Trí tuệ nhân tạo alphago là gì? Cơ chế hoạt động và ứng dụng thực tiễn
BÀI LIÊN QUAN
Một số ứng dụng và thành tựu của trí tuệ nhân tạo chẩn đoán ung thư sớmVai trò của trí tuệ nhân tạo AI ngành thương mại điện tửTìm hiểu tất tần tật về trí tuệ nhân tạoTrí tuệ nhân tạo Alphago là gì?
AlphaGo là một tác nhân của trí tuệ nhân tạo (AI) chuyên để chơi bộ môn cờ vây - trò chơi trên bàn cờ chiến lược của Trung Quốc. AlphaGo thuộc dự án DeepMind của Google. Với khả năng tạo ra một thuật toán học tập để có thể đánh bại người chơi trong các trò chơi chiến lược và là một thước đo cho sự phát triển của AI.
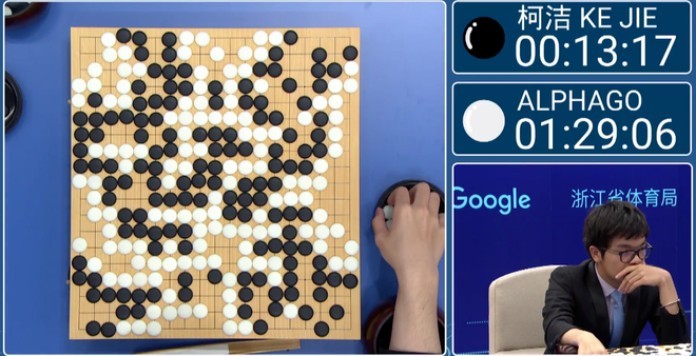
Trí tuệ nhân tạo AlphaGo đã giành chiến thắng trước nhà vô địch thế giới cờ vây Ke Jie vào năm 2017, và được mô tả như người ngoài hành tinh với trí tuệ vượt bậc. AlphaGo sử dụng một mạng nơ-ron thay vì hai loại mạng.
Các phiên bản trước của AlphaGo sử dụng mạng chính sách nhằm chọn nước đi tiếp theo để chơi và mạng giá trị để dự đoán người chiến thắng trò chơi ở mỗi vị trí.
Trong một bài báo xuất bản trên Nature vào năm 2017, DeepMind đã tiết lộ rằng một phiên bản mới của AlphaGo (đó là AlphaGo Zero) đã chọn cờ vây ngay từ đầu mà không nghiên cứu bất kỳ một trò chơi nào của con người. AlphaGo Zero chỉ mất có ba ngày để đạt được điểm khi đọ sức với một phiên bản cũ của chính mình và đã thắng 100 ván.
Một số thông tin cơ bản về trí tuệ nhân tạo alphago
Alphago viết bằng ngôn ngữ gì?
Tất cả code được thử và viết dựa trên Ubuntu 18.04 với việc sử dụng Python 2.7, Tensorflow v1. 7.0 và được biên dịch bằng NVCC V9. 0.176 (Nvidia Cuda compiler).
Phần cứng của AlphaGo
Các phiên bản đầu tiên của AlphaGo được thử nghiệm trên phần cứng có GPU và CPU khác nhau trong chế độ chạy không đồng bộ hay phân tán. Dưới đây là bảng kết quả Elo.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Vào tháng 05 năm 2016, Google đã công bố những bộ xử lý chuyên dụng của riêng hãng. Công ty đang triển khai trong nhiều dự án nội bộ của Google, gồm cả trận đấu của AlphaGo với Lee Sedol.
Thuật toán của AlphaGo
Dựa trên các thuật toán phân tích phương án xác suất kết hợp với cùng các bộ quy tắc, giúp cho AlphaGo có thể đưa ra nước đi đúng đắn. Hơn nữa, nhờ được thiết kế dựa trên mô phỏng hoạt động não người, phần mềm này có thể phân tích bài học từ những sai lầm trước đó để đưa ra phương án tốt hơn cho lần chơi sau.
Qua đó, AlphaGo sẽ liên tục cập nhật dữ liệu những trận đấu cờ vây trên khắp thế giới. Ngoài ra, theo nhà đồng sáng lập DeepMind thì phần mềm này sẽ học cách để đánh thắng chính mình, bằng cách phân thân tư duy độc lập và liên tục học hỏi và thực hành.

Nhờ vậy, vào năm 2015, AlphaGo lần đầu tiên đánh bại nhà vô địch châu Âu - Fan Hui với tỉ số là 5-0. Đến năm tiếp theo đã hạ gục cao thủ 9 đẳng Le Sedol tỉ số 4-1. Theo Economist, AlphaGo đã sử dụng 1.920 CPU và 280 GPU để có thể chạy thuật toán.
Trong khoảng thời gian từ 2016 đến đầu năm 2017, rất nhiều các trận đấu của AlphaGo với những cao thủ trong giới cờ vây đã bí mật liên tục diễn ra. Phần thắng nghiêng về AlphaGo bởi các cao thủ mắc quá nhiều sai lầm. Kỷ lục của phần mềm này đã lên đến 60 trận thắng và 0 trận thua.
Cơ chế hoạt động của AlphaGo như thế nào?
AlphaGo sử dụng 4 Deep Convolutional Neural Network (mạng nơ-ron tích chập sâu), 3 Policy Network (mạng chính sách) và 1 Value Network (mạng giá trị).
Trong đó:
- Supervised Learning Policy Network (là mạng chính sách học có giám sát): 2 mạng chính sách được học từ những nước đi thần thánh của các kì thủ, hay còn được gọi là Imitation Learning (học bắt chước).
- Reinforcement Learning Policy Network (là mạng chính sách học tăng cường): Mạng chính sách thứ ba này được học tăng cường dựa vào cơ chế self-play (tức tự chơi). Mạng hiện tại sẽ chơi với một mạng được chọn ngẫu nhiên từ một số lần lặp trước đó.
- Rollout policy (tức chính sách triển khai) là một loại mạng nơ-ron nhỏ hơn. Do đó, độ chính xác mô hình hóa các nước đi sẽ thấp hơn đáng kể so với mạng dung lượng lớn hơn. Tuy nhiên, thời gian suy luận của mạng chính sách triển khai là rất ngắn, điều này rất hữu ích với việc mô phỏng trên cây tìm kiếm Monte Carlo.
- Tiếp đó, bộ dữ liệu self-play (tự chơi) sẽ đào tạo mạng giá trị để dự đoán người thắng cuộc tại các trạng thái hiện tại của trò chơi.

Cuối cùng, toàn bộ những mạng trạng thái và mạng giá trị ở trên sẽ được gom lại và đưa vào Monte Carlo Tree Search (tức Cây tìm kiếm Monte Carlo). Cây Monte Carlo hoạt động dựa trên 4 cơ chế chính đó là : Selection (lựa chọn) – Expansion (mở rộng) – Evaluation (đánh giá) – Backup (cập nhật). Chuỗi nước đi đại diện sẽ một nhánh cây. Nhánh được truy cập nhiều nhất chắc hẳn được đánh dấu là nước đi tốt nhất.
Ứng dụng của trí tuệ nhân tạo alphago
Chiến thắng của AlphaGo không chỉ là yếu tố thể hiện sức mạnh của máy móc mà còn là minh chứng cho tính ưu việt của thuật toán xử lý mới. Từ đó mở đường cho các bước phát triển cao cấp đầu tiên của các hệ thống trí tuệ nhân tạo (AI). Nhưng AlphaGo không được sinh ra với mục đích chỉ để chơi game. Điều mà dự án Google Deepmind hướng tới đó chính là áp dụng trí tuệ nhân tạo để phục vụ cho cuộc sống hằng ngày.
Thông qua AlphaGo và các dự án của Google DeepMind, ông Demis Hassabis, Giám đốc điều hành dự án Google Deepmind còn muốn áp dụng trí tuệ nhân tạo trong những ứng dụng quan trọng. Những nghiên cứu về mạng nơron đã đạt nhiều thành công và trong tương lai có thể được áp dụng vào thực tế.
Trong ngắn hạn, đó chắc chắn sẽ là những trợ lý ảo trên chiếc điện thoại thông minh. Trong trung hạn, đó có thể là các hệ thống chuẩn đoán bệnh hay dự đoán thời tiết và thiên tai.
Còn trong dài hạn, ông Hassabis đã đặt mục tiêu sử dụng hệ thống máy tính siêu thông minh để có thể giúp con người tạo ra những đột phá trong nghiên cứu khoa học, điều mà thông thường sẽ mất đến hàng thế kỷ nhưng có thể được rút ngắn chỉ với vài năm nhờ trí thông minh nhân tạo.
Một số lưu ý khi sử dụng sản phẩm công nghệ từ Alphago
AlphaGo đang suy nghĩ theo cách của con người, nhưng mà nhanh hơn rất nhiều. Nhờ sự phát triển trong các sáng tạo của con người, trí tuệ nhân tạo AlphaGo được xây dựng dựa trên việc mô phỏng các hoạt động não người, có thể tư duy chuyên sâu và dễ dàng vượt qua con người trong bất cứ phép thử logic thuần túy nào. Song được tích hợp thêm khả năng học hỏi, bên cạnh quyền truy cập các nguồn dữ liệu khổng lồ, AI sẽ sở hữu khả năng tự học hỏi chuyên sâu.
Trên thực tế, mặc dù máy móc vượt trội hơn con người về nhiều khả năng, nhưng vẫn chỉ là công cụ được sử dụng bởi con người. Mối nguy hiểm của trí thông minh nhân tạo (AI) giống như AlphaGo thực tế không nằm ở nguy cơ thống trị nhân loại, mà Alphago có thể khiến con người đánh mất tinh thần chiến đấu và ý thức về mục đích.
Bởi vậy khi sử dụng những sản phẩm công nghệ được ứng dụng Alphago nói riêng hay trí tuệ nhân tạo nói chung người dùng cần hết sức lưu ý và không phụ thuộc quá nhiều vào các sản phẩm này.
Hy vọng bài viết trên đã cung cấp cho bạn những thông tin hữu ích về trí tuệ nhân tạo Alphago. Để bạn có thể hiểu rõ hơn về Alphago cũng như ứng dụng thực tiễn của công nghệ này đem lại cho cuộc sống bạn.