Kafka là gì? Các trường hợp sử dụng Kafka
BÀI LIÊN QUAN
Ngôn ngữ máy tính là gì? Những ứng dụng của ngôn ngữ máy tínhComputer Vision là gì? Ứng dụng của thị giác máy tính trong cuộc sốngKỹ thuật máy tính là gì? Sự khác nhau giữa kỹ thuật máy tính và khoa học máy tínhKafka là gì?
Kafka là một phần mềm nguồn mở với mục đích lưu trữ, đọc và phân tích dữ liệu phát trực tuyến (streaming data).
*Streaming data là dữ liệu được phát khối lượng lớn theo cách tăng dần và liên tục nhằm xử lý với độ trễ thấp. Nó gồm dữ liệu về vị trí, sự kiện và cảm biến được sử dụng để quan sát và phân tích nhiều khía cạnh kinh doanh theo thời gian thực.
Là nền tảng nguồn mở tức là về cơ bản bạn có thể sử dụng Kafka miễn phí. Đồng thời nó sở hữu cộng đồng gồm người dùng và lập trình viên lớn, cùng đóng góp các bản cập nhật, tính năng mới và hỗ trợ người dùng mới.
Kafka được thiết kế để chạy trong môi trường “phân tán” (distributed), tức là thay vì nằm trên máy tính của một người dùng, Kafka chạy trên một số (hoặc nhiều) máy chủ, tận dụng sức mạnh xử lý bổ sung và dung lượng lưu trữ môi trường phân tán mang lại.
Kafka được tạo ra tại LinkedIn. Sau đó, nó trở thành nền tảng nguồn mở và được chuyển cho Quỹ Apache vào năm 2011.

Kafka dùng để làm gì?
Để duy trì tính cạnh tranh, các doanh nghiệp ngày càng phụ thuộc vào phân tích dữ liệu thời gian thực. Điều cho phép họ có được thông tin chi tiết (insight) nhanh hơn. Thông tin chi tiết theo thời gian thực cho phép các doanh nghiệp dự đoán về những gì họ nên dự trữ, quảng cáo hoặc lấy ra khỏi kệ, mang tính cập nhật nhất có thể.
Nhờ tính chất phân tán và quản lý dữ liệu hợp lý, Kafka hoạt động rất nhanh trong việc theo dõi các cụm lớn và phản ứng với hàng triệu thay đổi của tập dữ liệu mỗi giây. Đây chính là tính năng truyền dữ liệu trong thời gian thực của Kafka.
Kafka ban đầu được thiết kế để theo dõi hành vi của khách truy cập trên các website lớn (như LinkedIn). Bằng cách phân tích dữ liệu luồng nhấp chuột (cách người dùng điều hướng website và tính năng họ sử dụng) của mỗi phiên, các tổ chức có thể hiểu rõ hành vi của người dùng hơn. Điều này cho phép họ dự đoán những thông tin hoặc sản phẩm mà khách truy cập có thể quan tâm.
Kể từ đó, Kafka được sử dụng rộng rãi và trở thành một phần không thể thiếu trong ngăn xếp (stack) tại Spotify, Netflix, Uber, Goldman Sachs, Paypal và CloudFlare, tất cả đều sử dụng Kafka để xử lý dữ liệu truyền phát và hiểu hành vi của khách hàng. Thực tế, theo thống kê của Kafka, cứ năm doanh nghiệp trong danh sách Fortune 500 thì sẽ có một doanh nghiệp sử dụng Kafka ở mức độ nhất định.
Lĩnh vực mà Kafka đang “thống trị chính là du lịch, nơi khả năng streaming khiến nó trở thành công cụ lý tưởng để theo dõi quy trình đặt chỗ của hàng triệu chuyến bay, kỳ nghỉ trọn gói và phòng trống của các khách sạn trên toàn thế giới.
Kafka hoạt động như thế nào?
Kafka lấy thông tin từ lượng lớn nguồn dữ liệu (Producer) và tổ chức chúng thành các “Topic” (chủ đề). Ví dụ: Kafka có thể lấy dữ liệu là nhật ký giao dịch của cửa hàng tạp hóa, dữ liệu được ghi lại sau mỗi lần bán hàng.
Kafka sẽ xử lý luồng thông tin này và tạo “topic” - như “số lượng táo đã bán” hay “số đơn bán từ 1 giờ chiều đến 2 giờ chiều” - để những người cần thông tin chi tiết có thể tiến hành phân tích dữ liệu. Điểm đặc biệt của Kafka nằm ở chỗ, nó phù hợp với chuỗi cửa hàng tạp hóa quốc gia, nơi xử lý hàng nghìn lượt bán táo mỗi phút.
Thông thường, luồng dữ liệu (data stream) này sẽ được lưu trữ trong các hồ dữ liệu (data lake), như cơ sở dữ liệu phân tán của Hadoop, hoặc cung cấp cho các đường ống xử lý thời gian thực, như Spark, Storm.
Một giao diện khác - được gọi là Consumer - cho phép Kafka đọc nhật ký topic và chuyển thông tin cần thiết đến các ứng dụng khác. Ví dụ: Hệ thống cửa hàng tạp hóa bổ sung mặt hàng đã hết hoặc loại bỏ hàng hết hạn.
Sơ đồ vận hành của Kafka như sau:
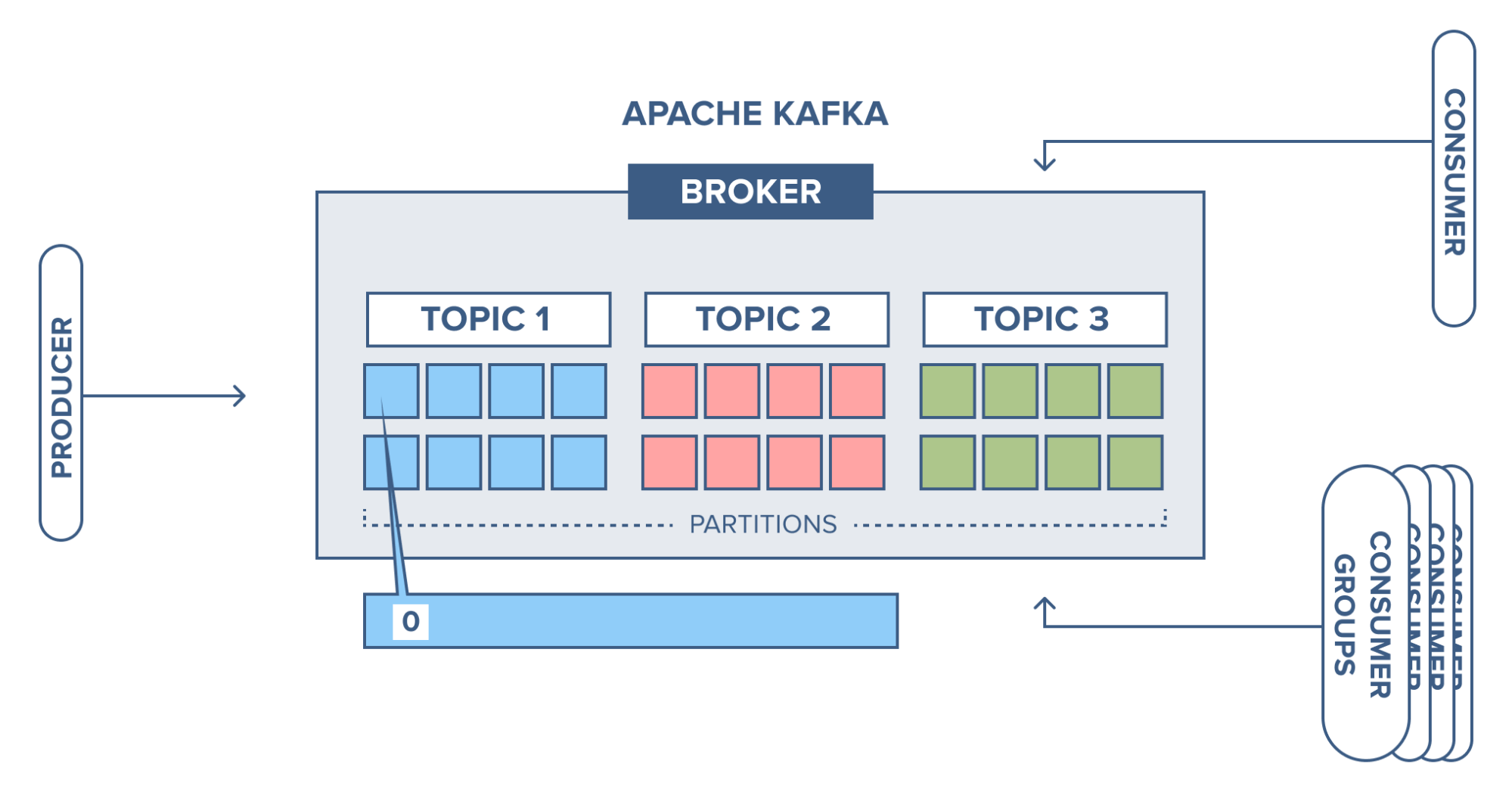
Trong đó,
- Producer: một ứng dụng hoặc quy trình tạo và gửi dữ liệu.
- Consumer: ứng dụng hoặc quy trình nhận thông báo do Producer tạo ra.
- Broker: một nút chuyển thông báo từ Producer sang Consumer.
- Topic: một kho lưu trữ ảo các thông báo có cùng nội dung hoặc nội dung tương tự, để Consumer: truy xuất thông tin cần thiết từ đó.
Tóm lại, Kafka hoạt động như sau:
- Producer tạo một thông báo và gửi nó đến nút Kafka.
- Broker lưu trữ thông báo trong một topic mà các ứng dụng của Consumer đã đăng ký.
- Consumer yêu cầu topic, nếu cần và lấy dữ liệu mong muốn từ topic đó.
Lợi ích của Kafka là gì?
Nguồn mở
Kafka là một nền tảng nguồn mở của Apache Software Foundation và phát triển liên tục với cộng đồng lập trình viên lớn. Về cơ bản, Kafka hoàn toàn miễn phí, người dùng có thể dễ dàng tìm kiếm những bản cập nhật phần mềm, tính năng mới và các hướng dẫn, đánh giá khác nhau.
Khả năng mở rộng
Bằng cách chia topic thành nhiều phân vùng (partition), Apache Kafka có thể mở rộng quy mô mà không cần tắt toàn bộ hệ thống. Cho phép người dùng tăng giảm quy mô bằng cách thêm máy mới vào cụm. Điều này giúp website duy trì hoạt động ngay cả trong quá trình nâng cấp dung lượng máy chủ. Nếu cần, hệ thống có thể dễ dàng thu nhỏ bằng cách loại bỏ các máy không cần thiết khỏi cụm.
Hiệu suất cao
Vì Kafka là một hệ thống phân tán nên nó có thể mở rộng theo nhu cầu dữ liệu. Với công nghệ Kafka Streams, có thể xử lý lượng lớn dữ liệu. Nhờ làm việc với các mảng RAID lớn của máy chủ nên Kafka ghi, đọc và xử lý dữ liệu khá nhanh. Nó có thể gửi thông báo trong điều kiện thông lượng mạng giới hạn bằng cách sử dụng một cụm máy chủ có độ trễ cực thấp (thấp nhất là 2 mili giây).
Khả năng chịu lỗi và độ tin cậy
Kafka là một hệ thống phân tán với các nút nằm trong nhiều cụm. Sau khi nhận được thông tin từ Producer, nó sao chép thông tin đó và lưu trữ các bản sao trên nhiều nút khác nhau. Do đó, trong trường hợp xảy ra lỗi hệ thống bất ngờ, tất cả thông tin có thể được khôi phục ngay lập tức và không bị mất.
Có nên sử dụng Kafka?
Kafka Apache là một công cụ hiệu quả để chạy các dự án server trên mọi quy mô. Do tính linh hoạt và khả năng chịu lỗi, Kafka hỗ trợ các trường hợp yêu cầu băng thông cao và khả năng mở rộng; nó có thể xử lý lượng dữ liệu khổng lồ từ IoT và được sử dụng trong các dịch vụ truyền phát video, cũng như phân tích Big Data.

Các trường hợp sử dụng Apache Kafka tốt nhất
Theo dõi hoạt động website
Đây là mục đích sử dụng ban đầu của Kafka. Theo dõi hoạt động thường có khối lượng rất cao vì mỗi lần xem trang của người dùng tạo ra rất nhiều thông báo hoạt động như: số lần click của người dùng, đăng ký, lượt thích, thời gian xem trang, yêu cầu
Những sự kiện này có thể được xuất bản cho các topic dành riêng cho Kafka. Mỗi nguồn cấp dữ liệu có thể được dùng cho bất kỳ trường hợp sử dụng nào, như tải vào hồ dữ liệu (data lake) để xử lý, giám sát, phân tích, báo cáo, v.v.
Xử lý dữ liệu thời gian thực
Kafka truyền dữ liệu từ Producer đến Consumer với độ trễ rất thấp (thấp nhất là 2 mili giây). Điều này rất hữu ích cho:
- Các tổ chức tài chính: để thu thập và xử lý các khoản thanh toán và giao dịch tài chính trong thời gian thực, ngăn chặn các giao dịch gian lận ngay khi phát hiện
- IoT: trong đó các mô hình liên tục phân tích các luồng số liệu từ thiết bị và kích hoạt cảnh báo ngay khi phát hiện sai lệch có thể cho thấy sự cố sắp xảy ra.
- Ô tô tự lái: yêu cầu xử lý dữ liệu theo thời gian thực để điều hướng môi trường vật lý.
- Các doanh nghiệp hậu cần: theo dõi và cập nhật các ứng dụng theo dõi, như để theo dõi liên tục các tàu chở hàng để ước tính thời gian vận chuyển hàng hóa.
Message broker
Kafka hoạt động tốt như một sự thay thế cho các message broker truyền thống. Nó có thông lượng tốt hơn, phân vùng tích hợp, sao chép và khả năng chịu lỗi, cũng như các thuộc tính mở rộng tốt hơn.
Dữ liệu vận hành
Kafka thường được sử dụng cho dữ liệu giám sát hoạt động, liên quan đến việc tổng hợp số liệu thống kê từ các ứng dụng phân tán để tạo ra nguồn cấp dữ liệu vận hành tập trung.
Tổng hợp log
Nhiều tổ chức sử dụng Kafka để tổng hợp log. Tổng hợp log thường là thu thập tệp nhật ký vật lý từ máy chủ và đặt chúng vào kho lưu trữ trung tâm để xử lý. Kafka lọc ra các chi tiết của tệp và tóm tắt dữ liệu dưới dạng một luồng thông báo. Nhờ đó, quá trình xử lý có độ trễ thấp hơn và hỗ trợ nhiều nguồn dữ liệu hơn.
Ứng dụng của Kafka trong thực tế
Khả năng của Apache Kafka đã mang đến sự đổi mới trong các doanh nghiệp. Khi có nhiều hơn các tổ chức dựa trên dữ liệu và dựa trên đám mây, Apache Kafka giống như “hệ thống thần kinh trung ương” của các nhà máy sản xuất, robotic, phân tích tài chính, sale, marketing và phân tích mạng.
Dưới đây là một số cách Apache Kafka đang được sử dụng trong doanh nghiệp:
- Ngân hàng: Trên thế giới, ING Bank, CapitalOne, RobinHood và nhiều dịch vụ ngân hàng khác đang sử dụng Apache Kafka để phát hiện gian lận theo thời gian thực, an ninh mạng và tuân thủ quy định. Các nhóm tài chính cũng sử dụng Kafka trong các ứng dụng giao dịch trên thị trường chứng khoán, như nền tảng lượng tử và biểu đồ chứng khoán ML/DL để phân tích dữ liệu.
- Bán lẻ: Apache Kafka được các công ty như Walmart, Lowe's, Domino's và Bosch sử dụng để đề xuất sản phẩm, quản lý hàng tồn kho, giao hàng, tối ưu hóa chuỗi cung ứng và tạo trải nghiệm đa kênh. Các công ty thương mại điện tử cũng sử dụng Kafka trên nền tảng của họ để phân tích lưu lượng và chống gian lận thời gian thực.
- Chăm sóc sức khỏe: Độ trễ thấp của hệ thống giám sát thời gian thực của Kafka đóng vai trò quan trọng trong các bệnh viện, cho phép nhân viên y tế phản hồi các vấn đề quan trọng bằng cảnh báo hệ thống.
- IoT: Các công ty như Audi, E.ON, Target và Severstal đang đổi mới bằng các thiết bị IoT sử dụng Kafka.
- Viễn thông: Apache Kafka được sử dụng rộng rãi trong lĩnh vực truyền thông trên toàn thế giới như một phần của các giải pháp OSS, BSS, OTT, IMS, NFV, Middleware, Mainframe, v.v.. Netflix, 8x8, Tivo và Sky cũng sử dụng Kafka cho các dịch vụ của họ.
Hy vọng rằng bài viết này đã cung cấp cái nhìn tổng quan về Kafka là gì, cách thức hoạt động và lý do Kafka được sử dụng rộng rãi như vậy.