Decision Tree là gì? Các thuật toán liên quan tới Decision Tree
BÀI LIÊN QUAN
Các phương pháp khai phá dữ liệu hiệu quảTìm hiểu về ứng dụng của khai phá dữ liệu trong các lĩnh vựcRegression Analysis là gì? Ý nghĩa, phân loại và ví dụ cụ thểDecision Tree là gì?
Theo bạn Decision Tree là gì? Về cơ bản, Decision Tree (cây quyết định) là một cây phân cấp có cấu trúc được dùng để phân lớp các đối tượng dựa vào dãy các luật. Các thuộc tính của đối tượng có thể thuộc các kiểu dữ liệu khác nhau như Nhị phân (Binary), Định danh (Nominal), Thứ tự (Ordinal), Số lượng (Quantitative). Mặt khác, thuộc tính phân lớp phải có kiểu dữ liệu là Binary hoặc Ordinal
Decision Tree là một trong những mô hình có khả năng diễn giải cao và có thể thực hiện cả nhiệm vụ classification và regression. Để thực hiện các mô hình tuyến tính cổ điển, người dùng phải đảm bảo dữ liệu được sử dụng để đào tạo mô hình không có các bất thường như giá trị ngoại lệ cần được xử lý, giá trị bị thiếu, đa cộng tuyến cần được giải quyết.
Trong khi với Decision Tree chúng ta không cần phải thực hiện bất kỳ loại xử lý trước dữ liệu nào trước đó. Decision Tree đủ mạnh để xử lý tất cả các loại vấn đề như vậy để đi đến quyết định. Bên cạnh đó, Decision Tree có khả năng xử lý dữ liệu phi tuyến mà các mô hình tuyến tính cổ điển không xử lý được.

Một số thuật ngữ
Cùng tìm hiểu một vài thuật ngữ liên quan để hiểu rõ hơn về Decision Tree là gì. Mô hình này được áp dụng vào cả 2 bài toán Phân loại (Classification) và Hồi quy (Regression). Trong đó, bài toán Classification được sử dụng nhiều hơn.
- Regression tree: ước lượng các hàm giá có giá trị là số thực thay vì được sử dụng cho các nhiệm vụ phân loại
- Classification tree: nếu y là một biến phân loại như: giới tính (nam hay nữ), kết quả của một trận đấu (thắng hay thua).
- Root Nodes: nút hiện ở đầu Decision Tree. Từ nút này, quần thể bắt đầu phân chia theo các đặc điểm khác nhau.
- Decision Nodes: nút nhận được sau khi tách các Root Nodes
- Leaf Nodes (nút đầu cuối): các nút không thể tách thêm
- Sub-tree: một phần con của Decision Tree
- Pruning: cắt giảm một số nút để ngừng trang bị quá mức
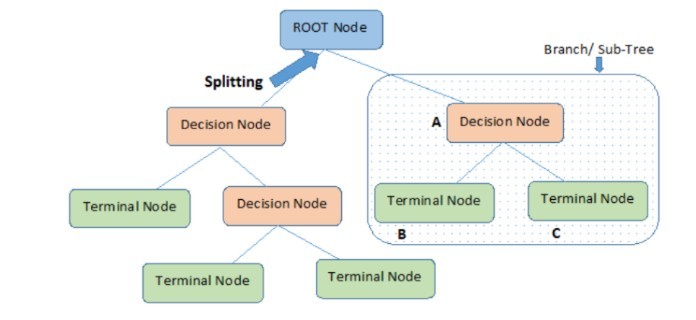
Cấu trúc của Decision Trees
Decision Trees gồm 3 phần chính: node gốc (root node), node lá (leaf nodes) và các nhánh nhỏ (branches). Trong đó node gốc là điểm bắt đầu của Decision Trees và cả hai node gốc và node chứa câu hỏi hoặc tiêu chí để được trả lời. Các nhánh nhỏ thể hiện kết quả của kiểm tra trên nút.
Ưu điểm và nhược điểm của Decision Tree là gì?
So với các phương pháp khai phá dữ liệu khác, Decision Tree có một số đặc điểm nổi bật như sau:
Ưu điểm
- Mô hình Decision Tree đơn giản, trực quan, không quá phức tạp để hiểu sau khi được giải thích ngắn
- Một số thuật toán Decision Tree có khả năng xử lý dữ liệu bị missing và dữ liệu bị lỗi mà không cần áp dụng phương pháp như “imputing missing values” hay loại bỏ. Bên cạnh đó, Decision Tree ít bị ảnh hưởng bởi các dữ liệu ngoại lệ (outliers)
- Đây là phương pháp không sử dụng tham số (nonparametric) nên không cần có các giả định ban đầu về các quy luật phân phối như trong thống kê. Nhờ đó các kết quả phân tích luôn khách quan nhất.
- Decision Tree có thể giúp chúng ta phân loại đối tượng dữ liệu theo biến mục tiêu có nhiều lớp, nhiều nhóm khác nhau, nhất là dạng biến định lượng phức tạp.
- Áp dụng linh hoạt cho các biến target, biến mục tiêu là biến định tính (classification task) và cả định lượng (regression task)
- Mang lại kết quả dự báo có độ chính xác cao, dễ dàng thực hiện, nhanh chóng trong việc huấn luyện, không cần phải chuyển đổi các biến
- Decision Tree rất dễ diễn giải hay giải thích đến người muốn hiểu rõ về kết quả phân tích nhưng không có kiến thức gì về khoa học dữ liệu.
- Mặc dù không thể hiện được rõ mối quan hệ tuyến tính, hay mức độ liên hệ nhưng Decision Tree vẫn nói lên được mối liên hệ giữa các biến, các thuộc tính dữ liệu một cách trực quan nhất
- Ngoài kinh tế, tài chính, Decision Tree có thể được ứng dụng trong lĩnh vực y tế, nông nghiệp, sinh học.

Nhược điểm
- Decision Tree hoạt động hiệu quả trên bộ dữ liệu đơn giản có ít biến dữ liệu liên hệ với nhau. Khi áp dụng với bộ dữ liệu phức tạp, nhiều biến và thuộc tính khác nhau có thể dẫn đến mô hình bị overfitting, quá khớp với dữ liệu training dẫn đến vấn đề không đưa ra kết quả phân loại chính xác
- Khi có sự thay đổi nhỏ trong bộ dữ liệu sẽ gây ảnh hưởng đến cấu trúc của mô hình.
- Decision Tree chỉ áp dụng cho biến định tính (classification tree) nếu phân loại sai có thể dẫn đến sai lầm nghiêm trọng. Còn đối với biến định lượng (regression tree) thì chỉ phân loại đối tượng, hay dự báo theo phạm vi giá trị (range) được tạo ra trước đó
- Mô hình này có khả năng “thiên vị” nếu bộ dữ liệu không được cân bằng, chỉ xét đến các giá trị tiêu biểu, và nguy cơ “Underfitting”
- Decision Tree yêu cầu bộ dữ liệu training và test phải được chuẩn bị hoàn hảo, chất lượng tốt phải được cân đối theo các lớp, các nhóm trong biến mục tiêu
- Decision Tree được hình thành trên các cách thức phân nhánh tại mỗi một thời điểm, một node hay biến dữ liệu bất kỳ và chỉ quan tâm duy nhất vào việc phân nhánh sao cho tối ưu tại thời điểm đó, mà không xét đến toàn bộ mô hình phải được thiết lập hiệu quả ra sao
- Decision Tree chỉ phân nhánh liên tục dựa trên các công thức phân nhánh cho đến khi thấy được kết quả cuối cùng nên chúng ta khó phát hiện được các lỗi sai sót

Các thuật toán Decision Tree
Dưới đây, chúng ta cùng tìm hiểu các thuật toán nổi tiếng và cơ bản nhất của Decision Tree.
Thuật toán ID3
Iterative Dichotomiser 3 (ID3) là thuật toán nổi tiếng để xây dựng Decision Tree, áp dụng cho bài toán Classification mà tất các các thuộc tính để ở dạng category. ID3 sử dụng phương pháp tìm kiếm từ trên xuống thông qua không gian của các nhánh có thể không có backtracking. Thuật toán ID3 sử dụng Entropy và Information Gain để xây dựng Decision Tree.
Thuật toán C4.5
Thuật toán C4.5 là thuật toán cải tiến của ID3. Trong thuật toán ID3, Information Gain được sử dụng làm độ đo nhưng ở phương pháp này lại ưu tiên những thuộc tính có số lượng lớn các giá trị, ít xét tới những giá trị nhỏ hơn. Do vậy, để khắc phục nhược điểm trên, ta sử dụng độ đo Gain Ratio (trong thuật toán C4.5) như sau:
Đầu tiên, người dùng cần chuẩn hoá information gain với trị thông tin phân tách (split information). Giả sử chúng ta phân chia biến thành n node gốc và Di đại diện cho số lượng bản ghi thuộc nút đó. Do đó, hệ số Gain Ratio sẽ xem xét được xu hướng phân phối khi chia cây. Áp dụng cho ví dụ trên và với cách chia thứ nhất, ta có:
Split Info = – ((4/7)*log2(4/7)) – ((3/7)*log2(3/7)) = 0.98
Gain Ratio = 0.09/0.98 = 0.092
Ngoài ID3, C4.5, chúng ta còn một số thuật toán khác như:
- Thuật toán CHAID: Tạo Decision Tree bằng cách sử dụng thống kê chi-square để xác định các phân tách tối ưu. Các biến mục tiêu đầu vào có thể là số (liên tục) hoặc phân loại.
- Thuật toán C&R: Sử dụng phân vùng đệ quy để chia cây, tham biến mục tiêu có thể dạng số hoặc phân loại.
- MARS
- Conditional Inference Tree
Lời kết
Trên đây là thông tin chi tiết để giải thích định nghĩa Decision Tree là gì?. Hy vọng với những kiến thức bổ ích trong bài viết trên, bạn đọc đã biết cách sử dụng mô hình này chính xác và hiệu quả nhất.