Natural Language Processing (NLP) là gì? Tìm hiểu về Xử lý ngôn ngữ tự nhiên
BÀI LIÊN QUAN
Rust là gì? Những thông tin cần biết về ngôn ngữ lập trình Rust đầy đủ nhấtPHP là gì? Ứng dụng của ngôn ngữ PHP trong lập trình là gì?Top 11 Ngôn ngữ lập trình big data phổ biến nhất hiện nayNatural Language Processing (NLP) là gì? Xử lý ngôn ngữ tự nhiên là gì?
Xử lý ngôn ngữ tự nhiên, tiếng Anh là Natural Language Processing (NLP) là một nhánh của khoa học máy tính - cụ thể hơn là nhánh của trí tuệ nhân tạo AI - liên quan đến việc cung cấp cho máy tính khả năng đọc hiểu văn bản và giọng nói như con người.
NLP kết hợp các thuật ngữ máy tính - mô hình dựa trên quy tắc của ngôn ngữ con người - với các mô hình thống kê, học máy (machine learning) và học sâu (Deep learning). Những công nghệ này cho phép máy tính xử lý ngôn ngữ của con người dưới dạng dữ liệu văn bản hoặc giọng nói và 'hiểu' đầy đủ ý nghĩa của dữ liệu, cùng ý định và cảm xúc của người nói hoặc người viết.
Natural Language Processing điều khiển các chương trình dịch văn bản từ ngôn ngữ này sang ngôn ngữ khác, phản hồi các lệnh và tóm tắt lượng lớn văn bản một cách nhanh chóng. Rất có thể, trong cuộc sống hàng ngày, bạn đã tương tác với NLP thông qua điều hành hệ thống GPS bằng giọng nói, trợ lý kỹ thuật số, phần mềm đọc giọng nói thành văn bản, chatbots dịch vụ khách hàng và nhiều tiện ích khác. NLP cũng đóng vai trò ngày càng quan trọng trong các giải pháp giúp doanh nghiệp hợp lý hóa hoạt động kinh doanh, tăng năng suất của nhân viên và đơn giản hóa các quy trình kinh doanh.
Làm cách nào máy tính hiểu được văn bản ?
Máy tính có thể dễ dàng hiểu được con số, nhưng không thể nào hiểu được các ký tự, từ ngữ hay câu nói. Chúng cần một số bước trung gian trước khi có thể xây dựng mô hình Xử lý ngôn ngữ tự nhiên NLP, gọi là bước biểu diễn văn bản. Phân tích dưới đây tập trung giải thích biểu diễn từ (word).
Trước khi học sâu (Deep learning) ra đời, biểu diễn văn bản được triển khai bằng kỹ thuật khá đơn giản là One-hot encoder. Như hình phía dưới đây:
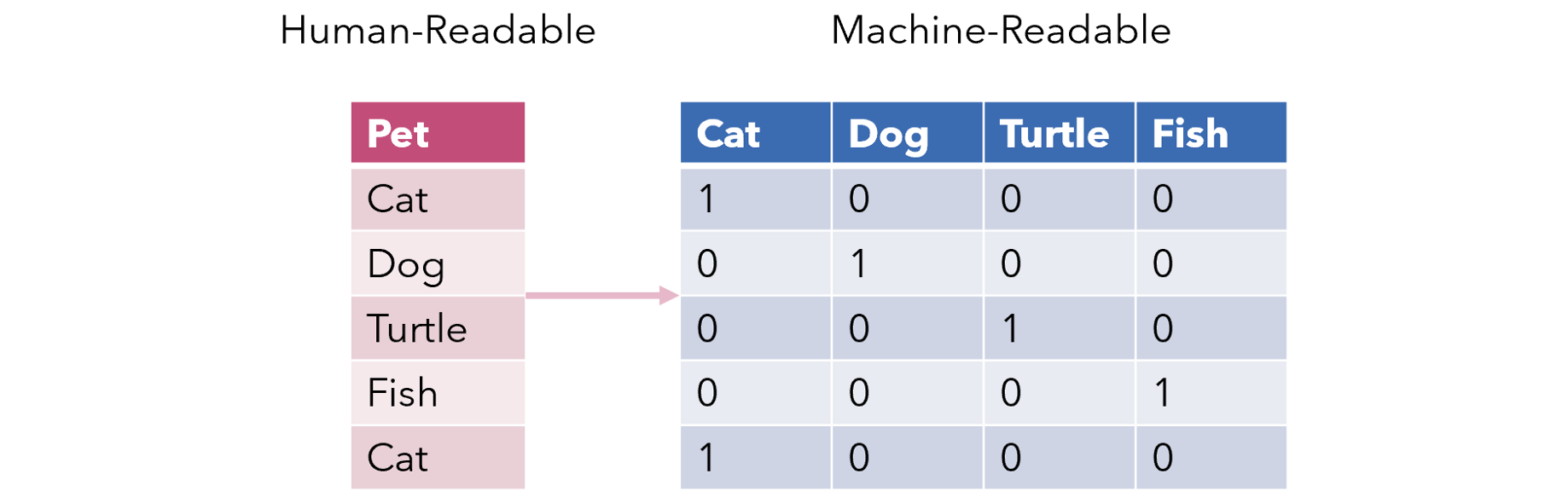
Trong bức ảnh, bạn sẽ thấy, giả sử có 5 câu, được chuyển thành một mảng N*M:
- N biểu thị số lượng câu cần biểu diễn
- M biểu thị số lượng từ khác nhau tồn tại trong văn bản
Tương ứng với mỗi câu, từ nào xuất hiện thì đánh số 1, còn không xuất hiện sẽ đánh số 0. Kết quả là bạn đã có một vectơ (1,0,0,0) biểu diễn cho từ ‘Cat’. Cách tiếp cận này có một số những hạn chế như:
- Thứ nhất là vấn đề về bộ nhớ lưu trữ (RAM + Ổ cứng). như các bạn cũng thấy trong ví dụ, vectơ bao gồm rất nhiều số 0 và rất ít số 1, dù số 0 hầu như không dùng đến nhưng bạn vẫn phải lưu trữ nó.
- Thứ hai là thiếu độ hiểu biết về ngữ nghĩa của câu, vì vector không biểu thị được quan hệ của các từ với nhau. Ví dụ ‘ong’ và ‘hoa’ có thể có mối liên hệ mật thiết với nhau.
Cuối năm 2018, các nhà nghiên cứu của Google đã đưa ra mô hình BERT*, được cho là cơ sở cho các nghiên cứu và ứng dụng của NLP tiên tiến nhất hiện nay.
*BERT, là một kỹ thuật học máy dựa trên các transformer dùng cho việc huấn luyện trước NLP được phát triển bởi Google. Jacob Devlin.
Phân loại NLP
Natural Language Processing (NLP) được chia thành 2 lĩnh vực chính là Ngôn ngữ học và Khoa học máy tính. Trong đó,
Ngôn ngữ học tập trung vào việc hiểu được cấu trúc của ngôn ngữ, gồm:
- Ngữ âm: Nghiên cứu âm thanh ngôn ngữ của con người
- Âm vị: Nghiên cứu hệ thống âm thanh trong ngôn ngữ của con người
- Cú pháp: Nghiên cứu sự hình thành và cấu trúc của câu nói.
- Ngữ nghĩa: Nghiên cứu ý nghĩa của câu nói
- Ngữ dụng học: Nghiên cứu cách thức các câu nói với ý nghĩa của chúng được sử dụng trong các mục đích giao tiếp cụ thể.

Khoa học máy tính thì quan tâm đến chuyển đổi các kiến thức chuyên sâu của ngôn ngữ học thành những chương trình máy tính với sự trợ giúp đắc lực từ trí tuệ nhân tạo (AI). Những tiến bộ kỹ thuật trong lĩnh vực Xử lý ngôn gnuwx tự nhiên có thể được thành: Mô hình hệ thống dựa trên quy tắc, mô hình máy học cổ điển và học sâu.
- Mô hình hệ thống dựa trên các quy tắc (rule-based), nôm na là bạn định ra một số quy tắc dựa trên những hiểu biết nhất định về ngôn ngữ học. Ví dụ bạn định ra quy tắc nếu các chữ có chữ cái đầu viết hoa thì sẽ là tên người hoặc địa danh (Lisa, Hà Nội…). Tuy nhiên, sự phức tạp của ngôn ngữ con người không dừng lại ở đó, mà còn phát triển thêm ( như teen code, cố tình viết/nói sai chính tả...). Hệ thống rule-based khá cứng nhắc, do đó, phải luôn có người liên tục cập nhập các quy tắc, đồng thời khó để quản lý và tính khái quát hóa thấp.
- Mô hình máy học cổ điển: có thể giải bài toán thách thức hơn (như phát hiện spam) thông qua trích lọc các các thuộc tính (như tên, họ, năm sinh...). Các mô hình này sẽ khai thác những mẫu câu có ngữ nghĩa trong dữ liệu huấn luyện để đưa ra các dự đoán trong tương lai.
- Mô hình học sâu: là mô hình phổ biến nhất hiện nay trong nghiên cứu và ứng dụng NLP. Nó có khả năng tương thích dữ liệu mới tốt hơn mô hình máy học cổ điển. Mô hình này không cần các thuộc tính xử lý thủ công, vì nó có thể tự làm. Khả năng học hỏi của mô hình Deep learning cũng mạnh mẽ hơn nhiều so với các mô hình cổ điển. Nó mở ra con đường giải quyết triệt để các bài toán NLP phức tạp.
Nhiệm vụ của NLP
Ngôn ngữ của con người chứa đựng đầy sự mơ hồ, đôi lúc chia ra nghĩa đen và nghĩa bóng, khiến việc xác định chính xác ý nghĩa của dữ liệu văn bản hoặc giọng nói là vô cùng khó khăn đối với máy móc. Từ đồng âm, từ đồng nghĩa, nói quá, nói giảm nói tránh, thành ngữ, tục ngữ, ẩn dụ, hoán dụ và các biến thể trong cấu trúc câu như đảo trật tự từ, câu rút gọn… Đây chỉ là một trong vô số điểm mơ hồ của ngôn ngữ con người mà chúng ta phải mất nhiều năm để học, nhưng các lập trình viên phải dạy các ứng dụng sử dụng ngôn ngữ tự nhiên để nhận ra và hiểu chính xác ngữ nghĩa đó ngay từ đầu, để chúng trở thành những ứng dụng hữu ích.
Nhiệm vụ của Natural Language Processing (NLP) là chia nhỏ dữ liệu văn bản và giọng nói của con người giúp máy tính hiểu được những gì nó đang sử dụng. Một số nhiệm vụ này bao gồm những việc sau:
- Nhận dạng giọng nói, còn được gọi là chuyển giọng nói thành văn bản, là nhiệm vụ chuyển đổi dữ liệu giọng nói thành dữ liệu văn bản một cách chính xác. Nhận dạng giọng nói là bắt buộc đối với bất kỳ ứng dụng có chức năng làm theo lệnh thoại hoặc trả lời các câu hỏi bằng giọng nói.
- Gắn thẻ giọng nói, hay gắn thẻ ngữ pháp, là quá trình xác định một từ hoặc đoạn văn bản dựa trên cách sử dụng và ngữ cảnh của nó.
- Phân loại nghĩa của từ là việc lựa chọn nghĩa của một từ nhiều nghĩa thông qua quá trình phân tích ngữ nghĩa nghĩa của từ trong ngữ cảnh nhất định.
- Nhận dạng thực thể được đặt tên, hoặc Named Entity Recognition (NER), xác định các từ hoặc cụm từ là các thực thể hữu ích. Ví dụ: NER xác định 'Hà Nội' là một vị trí hoặc 'Lisa' là tên của một người phụ nữ.
- Phân giải đồng tham chiếu là nhiệm vụ xác định nếu và khi nào hai từ đề cập đến cùng một thực thể. Ví dụ 'she' = 'Mary'. Nó cũng có thể xác định so sánh ẩn dụ hoặc một thành ngữ trong văn bản (ví dụ: trong một số trường hợp, từ ‘bear’ không được dùng để chỉ một con vật (con gấu), mà là ẩn ý về một người nhiều lông).
- Phân tích cảm xúc cố gắng rút ra những cảm xúc chủ quan như thái độ, mỉa mai, bối rối, nghi ngờ… từ văn bản.
- Sinh ngôn tự nhiên, Natural Language Generation (NLG) đôi khi là ngược lại của nhận dạng giọng nói hay chuyển lời nói thành văn bản. NLG có nhiệm vụ đưa thông tin có cấu trúc sang ngôn ngữ của con người.

Các trường hợp sử dụng NLP
Natural Language Processing (NLP) là động lực thúc đẩy trí thông minh của máy móc trong nhiều ứng dụng hiện đại ngoài thế giới thực. Dưới đây là vài ví dụ:
Phát hiện thư rác
Có thể nhiều người không tin rằng phát hiện thư rác lại là một giải pháp của Xử lý ngôn ngữ tự nhiên. Tuy nghe có vẻ không liên quan nhưng các công gnheej phát hiện thư rác tốt nhất hiện nay đều sử dụng khả năng phân loại văn bản của NLP để quét email, qua đó chỉ ra những thư rác hay lừa đảo. Cách lọc bao gồm việc email chứa qua nhiều điều khoản tài chính, ngữ pháp đặc trưng, ngôn ngữ đe dọa, tên công ty sai chính tả, v.v.
Phát hiện thư rác là một trong số ít các vấn đề NLP có thể ứng dụng mà các chuyên gia coi là giải quyết được gần như 100%.
Dịch máy (Machine Translation)
Google Dịch là ví dụ về công nghệ NLP phổ biến. Thay vì chỉ có thể thay thế các từ trong cùng ngôn ngữ, công nghệ có thể thay các từ của ngôn ngữ này bằng các từ của ngôn ngữ khác.
Để dịch hiệu quả, máy phải nắm bắt chính xác ý nghĩa và giọng điệu của ngôn ngữ đầu vào và dịch chúng sang văn bản với cùng ý nghĩa và mục đích sử dụng trong ngôn ngữ đầu ra.
Các công cụ dịch máy đang ngày càng tiến bộ về độ chính xác. Một cách kiểm tra khả năng của bất kỳ công cụ dịch nào là dịch văn bản sang một ngôn ngữ khác, sau đó lấy văn bản đã dịch dịch lại về ngôn ngữ gốc, rồi đối chiếu. Ví dụ điển hình từng được thử trước đây: Cách đây không lâu, dịch câu tiếng Anh "The spirit is willing but the flesh is weak" sang tiếng Nga và sau đó đảo ngược lại, thì văn bản trở thành là "The vodka is good but the meat is rotten”. Ngày nay, kết quả là "The spirit desires, but the flesh is weak", dù kết quả không hoàn hảo, nhưng đã cải tiến rất nhiều và nghĩa câu từ tương đối sát.
Phân tích cảm xúc trên mạng xã hội
NLP đã trở thành một công cụ kinh doanh cần thiết trong việc khám phá dữ liệu ẩn từ các kênh truyền thông xã hội. Phân tích cảm xúc (Sentiment analysis) có thể phân tích ngôn ngữ được sử dụng trong các bài đăng, phản hồi, đánh giá trên mạng xã hội, v.v. để rút ra thái độ và cảm xúc của khách hàng với sản phẩm, chương trình khuyến mại hay sự kiện. Những dữ liệu này giúp các công ty rất nhiều trong thiết kế sản phẩm, chiến dịch quảng cáo, v.v.
Công nghệ Xử lý ngôn ngữ tự nhiên, Natural Language Processing (NLP) ngày càng có nhiều ứng dụng tốt và dần trở nên phổ biến trong cuộc sống hàng ngày. Với sự tiến bộ không ngừng về kỹ thuật, tốc độ xử lý và độ chính xác, NLP đã từng bước giúp máy tính hiểu và giao tiếp với con người bằng chính ngôn ngữ của chúng ta.