Data deduplication ratio là gì? Vai trò của data deduplication ratio trong các hệ thống sao lưu
BÀI LIÊN QUAN
Data center resiliency là gì? Ví dụ về data center resiliencyData center infrastructure management (DCIM) là gì? Lợi ích của DCIM là gì?Data center management là gì? Những thách thức của việc quản lý trung tâm dữ liệuData deduplication ratio là gì?
Data deduplication ratio nghĩa là tỷ lệ chống trùng lặp dữ liệu là phép đo kích thước ban đầu của dữ liệu so với kích thước của dữ liệu sau khi loại bỏ phần dư thừa.
Chống trùng lặp dữ liệu là quá trình loại bỏ dữ liệu dư thừa trước khi sao lưu dữ liệu. Tỷ lệ sao chép dữ liệu đo lường hiệu quả của quá trình sao chép dữ liệu. Nó được tính bằng cách chia tổng dung lượng dữ liệu đã sao lưu trước khi loại bỏ các dữ liệu trùng lặp cho dung lượng thực sử dụng sau khi sao lưu xong. Ví dụ: tỷ lệ chống trùng lặp dữ liệu 5:1 có nghĩa là dữ liệu được bảo vệ gấp năm lần so với không gian vật lý cần thiết để lưu trữ dữ liệu đó.
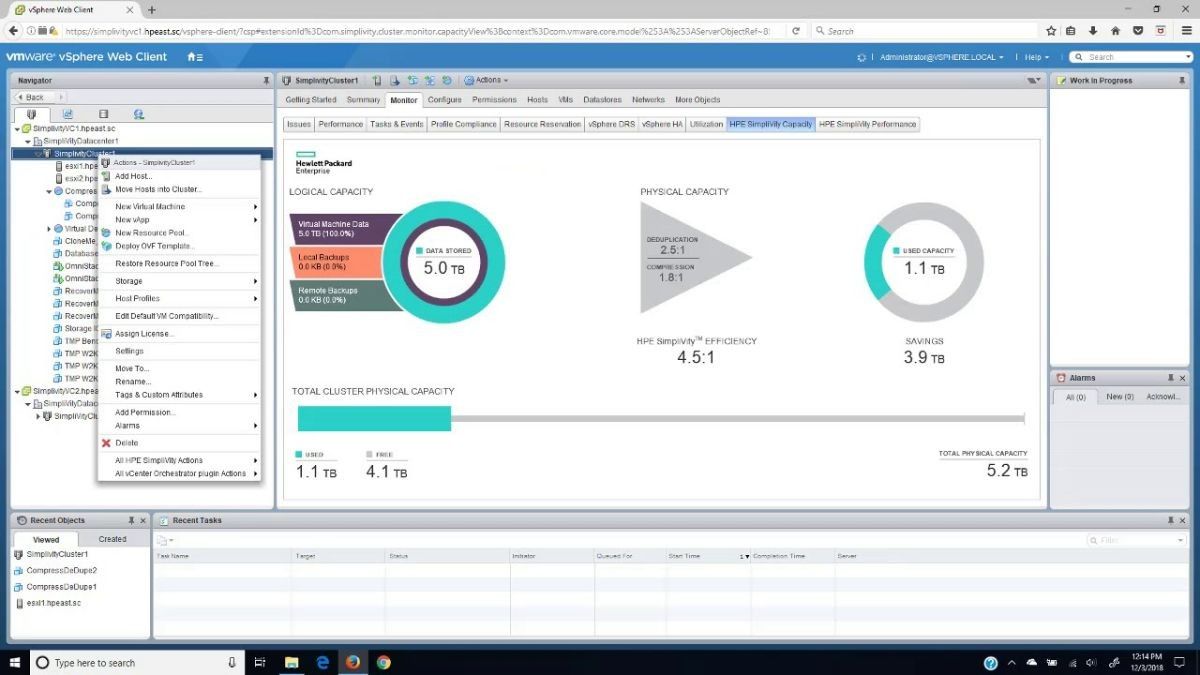
Khi một nhà cung cấp tuyên bố rằng họ có thể đạt được một tỷ lệ chống trùng lặp nhất định, thì con số đó biểu thị một tình huống tốt nhất. Bởi vì tính năng chống trùng lặp hoạt động bằng cách loại bỏ dữ liệu dư thừa, nếu không có dữ liệu dư thừa tồn tại thì việc chống trùng lặp là không thể. Một số loại dữ liệu, chẳng hạn như video MPEG hoặc hình ảnh JPEG, đã được nén và chứa ít dữ liệu dư thừa.
Khi tỷ lệ chống trùng lặp tăng lên, quá trình loại bỏ trùng lặp tạo ra lợi nhuận tương đối yếu hơn. Tỷ lệ 100:1 loại bỏ 99% dữ liệu. Việc tăng tỷ lệ lên 500:1, giúp loại bỏ 99,8% dữ liệu, sẽ không làm giảm nhiều dữ liệu hơn vì phần lớn dữ liệu dư thừa đã bị loại bỏ.
- Một số yếu tố ảnh hưởng đến tỷ lệ sao chép dữ liệu, bao gồm:
- Lưu giữ dữ liệu -- Dữ liệu được lưu giữ càng lâu thì khả năng tìm thấy sự dư thừa càng lớn
- Loại dữ liệu -- Ví dụ: một môi trường chủ yếu có máy chủ Windows và các tệp tương tự sẽ có thể tạo ra tỷ lệ cao hơn
- Tỷ lệ thay đổi -- Tỷ lệ thay đổi dữ liệu cao thường mang lại tỷ lệ chống trùng lặp thấp
- Vị trí -- Phạm vi càng rộng thì khả năng tìm thấy trùng lặp càng cao. Chống trùng lặp toàn cầu, so sánh dữ liệu trên nhiều hệ thống, thường sẽ tạo ra mức giảm nhiều hơn so với dữ liệu được sao chép cục bộ trên một thiết bị
Môi trường máy chủ ảo thường mang lại tỷ lệ chống trùng lặp tốt nhất, bởi vì rất nhiều dữ liệu giữa các máy ảo là dư thừa. Cơ sở dữ liệu có cấu trúc thường tạo ra tỷ lệ chống trùng lặp kém.
Phân đoạn biến có hiệu quả trong việc nhận dạng dữ liệu trùng lặp và tăng tỷ lệ chống trùng lặp dữ liệu thông qua khả năng khớp dữ liệu nhỏ hơn dễ dàng và nhanh chóng hơn. Mặt khác, phần mềm bảo vệ dữ liệu cũ chỉ loại trừ dữ liệu trên một luồng dữ liệu duy nhất dẫn đến tỷ lệ loại trừ thấp hơn và tăng chi phí bảo vệ dữ liệu.
Các yếu tố có thể ảnh hưởng đến data deduplication ratio
Một số yếu tố ảnh hưởng đến tỷ lệ sao chép, bao gồm:
- Chính sách sao lưu dữ liệu: tần suất sao lưu "đầy đủ" (so với sao lưu "gia tăng" hoặc "vi sai" càng lớn), khả năng chống trùng lặp càng cao do dữ liệu sẽ dư thừa hàng ngày.
- Cài đặt lưu giữ dữ liệu: dữ liệu được lưu giữ trên đĩa càng lâu thì càng có nhiều cơ hội để công cụ chống trùng lặp tìm thấy sự dư thừa.
- Loại dữ liệu: một số dữ liệu vốn dễ bị trùng lặp hơn những dữ liệu khác. Sẽ hợp lý hơn khi mong đợi tỷ lệ chống trùng lặp cao hơn nếu môi trường chủ yếu chứa các máy chủ Windows có tệp tương tự hoặc máy ảo VMware.
- Tỷ lệ thay đổi: tỷ lệ thay đổi càng nhỏ thì khả năng tìm thấy dữ liệu trùng lặp càng cao.
- Miền chống trùng lặp: phạm vi của quy trình kiểm tra và so sánh càng rộng thì khả năng phát hiện trùng lặp càng cao. Chống trùng lặp cục bộ đề cập đến việc kiểm tra sự dư thừa tại tài nguyên cục bộ, trong khi chống trùng lặp toàn cầu đề cập đến việc kiểm tra dữ liệu trên nhiều nguồn để xác định vị trí và loại bỏ các bản sao. Ví dụ: một bản sao lưu toàn bộ dữ liệu thay đổi hàng ngày với tỷ lệ 1% hoặc ít hơn được giữ lại cho 30 bản sao lưu có 99% trong mỗi bản sao lưu được sao chép. Sau 30 ngày, tỷ lệ có thể đạt 30:1. Mặt khác, nếu các bản sao lưu hàng tuần được giữ lại trong một tháng, thì tỷ lệ sẽ chỉ đạt 4:1.
Tỷ lệ sao chép có thể gây nhầm lẫn. Một số nhà cung cấp thể hiện mức giảm dưới dạng phần trăm tiết kiệm thay vì tỷ lệ. Nếu nhà cung cấp tiết kiệm được 50% dung lượng, thì điều đó tương đương với tỷ lệ chống trùng lặp 2:1. Tỷ lệ 10:1 tương đương với 90% tiết kiệm. Điều đó có nghĩa là 10 TB dữ liệu có thể được sao lưu thành 1 TB dung lượng lưu trữ vật lý. Tỷ lệ 20:1 chỉ làm tăng khoản tiết kiệm thêm 5% (đến 95%).
Đánh giá tỷ lệ chống trùng lặp dữ liệu
Khi đánh giá chống trùng lặp dữ liệu, điều quan trọng là phải dùng thử các sản phẩm của nhà cung cấp trong môi trường của bạn với dữ liệu của chính bạn qua nhiều chu kỳ sao lưu để xác định tác động của sản phẩm đối với môi trường sao lưu/phục hồi của bạn. Trọng tâm của việc lựa chọn một sản phẩm nên ít hơn về tỷ lệ giảm như một yếu tố quyết định. Nghiên cứu về ESG (Báo cáo nghiên cứu ESG, "Xu hướng thị trường bảo vệ dữ liệu", tháng 1 năm 2008) cho thấy, không có gì ngạc nhiên khi chi phí của giải pháp chống trùng lặp là yếu tố được trích dẫn thường xuyên nhất (mặc dù khoản tiết kiệm thu được từ việc giảm dung lượng thường khắc phục được vấn đề liên quan đến thâm hụt tài chính đối với việc triển khai chống trùng lặp) . Mặt khác, dữ liệu khảo sát cho thấy rằng tính dễ triển khai và tính dễ sử dụng, cũng như tác động đối với hiệu suất sao lưu/phục hồi là những cân nhắc quan trọng - hơn cả các triển khai kỹ thuật, chẳng hạn như tỷ lệ chống trùng lặp.
Các phương pháp/loại phương pháp nâng cao tỷ lệ chống trùng lặp dữ liệu là gì?
Dưới đây là những phương pháp để nâng cao tỷ lệ chống trùng lặp dữ liệu hiệu quả nhất mà các doanh nghiệp, tổ chức có thể thực hiện:
Chống trùng lặp nội tuyến
Khi dữ liệu được ghi vào bộ lưu trữ, Inline Deduplication xảy ra. Công cụ chống trùng lặp gắn thẻ dữ liệu dần dần trong khi nó đang chuyển động. Mặc dù phương pháp này hiệu quả, nhưng nó dẫn đến chi phí tính toán bổ sung. Hệ thống phải gắn thẻ dữ liệu đến một cách thường xuyên và sau đó nhanh chóng xác định xem dấu vân tay mới đó có khớp với bất kỳ thứ gì trong hệ thống hay không. Một cờ trỏ đến thẻ hiện có được viết nếu trường hợp này xảy ra. Nếu không, khối sẽ được giữ nguyên. Chống trùng lặp nội tuyến là một tính năng phổ biến trên nhiều hệ thống lưu trữ và mặc dù tính năng này có thêm chi phí hoạt động, nhưng điều đó không quá tệ vì lợi ích lớn hơn chi phí.
Chống trùng lặp hậu xử lý
Khi tất cả dữ liệu được ghi hoàn chỉnh, Chống trùng lặp sau quá trình, còn được gọi là Chống trùng lặp không đồng bộ, sẽ xảy ra. Hệ thống chống trùng lặp chạy qua và gắn thẻ tất cả dữ liệu mới sẽ loại bỏ nhiều bản sao và thay thế chúng bằng các cờ trỏ đến bản sao dữ liệu gốc theo các khoảng thời gian đều đặn. Các doanh nghiệp có thể sử dụng dịch vụ Giảm thiểu dữ liệu của họ mà không phải lo lắng về chi phí xử lý lặp đi lặp lại do Chống trùng lặp nội tuyến tạo ra khi sử dụng Chống trùng lặp sau xử lý. Phương pháp này cho phép các tổ chức lên lịch Chống trùng lặp để nó có thể diễn ra ngoài giờ làm việc.
Nhược điểm đáng kể nhất của Chống trùng lặp sau xử lý là tất cả dữ liệu được lưu trữ ở dạng nguyên vẹn (thường được gọi là ngậm nước hoàn toàn). Do đó, dữ liệu chiếm cùng dung lượng với dữ liệu không trùng lặp. Việc giảm kích thước chỉ xảy ra khi thao tác Chống trùng lặp theo lịch trình đã hoàn tất. Các doanh nghiệp sử dụng tính năng sao chép sau xử lý phải luôn có dung lượng lưu trữ lớn hơn.
Sao chép nguồn
Trước khi gửi dữ liệu đến mục tiêu sao lưu, Chống trùng lặp dựa trên nguồn sẽ loại bỏ các khối dư thừa ở cấp độ máy khách hoặc máy chủ. Không cần thêm bất kỳ thiết bị nào. Loại bỏ trùng lặp dữ liệu tại nguồn giúp tiết kiệm thời gian và không gian.
Chống trùng lặp mục tiêu
Các bản sao lưu được gửi qua mạng tới phần cứng dựa trên đĩa có ở một vị trí từ xa với Chống trùng lặp dựa trên mục tiêu. Các mục tiêu chống trùng lặp làm tăng chi phí, nhưng chúng thường mang lại lợi thế về hiệu suất so với chống trùng lặp nguồn, đặc biệt đối với các tập dữ liệu quy mô petabyte.
Chống trùng lặp phía máy khách
Chống trùng lặp dữ liệu phía máy khách là một kỹ thuật Chống trùng lặp dữ liệu được sử dụng trên máy khách lưu trữ dự phòng. Ví dụ: để loại bỏ dữ liệu dư thừa trong quá trình sao lưu và lưu trữ trước khi dữ liệu được gửi đến máy chủ. Có thể giảm lượng dữ liệu được phân phối qua mạng cục bộ bằng cách sử dụng tính năng Chống trùng lặp dữ liệu phía máy khách.
Tại sao chống trùng lặp dữ liệu lại quan trọng?
Chống trùng lặp dữ liệu rất quan trọng vì nó giảm đáng kể nhu cầu về dung lượng lưu trữ của bạn, giúp các doanh nghiệp có thể tiết kiệm tiền và giảm lượng băng thông bị lãng phí khi truyền dữ liệu đến/từ các vị trí lưu trữ từ xa. Trong một số trường hợp, chống trùng lặp dữ liệu có thể giảm tới 95% yêu cầu lưu trữ, mặc dù các yếu tố như loại dữ liệu bạn đang cố gắng chống trùng lặp sẽ ảnh hưởng đến tỷ lệ chống trùng lặp cụ thể của bạn. Ngay cả khi các yêu cầu lưu trữ của bạn giảm xuống dưới 95%, việc sao chép dữ liệu vẫn có thể giúp tiết kiệm rất nhiều và tăng đáng kể khả năng sử dụng băng thông của bạn.
Đánh giá data deduplication ratio chính xác sẽ giúp các doanh nghiệp có thể hiểu được dữ liệu đang ở tình trạng như thế nào, từ đó đưa ra quyết định chính xác nhất. Chính vì thế việc sử dụng, khai thác và đánh giá chính xác tỷ lệ chống trùng lặp dữ liệu là điều hết sức quan trọng.