Lemmatization là gì? Sự khác biệt chính giữa stemming và lemmatization
BÀI LIÊN QUAN
Internet of Things (IoT) là gì? Những ứng dụng quan trọng của IoT trong cuộc sốngMột số ví dụ về Internet of Things trong thực tếBạn đã biết điểm mạnh và điểm yếu của Internet of things chưa?Lemmatization là gì?
Lemmatization là Bổ đề trong ngôn ngữ học các hình thức khác nhau của cùng một từ. Trong truy vấn tìm kiếm, từ vựng cho phép người dùng cuối truy vấn bất kỳ phiên bản nào của từ cơ sở và nhận kết quả có liên quan. Bởi vì các thuật toán của công cụ tìm kiếm sử dụng từ vựng, người dùng có thể tự do truy vấn bất kỳ dạng biến tố nào của một từ và nhận được các kết quả có liên quan. Ví dụ: nếu người dùng truy vấn dạng số nhiều của một từ (ví dụ: bộ định tuyến), công cụ tìm kiếm cũng biết trả về nội dung có liên quan sử dụng dạng số ít của cùng một từ (bộ định tuyến).
Bổ đề trong ngôn ngữ học hóa là một khía cạnh quan trọng của hiểu ngôn ngữ tự nhiên (NLU) và xử lý ngôn ngữ tự nhiên (NLP) và đóng vai trò quan trọng trong phân tích dữ liệu lớn và trí tuệ nhân tạo (AI). Các thuật toán phức tạp sử dụng các quy tắc của hình thái ngôn ngữ, trong ngữ cảnh với từ vựng của một ngôn ngữ cụ thể, để nhóm các từ được sử dụng trong lời nói và văn bản theo các hình thức biến cách. Học sâu được sử dụng để phân tích và hiểu các nhóm, vì vậy khi bất kỳ dạng biến tố nào của một từ được đề cập, toàn bộ từ vựng cơ bản của thuật ngữ cơ sở sẽ được bao gồm.

Trong ngôn ngữ học, lemmatization có liên quan chặt chẽ với từ gốc, thực hành loại bỏ các tiền tố và hậu tố đã được thêm vào dạng cơ sở của một từ. Tuy nhiên, từ vựng phức tạp hơn so với từ gốc vì nó yêu cầu các từ được phân loại theo một phần của bài phát biểu cũng như theo hình thức biến cách. Điều này có thể trở nên khá phức tạp đối với các ngôn ngữ khác ngoài tiếng Anh, những ngôn ngữ chỉ có dạng biến cách là số ít/số nhiều, thì của động từ và dạng so sánh hơn/bậc nhất của trạng từ và tính từ.
Sự khác biệt chính giữa stemming và lemmatization
Mục đích của cả hai quá trình đều giống nhau: giảm các dạng biến tố của mỗi từ thành một cơ sở hoặc gốc chung. Tuy nhiên, hai phương pháp này không hoàn toàn giống nhau. Sự khác biệt chính là cách chúng hoạt động và do đó, kết quả mà chúng trả về.
Stemming hoạt động bằng cách cắt bỏ phần cuối hoặc phần đầu của từ, có tính đến danh sách các tiền tố và hậu tố phổ biến có thể tìm thấy trong một từ được biến cách. Việc cắt bừa bãi này có thể thành công trong một số trường hợp, nhưng không phải lúc nào cũng vậy, và đó là lý do tại sao chúng tôi khẳng định rằng phương pháp này có một số hạn chế. Dưới đây chúng tôi minh họa phương pháp này bằng các ví dụ bằng cả tiếng Anh và tiếng Tây Ban Nha.

Mặt khác, lemmatization có tính đến việc phân tích hình thái của các từ. Để làm như vậy, cần phải có các từ điển chi tiết mà thuật toán có thể xem qua để liên kết biểu mẫu trở lại bổ đề của nó.
Một điểm khác biệt quan trọng khác cần làm nổi bật là một bổ đề là dạng cơ sở của tất cả các dạng biến thể của nó, trong khi một gốc thì không. Đây là lý do tại sao các từ điển thông thường là danh sách các bổ đề, không phải gốc. Điều này có hai hậu quả:
Đầu tiên, Stemming có thể giống nhau đối với các dạng biến thể của các bổ đề khác nhau. Điều này chuyển thành tiếng ồn trong kết quả tìm kiếm của chúng tôi.
Trong tiếng Telugu, dạng của từ “áo choàng” giống hệt với dạng của từ “Tôi không chia sẻ”, vì vậy gốc của chúng cũng không thể phân biệt được. Nhưng tất nhiên, chúng thuộc về các bổ đề khác nhau. Điều tương tự cũng xảy ra ở Gujarati , nơi các các từ “đánh bại” và “thiết lập” trùng khớp nhau, nhưng chúng ta có thể tách cái này ra khỏi cái khác bằng cách xem xét các bổ đề của chúng.
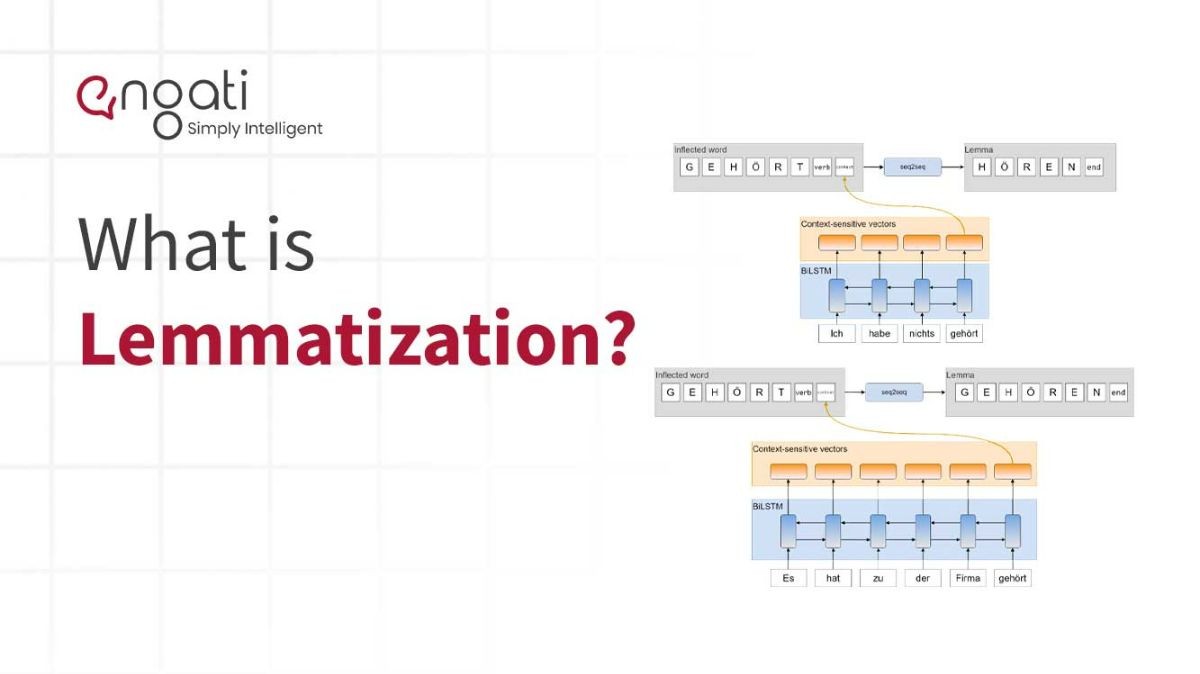
Lemmatization làm việc như thế nào?
Lemmatization là chìa khóa của phương pháp luận này là ngôn ngữ học. Để trích xuất bổ đề thích hợp, cần phải xem xét phân tích hình thái của từng từ. Điều này đòi hỏi phải có từ điển cho mọi ngôn ngữ để cung cấp loại phân tích đó.
Các cách tiếp cận khác nhau để bổ đề hóa:
Chúng ta sẽ xem xét 9 cách tiếp cận khác nhau để thực hiện Bổ đề hóa cùng với nhiều ví dụ và triển khai mã.
- Mạng từ
- Mạng từ (có thẻ POS)
- TextBlob
- TextBlob (có thẻ POS)
- spaCy
- TreeTagger
- Pattern
- Gensim
- Stanford CoreNLP
Wordnet Lemmatizer
Wordnet là một cơ sở dữ liệu từ vựng có sẵn công khai của hơn 200 ngôn ngữ cung cấp các mối quan hệ ngữ nghĩa giữa các từ của nó. Đây là một trong những kỹ thuật lemmatizer sớm nhất và được sử dụng phổ biến nhất.
Nó có trong thư viện nltk trong python.
Mạng từ liên kết các từ thành các quan hệ ngữ nghĩa. (ví dụ: từ đồng nghĩa)
Nó nhóm các từ đồng nghĩa dưới dạng các tập đồng nghĩa.
synsets : một nhóm các phần tử dữ liệu tương đương về mặt ngữ nghĩa.
Cách sử dụng:
- Tải xuống gói nltk: Trong dấu nhắc hoặc thiết bị đầu cuối anaconda của bạn, hãy nhập:
- cài đặt pip nltk
- Tải xuống Wordnet từ nltk: Trong bảng điều khiển python của bạn, hãy làm như sau:
- nhập nltk
- nltk.download('wordnet')
- nltk.download(‘averaged_perceptron_tagger’)
Wordnet Lemmatizer (với thẻ POS)
Trong cách tiếp cận trên, chúng tôi quan sát thấy rằng các kết quả Wordnet không đạt yêu cầu. Những từ như 'ngồi', 'bay', v.v. vẫn giữ nguyên sau khi từ vựng hóa. Điều này là do những từ này được coi là một danh từ trong câu đã cho hơn là một động từ. Để khắc phục điều này, chúng tôi sử dụng thẻ POS (Part of Speech).
Chúng tôi thêm một thẻ với một từ cụ thể xác định loại của nó (động từ, danh từ, tính từ, v.v.).

TextBlob
TextBlob là một thư viện python được sử dụng để xử lý dữ liệu văn bản. Nó cung cấp một API đơn giản để truy cập các phương thức của nó và thực hiện các tác vụ NLP cơ bản.
TextBlob (với thẻ POS)
Giống như cách tiếp cận Wordnet mà không sử dụng các thẻ POS thích hợp, chúng tôi cũng quan sát thấy những hạn chế tương tự trong cách tiếp cận này. Vì vậy, chúng tôi sử dụng một trong những khía cạnh mạnh mẽ hơn của mô-đun TextBlob là gắn thẻ 'Phần của Bài phát biểu' để khắc phục vấn đề này.
spaCy
spaCy là một thư viện python mã nguồn mở phân tích cú pháp và “hiểu” khối lượng lớn văn bản. Có sẵn các mẫu riêng biệt phục vụ cho các ngôn ngữ cụ thể (tiếng Anh, tiếng Pháp, tiếng Đức, v.v.).
Trong đoạn mã trên, có thể quan sát thấy rằng phương pháp này mạnh hơn các phương pháp trước đây như:
- Ngay cả Pro-nouns đã được phát hiện. (được xác định bởi -PRON-)
- Thậm chí văn bản tốt nhất đã được thay đổi thành tốt.
TreeTagger
TreeTagger là một công cụ để chú thích văn bản với thông tin về một phần của bài phát biểu và bổ đề. TreeTagger đã được sử dụng thành công để gắn thẻ cho hơn 25 ngôn ngữ và có thể thích ứng với các ngôn ngữ khác nếu có sẵn tập dữ liệu đào tạo được gắn thẻ thủ công.
Mẫu
Mẫu là gói Python thường được sử dụng để khai thác web, xử lý ngôn ngữ tự nhiên, học máy và phân tích mạng. Nó có nhiều khả năng NLP hữu ích. Nó cũng chứa một tính năng đặc biệt mà chúng ta sẽ thảo luận dưới đây.
Gensim
Gensim được thiết kế để xử lý các tập hợp văn bản lớn bằng truyền dữ liệu. Các cơ sở từ vựng của nó dựa trên gói mẫu mà chúng tôi đã cài đặt ở trên.
Hàm gensim.utils.lemmatize() có thể được sử dụng để thực hiện Bổ đề hóa. Phương pháp này có trong mô-đun utils trong python.
Chúng ta có thể sử dụng bộ bổ đề này từ mẫu để trích xuất các mã thông báo được mã hóa UTF8 ở dạng cơ sở = bổ đề của chúng.
Chỉ xem xét danh từ, động từ, tính từ và trạng từ theo mặc định (tất cả các bổ đề khác đều bị loại bỏ).
Lemmatization là phương pháp được sử dụng rất phổ biến bởi các công cụ tìm kiếm và chatbot hiện nay. Chúng giúp gợi ý hiệu quả các cụm từ thường được người dùng sử dụng.