Data preprocessing là gì? Bước không thể thiếu trong khai thác dữ liệu
BÀI LIÊN QUAN
Data masking là gì? Những kỹ thuật và cách thực hiện data masking thành côngDatabase activity monitoring (DAM) là gì? Kiến trúc và tính năng của giải pháp DAMData Architect là gì? Những yêu cầu cụ thể của công việc nàyData preprocessing là gì?
Tiền xử lý dữ liệu, tiếng Anh là Data preprocessing, là một bước quan trọng trong quy trình khai thác và phân tích dữ liệu. Nhiệm vụ của quá trình này là lấy dữ liệu thô, biến đổi chúng thành định dạng mà máy tính và học máy có thể hiểu và phân tích được.
Dữ liệu thô là các dữ liệu lộn xộn ở dạng văn bản, hình ảnh, video, v.v... Chúng tiềm ẩn nhiều lỗi, không đầy đủ và không có thiết kế thống nhất, thông thường.
Trong khi đó, máy thích xử lý thông tin đẹp và gọn gàng - chúng đọc dữ liệu dưới dạng 1 và 0. Vì vậy, việc tính toán dữ liệu có cấu trúc, chẳng hạn như số nguyên và tỷ lệ phần trăm sẽ diễn ra rất dễ dàng. Còn dữ liệu phi cấu trúc (ở dạng văn bản và hình ảnh) trước tiên phải được làm sạch và định dạng rồi mới có thể thực hiện phân tích.
Tầm quan trọng của tiền xử lý dữ liệu
Khi sử dụng tập dữ liệu cho huấn luyện các mô hình học máy, bạn sẽ thường thấy cụm từ “garbage in, garbage out”. Điều này có nghĩa là nếu bạn sử dụng dữ liệu đầu vào thiếu hoặc vô nghĩa thì sẽ tạo ra đầu ra vô nghĩa, một mô hình được đào tạo không đúng cách sẽ không thể phù hợp với phân tích của bạn.
Dữ liệu tốt (đã được xử lý) thậm chí còn quan trọng hơn các thuật toán mạnh mẽ nhất. Điều này thể hiện rõ ràng đến mức các mô hình học máy được đào tạo bởi dữ liệu xấu thực sự gây hại cho quá trình phân tích, mang lại cho bạn kết quả “rác rưởi”.

Tùy thuộc vào kỹ thuật và nguồn dữ liệu, bạn có thể nhận được dữ liệu ngoài phạm vi hoặc gồm tính năng không chính xác, chẳng hạn dữ liệu thu thập hình ảnh từ một nhóm “động vật trong vườn thú” lại bao gồm hình ảnh cây cối. Tập dữ liệu thu thập được cũng có thể thiếu các giá trị hay chứa sự sai lệch, ví dụ dữ liệu văn bản sẽ thường sai chính tả và có các ký hiệu, URL không liên quan...
Khi dữ liệu được tiền xử lý và làm sạch đúng cách, các quy trình tiếp theo sẽ hoạt động chính xác hơn rất nhiều. Chúng ta thường nghe về tầm quan trọng của việc “ra quyết định dựa trên dữ liệu”, nhưng nếu những quyết định này được dẫn dắt bởi dữ liệu xấu, thì đó chính là những quyết định vô nghĩa.
Các bước tiền xử lý dữ liệu
1. Đánh giá chất lượng dữ liệu
Việc đầu tiên là bạn cần nắm được ý tưởng về chất lượng tổng thể, sau đó hãy xét kỹ dữ liệu, đánh giá mức độ phù hợp với dự án sao cho đáp ứng tính nhất quán. Một số điểm bất thường trong hầu hết mọi tập dữ liệu, có thể kể tên như:
- Dữ liệu không khớp: Khi bạn thu thập dữ liệu từ các nguồn khác nhau, dữ liệu có thể đến ở nhiều định dạng. Mặc dù mục tiêu cuối cùng của toàn bộ quá trình data preprocessing là định dạng lại dữ liệu cho máy, nhưng bạn vẫn cần bắt đầu với dữ liệu có định dạng tương ứng. Ví dụ: nếu bạn đang tiến hành nghiên cứu thu nhập của các gia đình trên nhiều quốc gia, thì bạn phải chuyển đổi từng khoản thu nhập đó thành một đơn vị tiền tệ duy nhất.
- Dữ liệu hỗn hợp: Có thể các nguồn khác nhau sẽ sử dụng các bộ mô tả khác nhau - ví dụ: man (người đàn ông) hoặc male (người có giới tính nam). Tất cả các mô tả phải được nhất quán.
- Dữ liệu ngoại lai: Ngoại lai có tác động rất lớn đến kết quả phân tích dữ liệu. Ví dụ: nếu bạn đang tính trung bình điểm kiểm tra cho một lớp, nhưng trong đó một học sinh không trả lời bất kỳ câu hỏi nào, thì 0% của học sinh đó có thể làm sai lệch kết quả rất nhiều.
- Dữ liệu bị thiếu: Hãy tìm các trường dữ liệu bị thiếu như khoảng trống trong văn bản hoặc câu hỏi khảo sát chưa được trả lời. Điều này có thể là lỗi của con người hoặc do dữ liệu không đầy đủ. Để xử lý dữ liệu bị thiếu, bạn sẽ phải tiến hành làm sạch dữ liệu.
2. Làm sạch dữ liệu
Làm sạch dữ liệu là quá trình thêm dữ liệu thiếu, sửa chữa hoặc xóa dữ liệu không chính xác hay không liên quan ra khỏi tập dữ liệu. Dọn dẹp theo ngày là bước quan trọng nhất của quá trình tiền xử lý vì nó sẽ đảm bảo rằng dữ liệu của bạn sẵn sàng đáp ứng các nhu cầu tiếp theo.
Làm sạch dữ liệu sẽ sửa tất cả dữ liệu không nhất quán đã được phát hiện trong bước đầu tiên. Tùy thuộc vào loại dữ liệu bạn đang làm việc, có một số trình dọn dẹp khả thi mà bạn sẽ cần để chạy dữ liệu của mình. Ví dụ: nếu là dữ liệu văn bản, thì một số thao tác làm sạch bạn nên cân nhắc là:
- Xóa URL, ký hiệu, biểu tượng cảm xúc... không liên quan đến phân tích
- Dịch tất cả văn bản sang một ngôn ngữ
- Xóa các thẻ HTML
- Xóa văn bản email soạn sẵn
- Xóa khoảng trống không cần thiết giữa các từ
- Xóa dữ liệu trùng lặp

3. Chuyển đổi dữ liệu
Bước chuyển đổi dữ liệu sẽ bắt đầu quá trình biến dữ liệu thành (các) định dạng phù hợp cho việc phân tích và các quy trình tiếp theo. Điều này thường xảy ra với một hoặc nhiều thao tác sau:
- Tổng hợp: kết hợp tất cả dữ liệu với nhau theo một định dạng thống nhất.
- Chuẩn hóa: chia tỷ lệ dữ liệu thành một phạm vi chuẩn hóa để bạn có thể so sánh dữ liệu một cách chính xác hơn.
- Lựa chọn thuộc tính: đây là quá trình quyết định biến nào (tính năng, đặc điểm, danh mục...) là quan trọng nhất. Các tính năng này sẽ được sử dụng để đào tạo các mô hình học máy. Điều cần lưu ý là sử dụng càng nhiều tính năng thì quá trình đào tạo sẽ càng tốn thời gian và đôi khi, kết quả lại càng kém chính xác.
- Sự rời rạc: Discretization tập hợp dữ liệu thành các khoảng nhỏ hơn, thường diễn ra sau khi dữ liệu đã được làm sạch. Ví dụ: khi phân tích hoạt động tập thể dục trung bình hàng ngày, thay vì để số phút và giây chính xác, bạn có thể kết hợp các dữ liệu tạo thành các khoảng 0-15 phút, 15-30...
- Tạo cấu trúc phân cấp khái niệm: bạn có thể thêm hệ thống cấp bậc bên trong và giữa các đối tượng dù đặc điểm không có trong dữ liệu gốc. Ví dụ: nếu phân tích của bạn gồm chó sói (wolves) và sói đồng hoang (coyotes), bạn có thể thêm thứ bậc chi của chúng là canis.
4. Giảm dữ liệu
Càng làm việc với nhiều dữ liệu thì việc phân tích sẽ càng khó khăn, ngay cả khi dữ liệu đã được làm sạch và chuyển đổi. Giảm dữ liệu không chỉ khiến việc phân tích trở nên dễ dàng và chính xác hơn mà còn giúp giảm dung lượng dùng để lưu trữ dữ liệu và xác định các tính năng quan trọng nhất đối với quy trình hiện tại.
- Lựa chọn thuộc tính: Tương tự như Discretization, lựa chọn thuộc tính có thể phù hợp với dữ liệu trong các nhóm nhỏ hơn. Về cơ bản, nó kết hợp các thẻ hoặc tính năng để các thẻ như nam/nữ và giáo sư có thể được kết hợp thành giáo sư nam/giáo sư nữ.
- Giảm số lượng
- Giảm kích thước
Ví dụ
Xem bảng dưới đây để biết cách hoạt động của Data preprocessing. Trong ví dụ này, chúng ta có ba biến: Name(tên), Age (tuổi) và Company (công ty). Trong ví dụ đầu tiên, chúng ta có thể thấy rằng #2 và #3 đã chỉ định sai công ty (Tesla - Elon Musk; Amazon - Jeff Bezos).
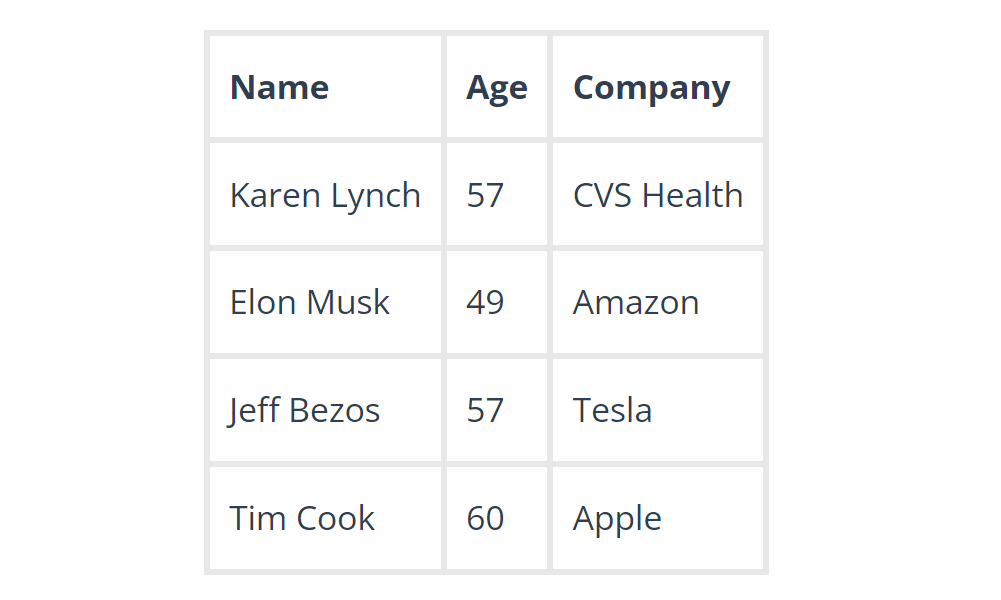
Nếu sử dụng tính năng làm sạch dữ liệu, #2 và #3 sẽ được một cách đơn giản vì chúng ta biết dữ liệu được nhập không đúng hoặc có thể bị lỗi.
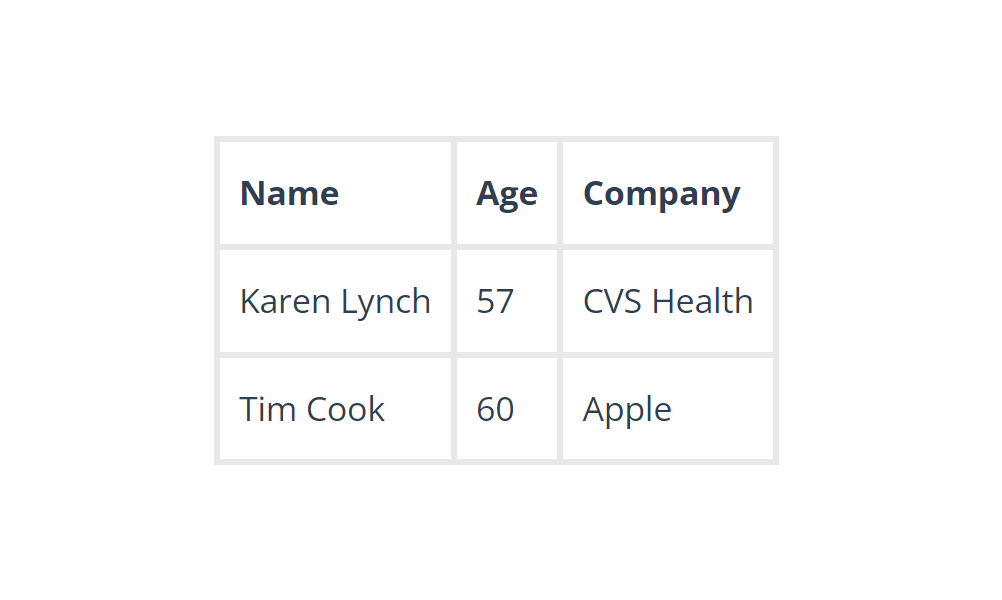
Hay theo cách khác, chúng ta có thể thực hiện chuyển đổi dữ liệu. Trong trường hợp này, cách thủ công để khắc phục sự cố như sau:
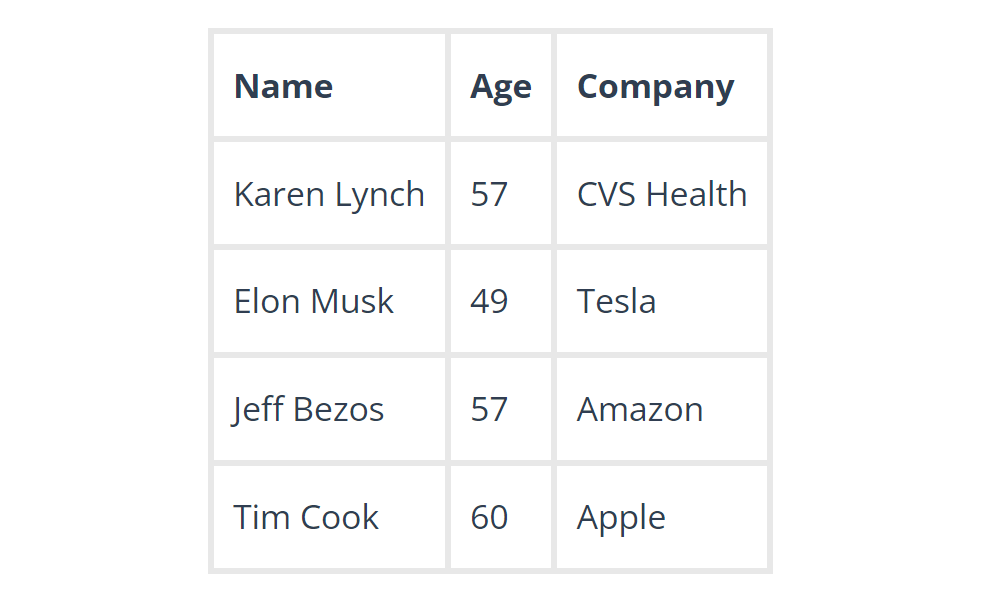
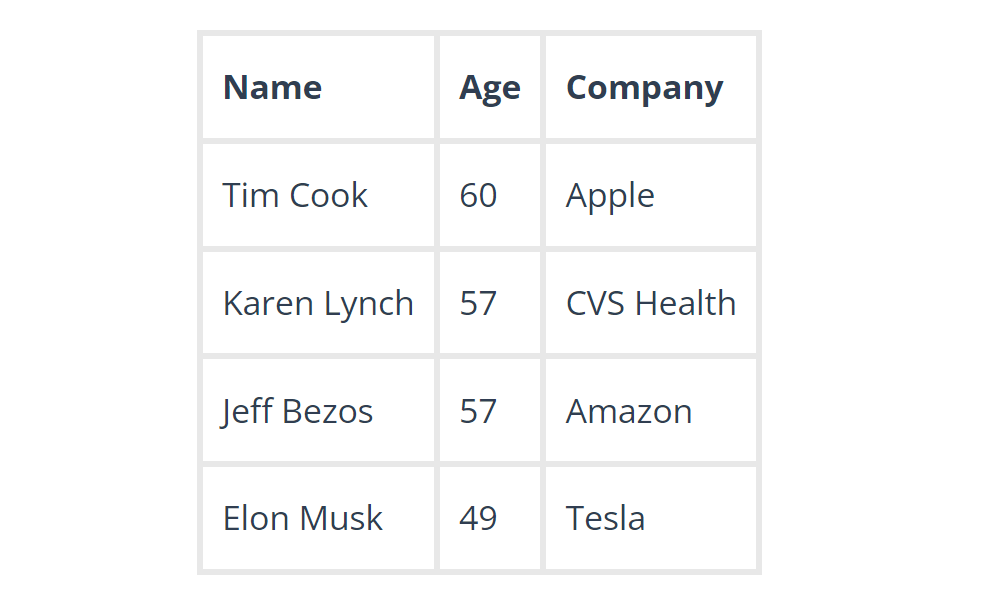
Sau khi sự cố được khắc phục, chúng ta có thể thực hiện bước giảm dữ liệu, có thể là theo độ tuổi giảm dần:
Data preprocessing được sử dụng như thế nào?
Tiền xử lý dữ liệu đóng một vai trò quan trọng trong các giai đoạn đầu của học máy và phát triển ứng dụng A. Trong bối cảnh AI, quá trình tiền xử lý dữ liệu được sử dụng để cải thiện cách dữ liệu được làm sạch, chuyển đổi và cấu trúc nhằm tăng độ chính xác của mô hình mới, đồng thời giảm lượng điện toán cần thiết.
Một quy trình tiền xử lý dữ liệu tốt có thể tạo ra các phần có thể tái sử dụng, giúp dễ dàng thử nghiệm các ý tưởng mới nhằm hợp lý hóa quy trình kinh doanh và cải thiện sự hài lòng của khách hàng. Ví dụ: data preprocessing có thể cải thiện cách tổ chức dữ liệu của công cụ đề xuất bằng cách cải thiện độ tuổi được sử dụng để phân loại khách hàng.
Data preprocessing cũng có thể đơn giản hóa công việc tạo và sửa đổi dữ liệu để có được những kiến thức kinh doanh thông minh (BI) được nhắm mục đích và chính xác hơn. Ví dụ: đối tượng khách hàng thường có quy mô, danh mục và khu vực khác nhau, do đó, họ có thể thể hiện các hành vi khác nhau. Việc tiền xử lý dữ liệu thành các biểu mẫu thích hợp có thể giúp các nhóm BI kết hợp những thông tin chuyên sâu vào bảng điều khiển BI.
*BI, Business Intelligence là tập hợp các kỹ thuật và công cụ để mua lại và chuyển đổi dữ liệu thô thành các thông tin có nghĩa và hữu ích cho phân tích kinh doanh nhằm mục đích.
Trong bối cảnh quản lý quan hệ khách hàng (CRM), data preprocessing là một phần của khai thác web. Nhật ký sử dụng web có thể được tiền xử lý để trích xuất bộ dữ liệu có ý nghĩa, hay còn được gọi là giao dịch của người dùng gồm các nhóm tham chiếu URL. Theo dõi các phiên giao dịch có thể xác định người dùng, các trang web và khoảng thời gian họ dành cho mỗi trang. Khi những thông tin này đã được tách ra khỏi dữ liệu thô, chúng mang lại nhiều thông tin hữu ích, như có thể áp dụng cho nghiên cứu người tiêu dùng, tiếp thị hoặc cá nhân hóa nội dung.
Kết luận
Việc ra quyết định chính xác đòi hỏi đầu vào dữ liệu tốt. Data preprocessing có thể là một quá trình tẻ nhạt nhưng một khi các phương pháp và quy trình đã được thiết lập, bạn sẽ nhận được nhiều lợi ích về sau.
Hy vọng bài viết trên đã giúp bạn hiểu được khái niệm về Data preprocessing. Theo dõi Meey Land để tìm hiểu thêm về thế giới công nghệ đầy lý thú!