp giảm dữ liệu theo đó các tệp được thu nhỏ ở cấp độ bit. Quá trình nén hoạt động bằng cách sử dụng các công thức hoặc thuật toán để giảm số lượng bit cần thiết để biểu diễn dữ liệu. Điều này thường được thực hiện bằng cách biểu diễn một chuỗi bit lặp lại bằng một chuỗi bit nhỏ hơn và sử dụng từ điển để chuyển đổi giữa chúng.
Lợi ích của việc data reduction
Lợi ích chính của việc giảm dữ liệu khá đơn giản: Bạn càng có thể chứa nhiều dữ liệu hơn trong một terabyte dung lượng ổ đĩa, thì bạn càng cần mua ít dung lượng hơn. Giảm dữ liệu có thể:
- Tiết kiệm năng lượng
- Giảm chi phí lưu trữ vật lý của bạn
- Giảm dấu vết từ trung tâm dữ liệu của bạn
Giảm dữ liệu làm tăng đáng kể hiệu quả của hệ thống lưu trữ và tác động trực tiếp đến tổng mức chi tiêu của người dùng cho dung lượng.
Phương pháp data reduction
Dưới đây là những phương pháp data reduction
Tổng hợp khối dữ liệu
Kỹ thuật này được sử dụng để tổng hợp dữ liệu ở dạng đơn giản hơn. Ví dụ: hãy tưởng tượng thông tin bạn thu thập để phân tích trong các năm 2012 đến 2014, dữ liệu đó bao gồm doanh thu của công ty bạn ba tháng một lần. Chúng liên quan đến doanh số hàng năm của bạn, thay vì trung bình hàng quý. Vì vậy, chúng tôi có thể tóm tắt dữ liệu theo cách sao cho dữ liệu kết quả tóm tắt tổng doanh số mỗi năm thay vì mỗi quý. Nó tóm tắt dữ liệu.
Giảm kích thước
Bất cứ khi nào chúng tôi bắt gặp bất kỳ dữ liệu nào ít quan trọng, thì chúng tôi sử dụng thuộc tính cần thiết cho phân tích của mình. Nó làm giảm kích thước dữ liệu vì nó loại bỏ các tính năng lỗi thời hoặc dư thừa.
- Lựa chọn chuyển tiếp từng bước: Việc lựa chọn bắt đầu với một tập hợp các thuộc tính trống, sau đó chúng tôi quyết định các thuộc tính gốc tốt nhất trên tập hợp dựa trên mức độ liên quan của chúng với các thuộc tính khác. Chúng tôi biết nó như một giá trị p trong thống kê. Giả sử có các thuộc tính sau trong tập dữ liệu trong đó một vài thuộc tính là dư thừa.
- Lựa chọn lùi từng bước: Việc lựa chọn này bắt đầu với một tập hợp các thuộc tính hoàn chỉnh trong dữ liệu gốc và tại mỗi điểm, nó sẽ loại bỏ thuộc tính xấu nhất còn lại trong tập hợp.Giả sử có các thuộc tính sau trong tập dữ liệu trong đó một vài thuộc tính là dư thừa.
- Kết hợp chuyển tiếp và lựa chọn ngược: Nó cho phép loại bỏ những điều tồi tệ nhất và chọn những thuộc tính tốt nhất, tiết kiệm thời gian và làm cho quá trình này nhanh hơn.

Nén dữ liệu
Nén dữ liệu sử dụng sửa đổi, mã hóa hoặc chuyển đổi cấu trúc dữ liệu theo cách tiêu tốn ít dung lượng hơn. Nén dữ liệu liên quan đến việc xây dựng một cách trình bày, biểu diễn thông tin nhỏ gọn bằng cách loại bỏ các tiểu tiết dư thừa và biểu diễn dữ liệu ở dạng nhị phân. Dữ liệu có thể được khôi phục thành công từ dạng nén của nó được gọi là nén nén không mất dữ liệu trong khi ngược lại, nơi không thể khôi phục dạng ban đầu từ dạng nén là nén nén mất dữ liệu.Kỹ thuật nén dữ liệu làm giảm kích thước của tệp bằng cách sử dụng các cơ chế mã hóa khác nhau (Mã hóa Huffman & Mã hóa độ dài chạy). Chúng ta có thể chia nó thành hai loại dựa trên kỹ thuật nén của chúng.
- Nén không mất dữ liệu: Kỹ thuật mã hóa (Run Length Encoding) cho phép giảm kích thước dữ liệu đơn giản và tối thiểu. Nén dữ liệu không mất dữ liệu sử dụng các thuật toán để khôi phục dữ liệu gốc chính xác từ dữ liệu đã nén.
- Nén mất dữ liệu: Các phương pháp như kỹ thuật biến đổi Wavelet, PCA (phân tích thành phần chính) là những ví dụ về kiểu nén này. Ví dụ: định dạng hình ảnh JPEG là định dạng nén mất dữ liệu, nhưng chúng ta có thể nhận thấy ý nghĩa tương đương với hình ảnh gốc. Trong nén mất dữ liệu, dữ liệu được giải nén có thể khác với dữ liệu gốc nhưng đủ hữu ích để lấy thông tin từ chúng.
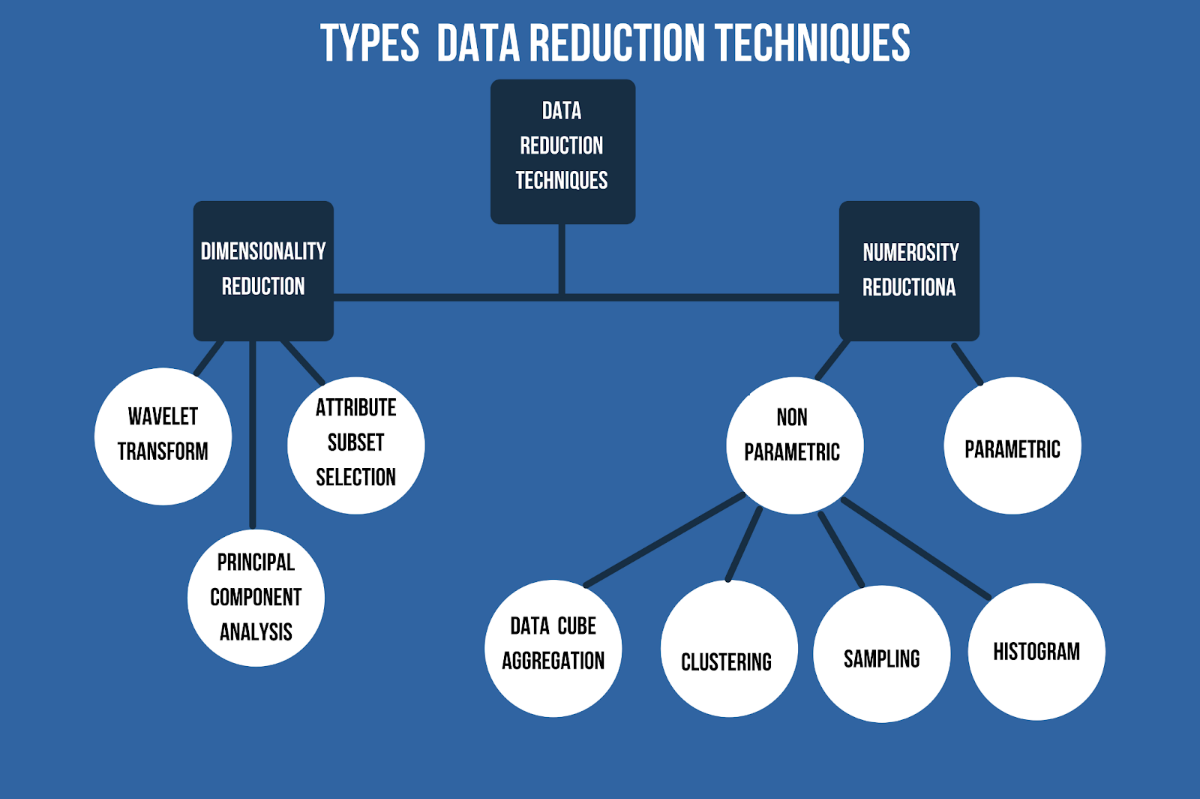
Giảm số lượng
Phương pháp này sử dụng các dạng biểu diễn dữ liệu nhỏ, thay thế, do đó làm giảm khối lượng dữ liệu. Có hai loại Giảm số lượng dữ liệu là Tham số và Phi tham số.
- Tham số
Phương pháp này giả định một mô hình phù hợp với dữ liệu. Các tham số mô hình dữ liệu được ước tính và chỉ những tham số đó được lưu trữ và phần còn lại của dữ liệu sẽ bị loại bỏ. Ví dụ: một mô hình hồi quy có thể được sử dụng để giảm tham số nếu dữ liệu phù hợp với mô hình hồi quy tuyến tính.
Hồi quy tuyến tính mô hình hóa mối quan hệ tuyến tính giữa hai thuộc tính của tập dữ liệu. Giả sử chúng ta cần điều chỉnh mô hình hồi quy tuyến tính giữa hai thuộc tính x và y, trong đó y là thuộc tính phụ thuộc và x là thuộc tính độc lập hoặc thuộc tính dự báo. Mô hình có thể được biểu diễn bằng phương trình y=wx b. Trong đó w và b là các hệ số hồi quy. Mô hình hồi quy tuyến tính bội cho phép chúng ta biểu thị thuộc tính y theo nhiều thuộc tính của yếu tố dự đoán.
Một phương pháp khác, mô hình Log-Linear phát hiện ra mối quan hệ giữa hai hoặc nhiều thuộc tính rời rạc. Giả sử, chúng ta có một tập các bộ trong không gian n chiều; mô hình log-tuyến tính giúp suy ra xác suất của mỗi bộ trong không gian n chiều này.
- Phi tham số
Một kỹ thuật giảm số lượng phi tham số không giả định bất kỳ mô hình nào. Kỹ thuật không tham số dẫn đến việc giảm đồng đều hơn, bất kể kích thước dữ liệu, nhưng nó có thể không đạt được mức giảm khối lượng dữ liệu cao như kỹ thuật Tham số. Có ít nhất năm loại kỹ thuật giảm dữ liệu Phi tham số là Biểu đồ, Phân cụm, Lấy mẫu, Tập hợp khối dữ liệu, Nén dữ liệu.
Kỹ thuật rời rạc hóa & phân cấp khái niệm:
Kỹ thuật rời rạc hóa dữ liệu được sử dụng để phân chia các thuộc tính có tính chất liên tục thành dữ liệu có khoảng cách. Chúng tôi thay thế nhiều giá trị không đổi của các thuộc tính bằng nhãn của các khoảng thời gian nhỏ. Điều này có nghĩa là kết quả khai thác được hiển thị một cách ngắn gọn và dễ hiểu.
- Rời rạc hóa từ trên xuống: Nếu trước tiên bạn xem xét một hoặc một vài điểm (được gọi là điểm dừng hoặc điểm phân tách) để phân chia toàn bộ tập hợp các thuộc tính và lặp lại phương pháp này cho đến hết, thì quá trình này được gọi là phân tách từ trên xuống còn được gọi là phân tách.
- Phân biệt từ dưới lên: Nếu trước tiên bạn coi tất cả các giá trị không đổi là các điểm phân chia, một số sẽ bị loại bỏ thông qua sự kết hợp của các giá trị tương đương hoặc gần giống trong một khoảng dữ liệu, quá trình đó được gọi là rời rạc hóa từ dưới lên.
Lấy mẫu
Lấy mẫu có khả năng giảm tập dữ liệu lớn thành tập dữ liệu mẫu nhỏ hơn, giảm nó thành một phiên bản của tập dữ liệu gốc. Có bốn loại phương pháp Data reduction lấy mẫu như sau:
- Mẫu ngẫu nhiên đơn giản mà không cần thay thế kích thước
- Mẫu ngẫu nhiên đơn giản với thay thế kích thước
- Cụm mẫu
- Mẫu phân tầng
Phân cụm
Trong Phân cụm, tập dữ liệu được thay thế bằng biểu diễn cụm, trong đó dữ liệu được phân chia giữa các cụm tùy thuộc vào sự tương đồng với nhau trong cụm và sự khác biệt với các cụm khác. Càng nhiều điểm giống nhau trong cụm, chúng càng xuất hiện gần nhau hơn trong cụm. Chất lượng của cụm phụ thuộc vào khoảng cách tối đa giữa hai mục dữ liệu bất kỳ trong cụm.
Data reduction hay giảm dữ liệu giúp giảm nhẹ khối lượng, giúp dễ dàng biểu diễn và chạy dữ liệu thông qua những thuật toán phân tích nâng cao. Giảm dữ liệu cũng giúp loại bỏ trùng lặp dữ liệu, giảm giảm tải tối đa cho bộ lưu trữ và cung cấp các thuật toán phục vụ các kỹ thuật khoa học dữ liệu ở hạ lưu. Nó có thể đạt được theo hai cách chính. Bằng cách giảm số lượng bản ghi dữ liệu hoặc các tính năng và cách khác bằng cách tạo dữ liệu tóm tắt và thống kê ở các cấp độ khác nhau, doanh nghiệp sẽ hưởng nhiều lợi ích như giảm chi phí quản lý dữ liệu, không cần mở rộng thường xuyên kho lưu trữ dữ liệu.