Data Lake là gì? 5 khác biệt lớn giữa Data Lake và Data Warehouse
BÀI LIÊN QUAN
Data marketplace là gì? Doanh nghiệp hưởng lợi gì từ thị trường dữ liệu?Data validation là gì? Các loại data validationData Profiling là gì? Các loại hồ sơ dữ liệuData Lake là gì?
Data Lake (tiếng Việt là Hồ dữ liệu) là một kho lưu trữ tập trung được thiết kế cho việc lưu trữ, xử lý và bảo mật số lượng lớn dữ liệu, gồm cả dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc. Hồ dữ liệu có thể lưu trữ dữ liệu ở định dạng gốc, đồng thời xử lý mọi loại dữ liệu khác nhau và không giới hạn kích thước. Khả năng của data lake là cung cấp dữ liệu cao qua đó giúp tăng hiệu suất phân tích và tích hợp gốc.
Data Lake cung cấp một nền tảng an toàn và có thể mở rộng, cho phép các doanh nghiệp: nhập tất cả dữ liệu từ mọi hệ thống ở bất kỳ tốc độ nào; lưu trữ hết loại và khối lượng dữ liệu với độ tin cậy cao; xử lý dữ liệu theo chế độ hàng loạt hoặc theo thời gian thực; phân tích dữ liệu bằng SQL, R, Python hoặc bất kỳ ngôn ngữ nào khác, dữ liệu bên thứ ba hay ứng dụng phân tích.
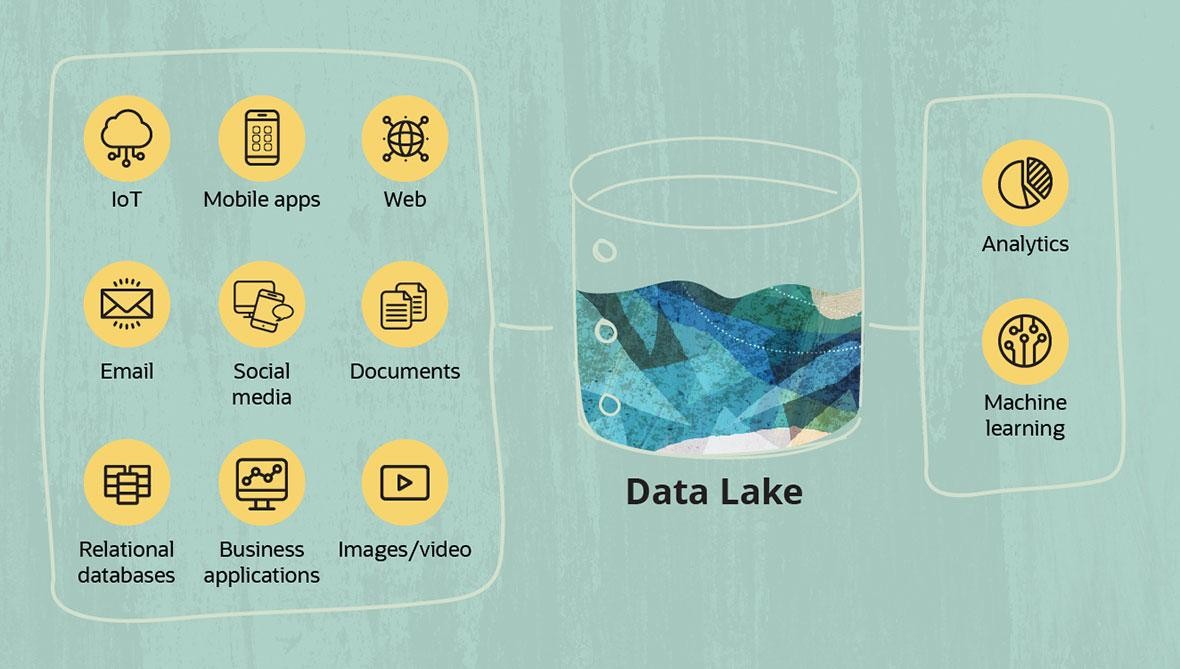
Tại sao data lake lại quan trọng?
Vì Data Lake có thể nhanh chóng nhập tất cả các loại dữ liệu mới nên các doanh nghiệp có thể xem và phản hồi thông tin mới nhanh hơn. Ngoài ra, họ có quyền truy cập vào dữ liệu mà trước đây họ không thể có được.
Ví dụ: Hồ dữ liệu là nguồn dữ liệu phổ biến nhất cho học máy (Machine learning - một kỹ thuật thường được áp dụng cho tệp nhật ký, dữ liệu nhấp chuột từ các trang web, nội dung mạng xã hội, cảm biến phát trực tuyến và dữ liệu phát ra từ các thiết bị kết nối internet khác).
Hồ dữ liệu cung cấp quy mô cần thiết và sự đa dạng của dữ liệu để các doanh nghiệp có thể khám phá, phân tích và báo cáo nâng cao. Nó cũng có thể là điểm hợp nhất cho cả dữ liệu lớn (big data) và dữ liệu truyền thống, cho phép phân tích các mối tương quan trên tất cả dữ liệu.
Mặc dù data lake thường được sử dụng để lưu trữ dữ liệu thô, nó cũng có thể lưu trữ một số dữ liệu trung gian hoặc dữ liệu được biến đổi hoàn toàn, được tái cấu trúc hoặc tổng hợp do data warehouse (kho dữ liệu) và các quy trình hạ nguồn của nó tạo ra. Điều này thường được thực hiện nhằm giảm thời cho các nhiệm vụ chuẩn bị dữ liệu chung.
Cách tiếp cận tương tự đôi khi được sử dụng để che hoặc ẩn thông tin nhận dạng cá nhân (PII) hoặc dữ liệu nhạy cảm không cần thiết cho phân tích khác. Điều này giúp các doanh nghiệp tuân thủ chính sách về quyền riêng tư và bảo mật dữ liệu.
5 khác biệt lớn giữa Data Lake và Data Warehouse

1. Data Lake giữ lại tất cả dữ liệu
Quá trình phát triển kho dữ liệu (data warehouse) tiêu tốn một lượng thời gian đáng kể cho công việc phân tích các nguồn dữ liệu, hiểu các quy trình kinh doanh và lập hồ sơ dữ liệu. Kết quả là một mô hình dữ liệu có cấu trúc cao được thiết kế. Phần lớn quy trình này là việc đưa ra quyết định về dữ liệu nào sẽ được đưa vào và không đưa vào kho. Nói chung, nếu dữ liệu không được sử dụng để trả lời các câu hỏi cụ thể hoặc đã bị xác định, dữ liệu đó có thể bị loại khỏi kho. Điều này được thực hiện nhằm đơn giản hóa mô hình dữ liệu và cũng là để tiết kiệm không gian lưu trữ cho kho dữ liệu hoạt động hiệu quả hơn.
Ngược lại, hồ dữ liệu giữ lại TẤT CẢ dữ liệu. Không chỉ dữ liệu đang được sử dụng mà cả dữ liệu có thể được sử dụng và thậm chí là dữ liệu có thể không bao giờ được sử dụng chỉ vì nó CÓ THỂ được sử dụng vào một ngày nào đó. Dữ liệu cũng được lưu giữ vĩnh viễn để chúng ta có thể phân tích.
Cách tiếp cận này khả thi do phần cứng của hồ dữ liệu thường rất khác so với phần cứng được sử dụng trong kho dữ liệu. Các máy chủ thông dụng, có sẵn kết hợp với dung lượng lưu trữ giá rẻ khiến việc mở rộng data lake lên hàng terabyte và petabyte khá tiết kiệm.
2. Data Lake hỗ trợ tất cả các loại dữ liệu
Data Warehouse thường bao gồm dữ liệu được trích xuất từ các hệ thống giao dịch và các số liệu định lượng cùng các thuộc tính mô tả chúng. Các nguồn dữ liệu phi truyền thống như nhật ký máy chủ web, dữ liệu cảm biến, hoạt động mạng xã hội, văn bản và hình ảnh phần lớn bị bỏ qua. Những cách sử dụng mới cho các loại dữ liệu này tiếp tục được tìm thấy nhưng việc sử dụng và lưu trữ chúng có thể kéo theo sự tốn kém và khó khăn.
Trong khi đó Data Lake gồm các loại dữ liệu phi truyền thống này. Hồ dữ liệu giữ tất cả dữ liệu bất kể nguồn hay cấu trúc. Chúng ta có thể giữ nó ở dạng thô và chỉ chuyển đổi khi cần sử dụng.
3. Data Lake hỗ trợ tất cả người dùng
Trong hầu hết các tổ chức, 80% người dùng trở lên đang “operational”. Họ muốn nhận báo cáo, xem các chỉ số hiệu suất hoặc cắt cùng một tập hợp dữ liệu trong bảng tính mỗi ngày. Kho dữ liệu thường lý tưởng cho những người dùng này vì nó có cấu trúc tốt, dễ sử dụng, dễ hiểu và được xây dựng với mục đích để trả lời các câu hỏi của họ.
10% tiếp theo hoặc hơn, phân tích nhiều hơn về dữ liệu. Họ sử dụng data warehouse làm nguồn nhưng thường vẫn phải quay lại các hệ thống nguồn để lấy dữ liệu không có trong kho và đôi khi lấy dữ liệu từ bên ngoài tổ chức. Công cụ họ hay sử dụng là bảng tính và các báo cáo mới được tạo ra thường được phân phối trong toàn tổ chức. Học coi data warehouse là nguồn cung cấp dữ liệu nhưng vẫn thường vượt ra ngoài giới hạn của nó.
Cuối cùng, một vài phần trăm người dùng còn lại thực hiện phân tích sâu, bao gồm các nhà khoa học dữ liệu. Họ có thể tạo ra các nguồn dữ liệu hoàn toàn mới dựa trên nghiên cứu, kết hợp nhiều loại dữ liệu khác nhau và đưa ra những câu hỏi hoàn toàn mới cần được giải đáp. Những người dùng này có thể sử dụng kho dữ liệu nhưng thường không dùng vì các tác vụ vượt quá khả năng của kho dữ liệu. Họ có thể sử dụng các công cụ và khả năng phân tích nâng cao như phân tích thống kê và lập mô hình dự đoán.
Data Lake hỗ trợ tốt cho tất cả những người dùng này. Các nhà khoa học dữ liệu có thể đến hồ và làm việc với các tập dữ liệu rất lớn và đa dạng mà họ cần trong khi những người dùng khác sử dụng các chế độ xem có cấu trúc hơn của dữ liệu được cung cấp cho mục đích sử dụng của họ.
4. Data Lake dễ dàng thích ứng với các thay đổi
Một trong những phàn nàn chính về kho dữ liệu là tốn thời gian để thay đổi chúng. Một thiết kế nhà kho tốt có thể thích ứng với sự thay đổi nhưng do sự phức tạp của quy trình tải dữ liệu và công việc được thực hiện, những thay đổi này nhất thiết sẽ tiêu tốn lượng tài nguyên đáng kể và mất một khoảng thời gian nhất định. Tuy nhiên các câu hỏi kinh doanh không thể chờ đợi nhóm kho dữ liệu điều chỉnh hệ thống.
Mặt khác, trong hồ dữ liệu, vì tất cả dữ liệu được lưu trữ ở dạng thô và luôn có thể truy cập được, nên người dùng được trao quyền vượt ra ngoài cấu trúc của kho để khám phá dữ liệu theo những cách mới lạ và trả lời câu hỏi của họ, theo tốc độ của họ.
Nếu kết quả khám phá hữu ích và người dùng có mong muốn lặp lại kết quả đó, thì có thể áp dụng lược đồ chính thức hơn cho kết quả đó, đồng thời có thể phát triển khả năng tự động hóa và khả năng sử dụng lại để giúp mở rộng kết quả cho nhiều đối tượng hơn. Nếu kết quả được xác định không hữu ích, nó có thể bị loại bỏ và không có thay đổi nào đối với cấu trúc dữ liệu được thực hiện, cũng như không có tài nguyên nào bị tiêu tốn.
5. Data Lake cung cấp thông tin chi tiết nhanh hơn
Điểm khác biệt cuối cùng cũng có thể nói chính là kết quả của bốn điều còn lại. Bởi Data lake chứa tất cả dữ liệu và loại dữ liệu, đồng thời cho phép người dùng truy cập dữ liệu trước khi dữ liệu được chuyển đổi, làm sạch và cấu trúc nên nó cho phép người dùng đạt được kết quả nhanh hơn so với kho dữ liệu truyền thống.

Nên chọn Data Lake hay Data Warehouse?
Nếu bạn đã có kho dữ liệu được thiết lập tốt thì chắc chắn không nên bắt đầu lại từ đầu. Tuy nhiên, giống như nhiều kho dữ liệu khác, Data Warehouse của bạn có thể gặp phải một số vấn đề được đề cập phía trên. Trong trường hợp này, bạn có thể chọn các triển khai hồ dữ liệu BÊN NGOÀI kho của mình. Kho có thể tiếp tục hoạt động, song song với việc lấp đầy hồ bằng các nguồn dữ liệu mới.
Bạn cũng có thể sử dụng hồ như một kho lưu trữ cho dữ liệu kho để. Khi Data Warehouse cũ đi, bạn có thể cân nhắc chuyển nó sang Data Lake hoặc có thể tiếp tục sử dụng phương pháp kết hợp.
Nếu chỉ mới bắt đầu xây dựng nền tảng dữ liệu tập trung, thì bạn nên xem xét cả hai cách tiếp cận.
Lợi ích và Rủi ro khi sử dụng Data Lake
Lợi ích
- Giúp hoàn thiện quá trình ion hóa sản phẩm và phân tích nâng cao
- Cung cấp khả năng mở rộng hiệu quả về chi phí và tính linh hoạt
- Cung cấp giá trị từ các loại dữ liệu không giới hạn
- Giảm chi phí sở hữu lâu dài
- Cho phép lưu trữ kinh tế các tập tin
- Nhanh chóng thích nghi với những thay đổi
- Tập trung các nguồn nội dung khác nhau
- Người dùng, từ các bộ phận khác nhau, mọi nơi trên thế giới vẫn có thể truy cập linh hoạt vào dữ liệu
Rủi ro
- Sau một thời gian, Data Lake có thể mất đi sự tương thích và động lượng
- Có nhiều rủi ro hơn khi thiết kế Data Lake
- Làm tăng chi phí lưu trữ và tính toán
- Không có cách nào để có được insight từ người đã làm việc với dữ liệu trước đó
- Rủi ro lớn nhất của hồ dữ liệu là bảo mật và kiểm soát truy cập. Đôi khi, dữ liệu có thể được đặt vào hồ mà không có bất kỳ sự giám sát nào.
Các công ty ngày nay đã bắt đầu xem xét giá trị của Data Lake theo một khía cạnh khác - một hồ dữ liệu không chỉ có chức năng lưu trữ dữ liệu có độ tin cậy đầy đủ. Chúng giúp doanh nghiệp hiểu sâu hơn về các tình huống kinh doanh bởi giờ đây, họ có nhiều ngữ cảnh hơn, cho phép họ đẩy nhanh các thử nghiệm phân tích.