Ứng dụng quan trọng của Supervised Learning trong kinh doanh
BÀI LIÊN QUAN
Self-Supervised Learning: Liệu máy móc có thể học như con người?Unsupervised Learning là gì? Ví dụ và so sánh với Supervised LearningBlended Learning là gì? Lợi ích của phương pháp học tập áp dụng công nghệ sốSupervised Learning là gì? Học có giám sát là gì?
Trong Supervised Learning (học có giám sát), một máy được huấn luyện bằng cách sử dụng dữ liệu 'được gán nhãn'. Tập dữ liệu được gọi là được gán nhãn khi chúng chứa cả tham số đầu vào và tham số đầu ra. Nói cách khác, dữ liệu đã được gắn với câu trả lời chính xác.
Có thể nó, kỹ thuật này chính là sự bắt chước môi trường lớp học của học sinh với sự hiện diện của người giám sát hoặc giáo viên. Mặt khác, các thuật toán học tập không giám sát (Unsupervised Learning) cho phép các mô hình khám phá thông tin và tự học.
Học máy có giám sát (Supervised machine learning) rất hữu ích trong giải quyết các vấn đề tính toán ở thế giới thực.
Làm thế nào Supervised Learning hoạt động?
Ví dụ: Bạn muốn huấn luyện một cỗ máy dự đoán thời gian di chuyển từ văn phòng đến nhà bạn. Đầu tiên, bạn sẽ tạo một tập dữ liệu được gán nhãn làm dữ liệu đầu vào như thời tiết, thời gian trong ngày, tuyến đường, v.v. Và đầu ra sẽ là khoảng thời gian ước tính của quãng đường trở về nhà của bạn vào một ngày cụ thể.
Sau khi bạn tạo một tập đào tạo dựa trên các yếu tố tương ứng, máy sẽ thấy mối quan hệ giữa các điểm dữ liệu và sử dụng nó để xác định khoảng thời gian bạn cần để lái xe trở về nhà. Ví dụ: một ứng dụng di động có thể cho bạn biết thời gian di chuyển của bạn sẽ lâu hơn khi có mưa lớn.
Máy cũng có thể thấy các kết nối khác trong dữ liệu được gắn nhãn của bạn, chẳng hạn như thời gian bạn rời khỏi nơi làm việc. Bạn có thể về nhà sớm hơn nếu xuất phát trước giờ cao điểm.
Một ví dụ thực tế khác: Giả sử bạn có một giỏ trái cây, và bạn luyện máy với tất cả các loại trái cây khác nhau. Dữ liệu bạn nhập bao gồm:
- Đối với loại quả có màu đỏ, hình tròn và có phần lõm ở phía trên, gắn nhãn 'Quả táo'
- Đối với loại quả có màu vàng và có dạng hình trụ cong, gán nhãn 'Quả chuối'
Tiếp theo, bạn đưa một quả khác ra và yêu cầu máy nhận biết đó là chuối hay táo. Máy sẽ học từ dữ liệu đào tạo và áp dụng kiến thức để phân loại trái cây theo màu sắc và hình dạng đã nhập.
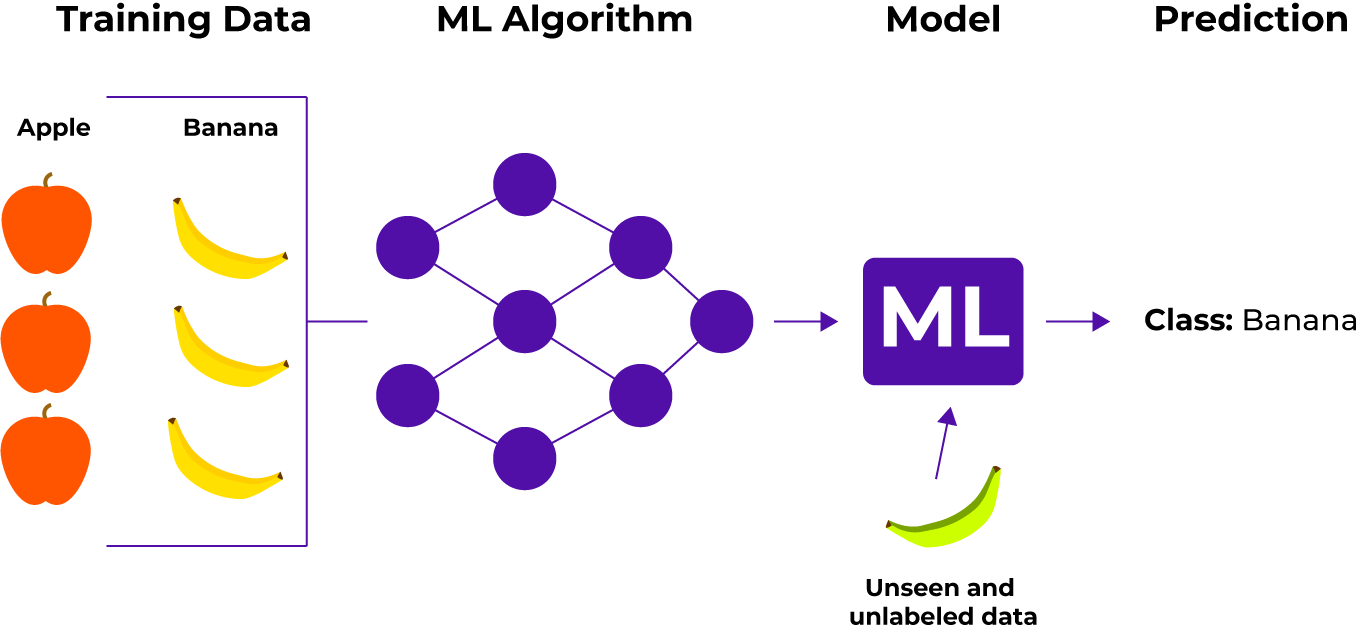
5 loại hình Supervised Learning bạn phải biết
Regression - Hồi quy
Trong hồi quy, máy sử dụng các dữ liệu đào tạo và tạo ra một giá trị thực liên tục. Giá trị này là xác suất được xác định sau khi máy xem xét sự liên quan giữa các biến đầu vào. Ví dụ, hồi quy có thể giúp dự đoán giá của một căn nhà dựa trên các yếu tố địa phương, diện tích, v.v.
Hiểu đơn giản hơn qua câu hỏi sau: Thao tác nào dưới đây là vấn đề hồi quy?
- Dự đoán tuổi của một người
- Dự đoán quốc tịch của một người
- Dự đoán liệu giá cổ phiếu của một công ty có tăng vào ngày mai hay không
Đáp án là “Dự đoán tuổi của một người”, vì đó là giá trị thực, trong khi, “dự đoán quốc tịch” mang tính phân loại, còn “liệu giá cổ phiếu có tăng hay không” có câu trả lời có/không).
Classification - Phân loại
Classification là khi biến đầu ra là một danh mục, chẳng hạn như “đỏ” hoặc “xanh” hay “bệnh” hoặc “không bệnh”. Một mô hình phân loại sẽ rút ra một số kết luận từ các giá trị nó quan sát được.
Hiểu đơn giản hơn qua câu hỏi sau: Điều nào sau đây là vấn đề phân loại?
- Dự đoán giới tính của một người bằng cách viết tay của họ
- Dự đoán giá nhà dựa trên diện tích
- Dự đoán liệu năm tới gió mùa có bình thường không
- Dự đoán số lượng bản một album nhạc sẽ được bán vào tháng tới
Đáp án: “Dự đoán giới tính của một người/ Dự đoán liệu năm tới gió mùa có bình thường không” là vấn đề phân loại. Hai cái còn lại là hồi quy.
Một số thuật toán phân loại, có thể kể đến: K-nearest neighbor, Random forest, Support vector machines, Decision tree, Linear classifiers…
Naive Bayes
Thuật toán Naive Bayes được sử dụng cho các tập dữ liệu lớn. Cơ sở hoạt động của thuật toán này là mọi chương trình trong nó đều hoạt động độc lập, có nghĩa là sự hiện diện của tính năng này sẽ không ảnh hưởng đến tính năng khác. Nói chung, Naive Bayes được sử dụng trong việc phân loại văn bản, dự đoán với thời gian thực, hệ thống Recommendation...
Định lý Bayes
Định lý Bayes cho phép máy tính xác suất xảy ra của một sự kiện A khi biết sự kiện liên quan B đã xảy ra. Công thức tính là:
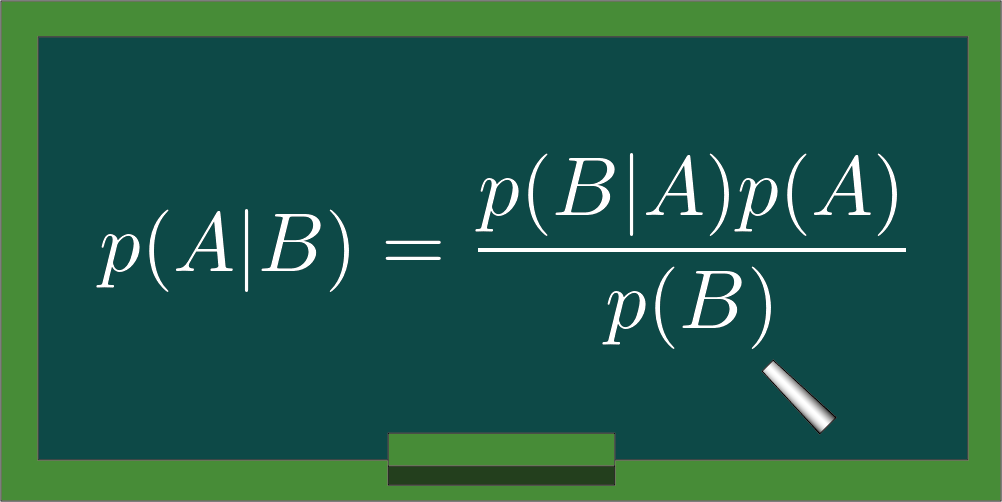
- P(A|B): xác suất của A khi biết B
- P(A): xác suất xảy ra A
- P(B|A): xác suất của B khi biết A
- P(B): xác suất xảy ra B
Ví dụ: Một đám cháy nguy hiểm có xác suất xảy ra là 1%; khói có xác suất xuất hiện cao hơn là 10% (gồm cả khói từ các nhà máy); và 90% các đám cháy nguy hiểm đều tạo ra khói. Vậy để tính xác suất xảy ra đám cháy nguy hiểm khi thấy khói, ta có:
P(Lửa|Khói) = P(Lửa) x P(Khói|Lửa) / P(Khói) = 1% x 90% / 10% = 9%
Đáp án: Xác suất 9% khi thấy khói là có một đám cháy nguy hiểm.
Neural Networks - Mạng thần kinh
Thuật toán này được thiết kế để phân cụm đầu vào thô, nhận dạng các mẫu hoặc diễn giải dữ liệu cảm quan. Mặc dù có nhiều ưu điểm, mạng thần kinh đòi hỏi khá nhiều tài nguyên tính toán. Neural Networks còn được gọi là thuật toán 'hộp đen' vì việc giải thích logic đằng sau các dự đoán của chúng vẫn còn là một thách thức.
Random Forest - Rừng ngẫu nhiên
Thuật toán rừng ngẫu nhiên thường được gọi là phương pháp tổng hợp vì nó kết hợp các phương pháp học có giám sát khác nhau để đưa ra kết luận. Random Forest sử dụng nhiều cây quyết định (Decision Tree*) để đưa ra phân loại. Đây là thuật toán được sử dụng rộng rãi trong ngành công nghiệp.
*Decision Tree là một mô hình chứa các câu lệnh điều khiển có điều kiện, bao gồm các quyết định và các hệ quả có thể xảy ra của chúng. Trong đó, mỗi nút (node) của cây sẽ là các thuộc tính, các nhánh sẽ là giá trị lựa chọn của thuộc tính đó. Bằng cách đi theo các nhánh, cây quyết định sẽ cho biết giá trị dự đoán.
Một ví dụ đơn giản trong thực tế: Giả sử bạn muốn tìm một điểm vui chơi trong chuyến du lịch sắp tới của mình, và bạn quyết định sẽ hỏi một người bạn để tham khảo. Nhưng, nghe ý kiến của một người có thể không khách quan lắm. Bạn liền đi hỏi thêm vài người nữa, sau đó tổng hợp lại và cho ra quyết định.
Nếu coi mỗi ý kiến trên là một cây quyết định thì ta đã đến gần hơn với khái niệm về Random Forest. Hoạt động của Random Forest chính là đánh giá nhiều Cây quyết định ngẫu nhiên, và cho ra kết quả cuối cùng là đánh giá tốt nhất trong số đó.

Ưu điểm của Supervised Learning
Khi được áp dụng trong lĩnh vực chuyên môn, học có giám sát mang lại nhiều lợi ích, tạo nên văn hóa làm việc coi trọng việc liên tục học hỏi. Một số ưu điểm của học có giám sát trong một tổ chức như:
- Thu thập dữ liệu cũ, giúp học hỏi từ những sai lầm trong quá khứ.
- Là một công cụ mạnh mẽ của AI có thể một mình thực hiện nhiều chức năng kinh doanh.
- Supervised Learning là thuật toán đáng tin cậy hơn Unsupervised Learning.
Những ứng dụng quan trọng của học có giám sát trong doanh nghiệp
Mô hình Supervised Learning có thể được sử dụng để xây dựng và cải tiến một số vấn đề kinh doanh, bao gồm:
- Nhận dạng hình ảnh và đối tượng: Các thuật toán học có giám sát có thể được sử dụng để xác định vị trí, khoanh vùng và phân loại các đối tượng ra khỏi video hoặc hình ảnh, điều này rất hữu ích khi áp dụng vào các kỹ thuật thị giác máy tính và phân tích hình ảnh khác nhau.
- Phân tích dự đoán: Một trường hợp sử dụng rộng rãi cho các mô hình học tập có giám sát là tạo hệ thống phân tích dự đoán để cung cấp thông tin chi tiết về các điểm dữ liệu kinh doanh khác nhau. Điều này cho phép doanh nghiệp dự đoán các kết quả dựa trên một biến đầu ra nhất định, giúp các lãnh đạo chứng minh tính chính xác của các quyết định hoặc các vấn đề xoay quanh lợi ích của doanh nghiệp.
- Phân tích tâm lý khách hàng: Sử dụng các thuật toán học máy có giám sát, các tổ chức có thể trích xuất và phân loại các thông tin quan trọng từ lượng lớn dữ liệu (bao gồm ngữ cảnh, cảm xúc và ý định). Điều này vô cùng hữu ích khi doanh nghiệp có thể hiểu rõ hơn các tương tác của khách hàng.
- Phát hiện thư rác: Phát hiện thư rác là một ví dụ khác về mô hình học có giám sát. Sử dụng các thuật toán phân loại có giám sát, các tổ chức có thể đào tạo cơ sở dữ liệu để nhận ra các mẫu hoặc điểm bất thường trong dữ liệu mới để tổ chức các thư từ liên quan đến thư rác và không phải thư rác một cách hiệu quả.
Hạn chế của Supervised Learning
Tuy nhiên, học có giám sát không phải không có những hạn chế. Dưới đây là một số nhược điểm của phương pháp học có giám sát:
- Mô hình Supervised Learning có thể yêu cầu mức độ chuyên môn nhất định để vận hành chính xác.
- Đào tạo các mô hình học có giám sát có thể rất tốn thời gian.
- Supervised Learning không thể tự phân cụm hoặc phân loại dữ liệu.
- Khi thực hiện bằng máy, tập dữ liệu có khả năng xảy ra lỗi cao hơn khi thực hiện bởi con người, dẫn đến thuật toán học không chính xác.
- Chuẩn bị dữ liệu và xử lý chúng trước khi đưa vào Supervised Learning luôn là thách thức
- Tính khả thi của Supervised Learning phụ thuộc vào tính năng người dùng hướng tới và các yếu tố khác như chi phí tính toán, số lượng dữ liệu…
Tóm lại
Supervised Learning sử dụng dữ liệu được gán nhãn để đào tạo một máy. Các kỹ thuật hồi quy và thuật toán phân loại giúp phát triển các mô hình dự báo với độ tin cậy cao và có nhiều ứng dụng hơn.
Ngày nay, khi trí tuệ nhân tạo và máy học đang tăng tốc trong thế giới định hướng công nghệ, hiểu biết về các loại hình Supervised Learning có thể là lợi thế đáng kể trong mọi lĩnh vực. Hy vọng những giải thích phía trên sẽ giúp bạn có được lợi thế đó!