Data Sampling là gì? Các phương pháp lấy mẫu dữ liệu
BÀI LIÊN QUAN
Data Labeling và các phương pháp gán nhãn dữ liệu là gì?Data Lake là gì? 5 khác biệt lớn giữa Data Lake và Data WarehouseData exploration là gì? Vì sao công cụ này đóng vai trò quan trọngData Sampling là gì?
Data sampling, lấy mẫu dữ liệu, là một kỹ thuật phân tích thống kê được sử dụng để chọn, xử lý và phân tích một tập hợp con đại diện của tổng thể (population). Nó cũng được sử dụng để nhận dạng mẫu và xu hướng ngoại suy trong tổng thể.
Với data sampling, các nhà nghiên cứu, nhà khoa học dữ liệu, nhà lập mô hình dự đoán và các nhà phân tích dữ liệu khác có thể sử dụng lượng dữ liệu nhỏ hơn, dễ quản lý hơn cho việc xây dựng và chạy các mô hình phân tích. Điều này cho phép họ nhanh chóng đưa ra những phát hiện chính xác từ một tổng thể thống kê.
Phương pháp Data Sampling
Có nhiều phương pháp data sampling, mỗi phương pháp đều có những đặc điểm phù hợp với loại bộ dữ liệu (dataset), nguyên tắc và mục tiêu nghiên cứu. Các phương pháp được chia thành hai loại là lấy mẫu xác suất (probability sampling) và lấy mẫu phi xác suất (non-probability sampling).

Probability Sampling
Lấy mẫu xác suất sử dụng các số ngẫu nhiên - tương ứng với các điểm trong tập dữ liệu. Điều này đảm bảo các lựa chọn mẫu không có sự tương quan. Với probability sampling, các mẫu được chọn từ một tổng thể lớn hơn để phù hợp với các phương pháp thống kê khác nhau.
Lấy mẫu dữ liệu xác suất là cách tiếp cận tốt nhất khi mục tiêu là tạo ra một mẫu đại diện chính xác cho tổng thể. Các loại Probability sampling gồm:
Lấy mẫu ngẫu nhiên đơn giản
Mọi phần tử trong tập dữ liệu có xác suất được chọn như nhau. Quá trình lấy mẫu ngẫu nhiên đơn giản (Simple Random Sampling) thường được thực hiện bằng cách ẩn tổng thể. Chẳng hạn, tổng thể có thể được ẩn bằng cách gắn các phần tử trong đó một số và sau đó chọn chúng một cách ngẫu nhiên.
Lợi ích của Simple Random Sampling là dễ dàng và không tốn kém, đồng thời loại bỏ sai lệch trong quá trình lấy mẫu. Hạn chế của phương pháp này là các nhóm sẽ không mang tính đại diện, bởi các nhà nghiên cứu không nắm quyền kiểm soát việc chọn mẫu.

Lấy mẫu phân tổ
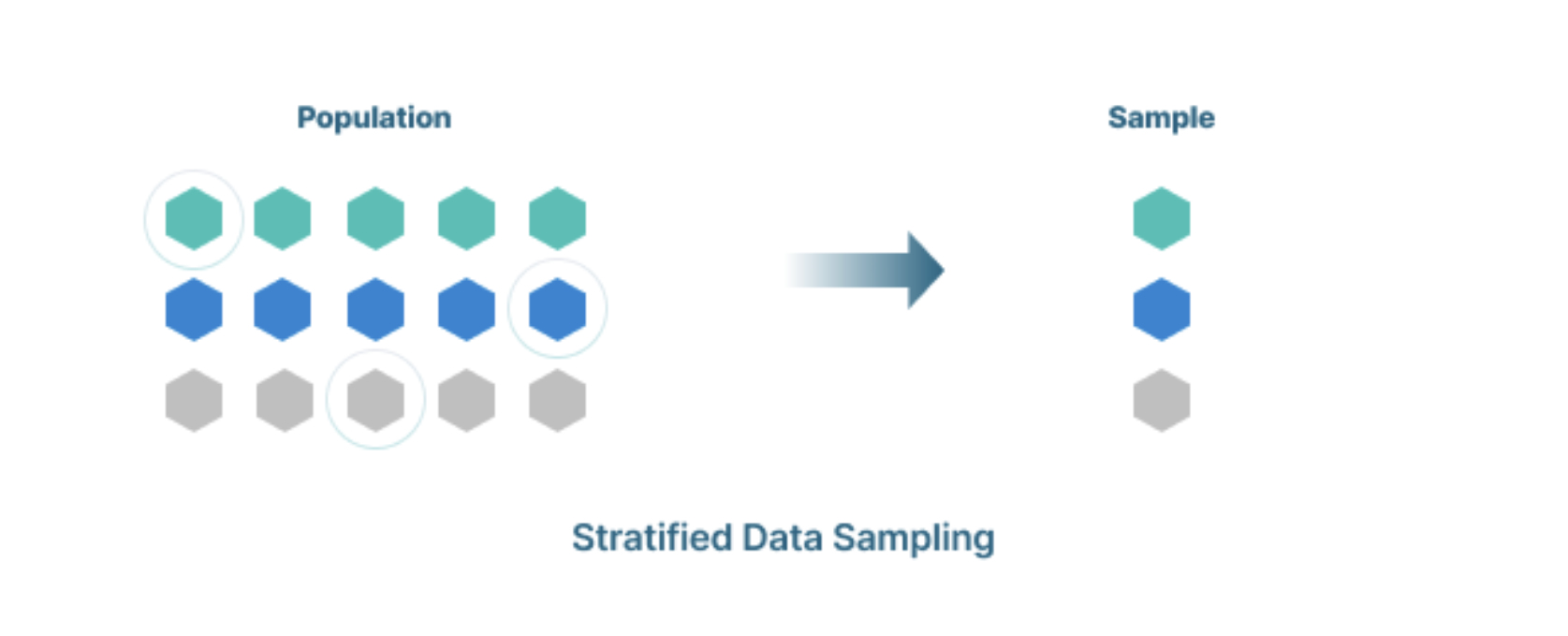
Lấy mẫu phân tổ (Stratified Sampling) được sử dụng khi các nhóm phải dựa trên một yếu tố chung. Với lấy mẫu phân tầng, tất cả các yếu tố của tổng thể được biểu diễn dưới dạng mẫu và được lấy từ các tầng khác nhau (ví dụ: trong nghiên cứu các mẫu đi làm, mẫu có thể được tách thành những người sử dụng phương tiện giao thông công cộng, đi bộ, đi xe đạp hoặc xe ô tô). Tuy nhiên, hạn chế của phương pháp này chính là sự thiên vị.
Lấy mẫu cả khối
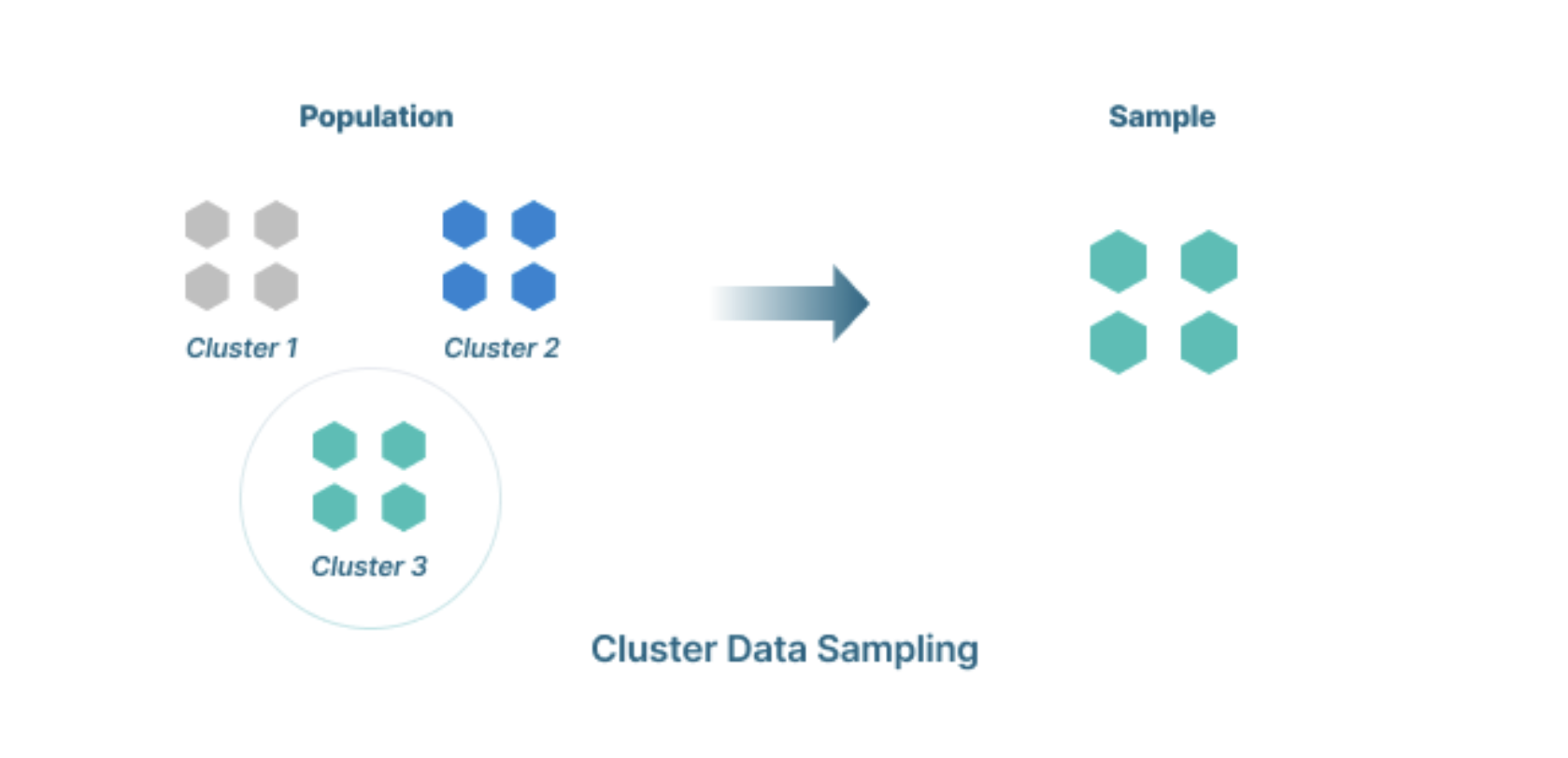
Phương pháp Lấy mẫu cả khối (Cluster Sampling) chia bộ dữ liệu thành các tập hợp con hoặc cụm theo một yếu tố xác định; sau đó, các mẫu được chọn ngẫu nhiên. Với cluster sampling, mẫu được lấy ngẫu nhiên từ các nhóm (ví dụ: những người sống ở cùng một thành phố cụ thể, những người sinh cùng một năm) chứ không phải các phần tử riêng lẻ.
Lấy mẫu có hệ thống hoặc phân cụm có hệ thống
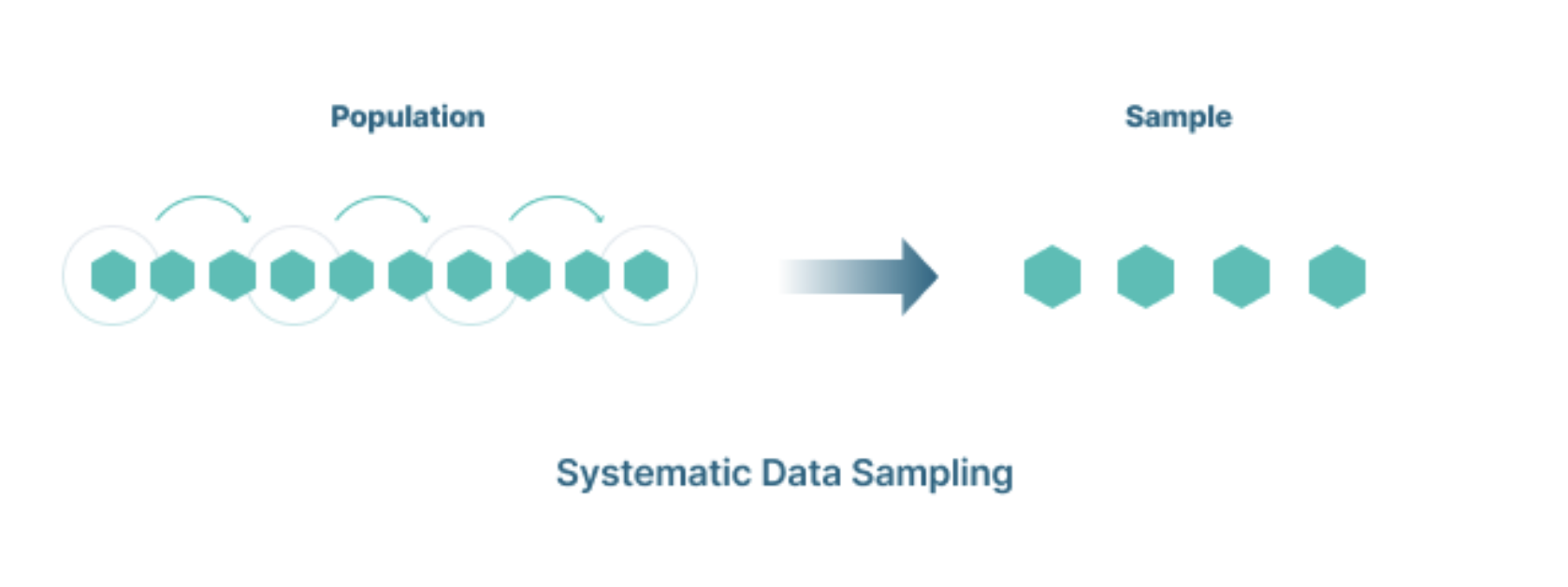
Systematic Sampling hoặc Systematic Clustering tạo mẫu bằng cách đặt thời gian để trích xuất dữ liệu theo quy tắc. Với lấy mẫu hoặc phân cụm có hệ thống, yếu tố ngẫu nhiên chỉ áp dụng cho mục được lựa chọn đầu tiên. Sau đó, sẽ áp dụng theo quy tắc.
Non-probability sampling
Với lấy mẫu phi xác suất, mẫu được xác định và trích xuất dựa trên đánh giá chủ quan của người nghiên cứu hoặc người phân tích. Hạn chế của phương pháp này là nó có thể bị sai lệch và có thể không đại diện chính xác cho tổng thể.
Lấy mẫu phi xác suất được sử dụng trong trường hợp cần phân tích nhanh hay đơn giản. Các loại Non-probability sampling bao gồm:
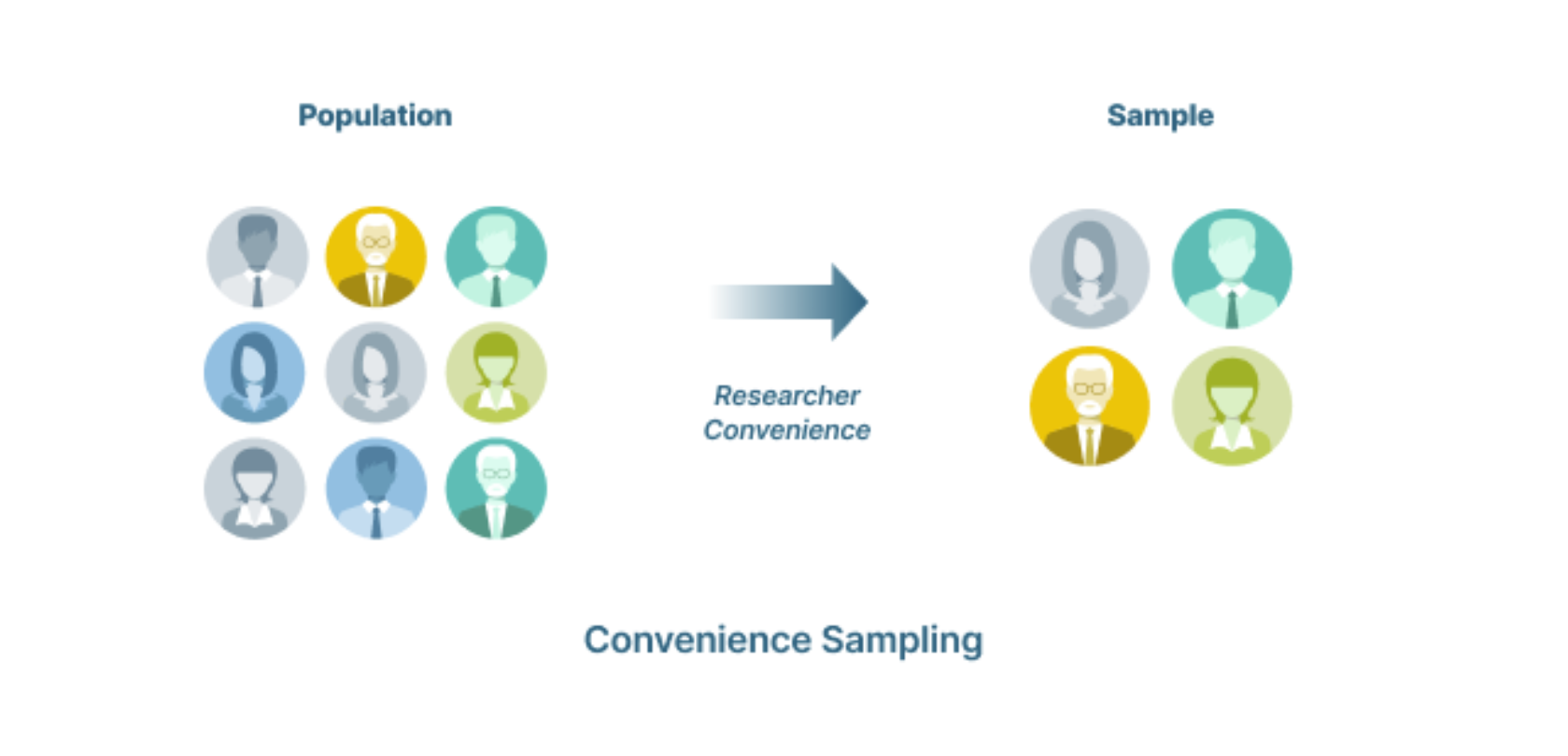
Lấy mẫu thuận tiện
Lấy mẫu thuận tiện (Convenience Sampling) là thu thập dữ liệu từ một nhóm có sẵn và dễ tiếp cận. Ví dụ convenience sampling sẽ yêu cầu những người ngoài cửa hàng thực hiện khảo sát. Các yếu tố được thu thập dựa trên khả năng tiếp cận và tính sẵn có.
Lấy mẫu thuận tiện thường được sử dụng như bước sơ bộ nên độ chệch có thể khá đáng kể.
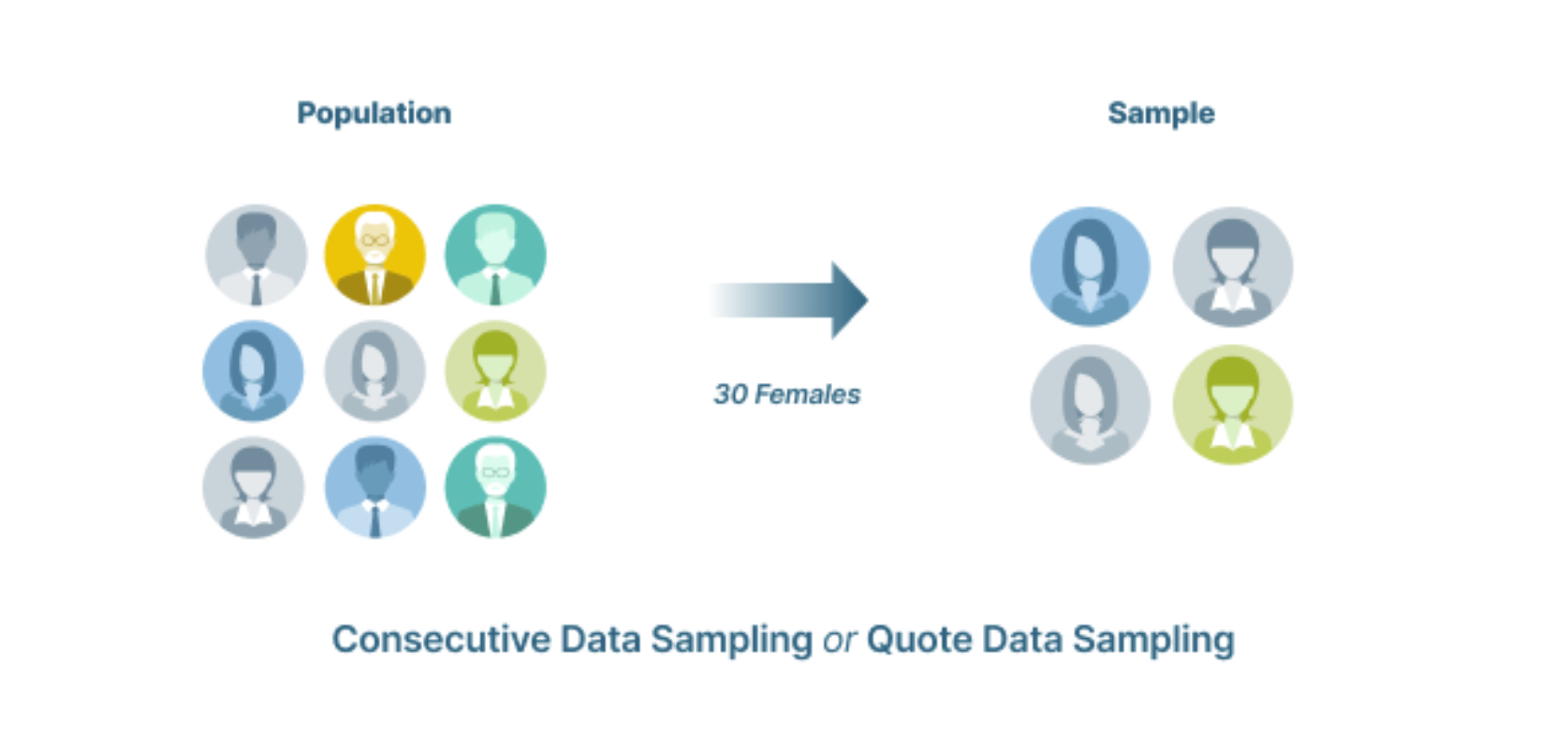
Lấy mẫu liên tiếp
Lấy mẫu liên tiếp (Consecutive Sampling) thu thập dữ liệu từ các nguồn đáp ứng các tiêu chí cho đến khi đạt được kích thước mẫu mong muốn.
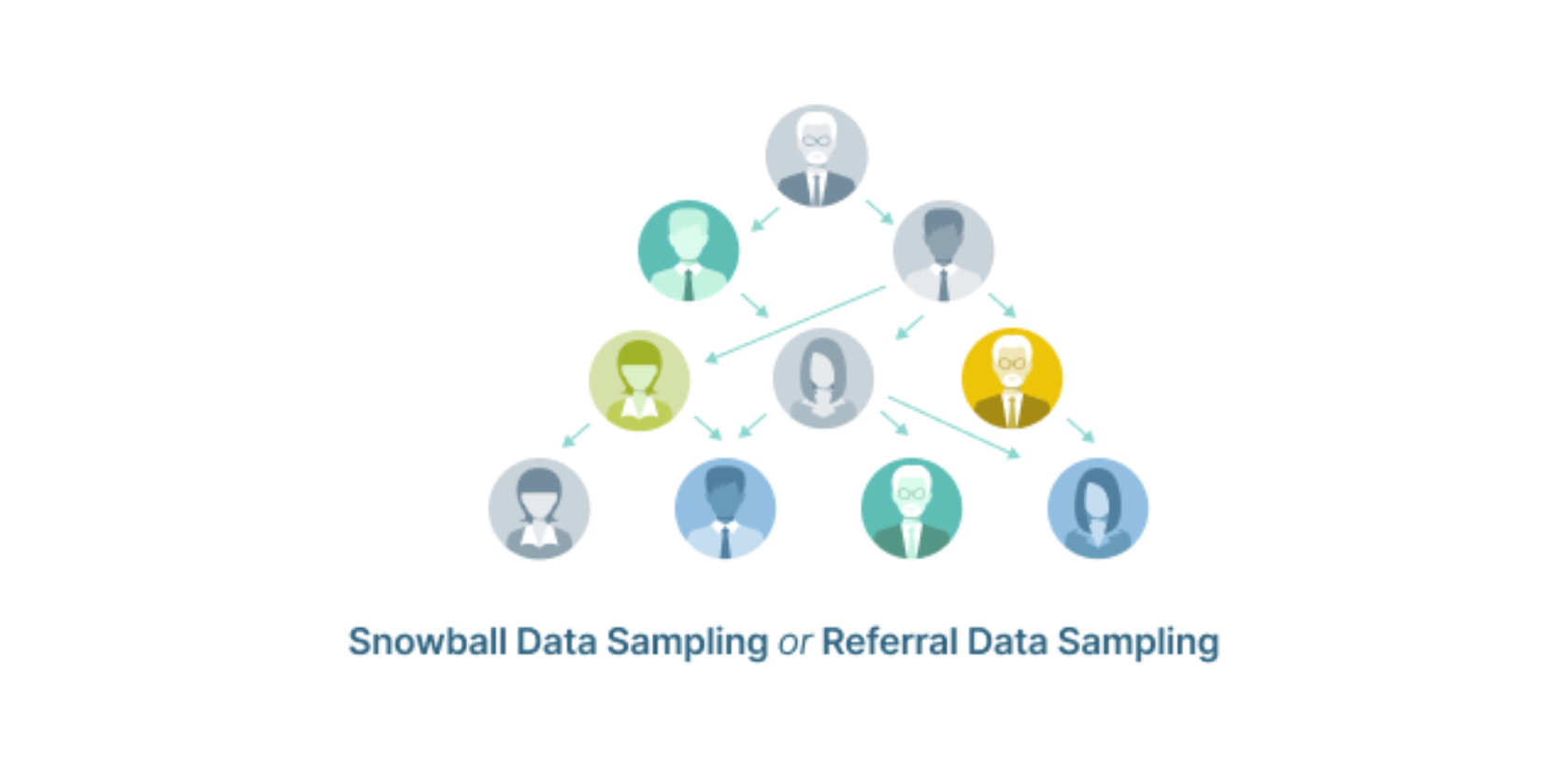
Lấy mẫu quả cầu tuyết
Snowball Sampling thu thập các phần tử cho tập dữ liệu bằng cách tập hợp những phần tử liên quan. Bản chất của phương pháp là dựa trên các phần tử đã có để tìm thêm các phần tử khác, phù hợp với tổng thể - ví dụ: tập hợp một nhóm nhỏ, sau đó yêu cầu họ mời bạn bè tham gia.
Snowball Sampling được sử dụng khi tổng thể không xác định và khó xây dựng bộ dữ liệu. Bởi nó dựa trên các lượt giới thiệu nên sự thiên vị sẽ tăng lên.
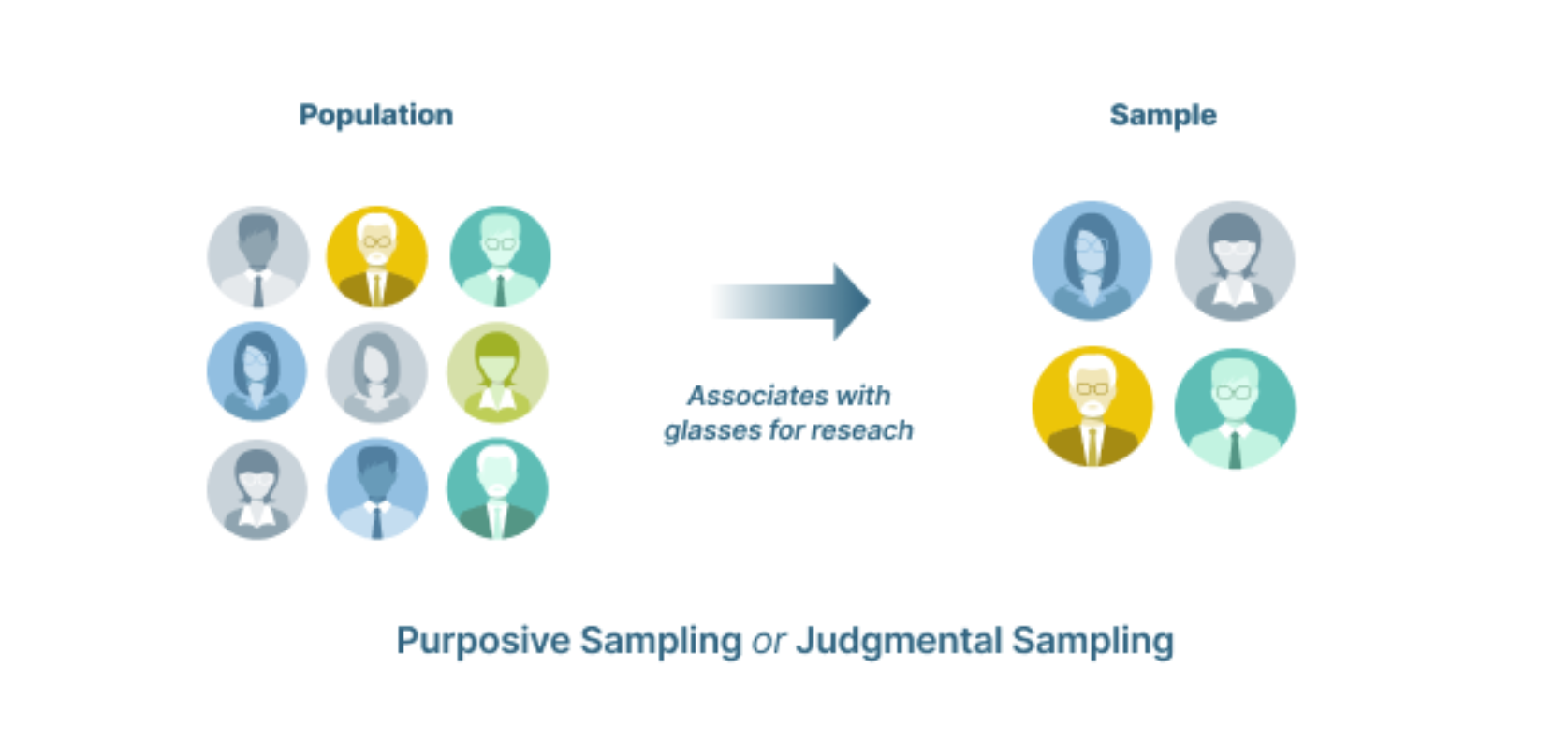
Lấy mẫu cóc mục đích hoặc Lấy mẫu phán đoán
Lấy mẫu cóc mục đích (Purposive Sampling) hay Lấy mẫu phán đoán (Judgmental Sampling) là phương pháp chọn mẫu dựa trên các tiêu chí xác định do người nghiên cứu thiết lập theo mục đích của cuộc nghiên cứu. Những người tham gia được lựa chọn dựa trên kiến thức của họ về câu hỏi trong nghiên cứu. Phương pháp này cho phép các nhà nghiên cứu thu thập các câu trả lời (có hiểu biết) một cách dễ dàng và nhanh chóng.
Tại sao Data Sampling cần thiết cho nghiên cứu?
- Cung cấp đại diện cho tổng thể lớn để có thể phân tích và cung cấp thông tin chi tiết về toàn tổng thể
- Cung cấp bộ dữ liệu dễ quản lý hơn
- Cho phép các nhà nghiên cứu tiến hành phân tích và đánh giá kết quả nhanh hơn
- Giảm chi phí nghiên cứu và thời gian cần để nghiên cứu tổng thể thông qua hạn chế khối lượng dữ liệu được thu thập và xử lý
- Cho phép thống kê suy luận để suy ra những hiểu biết sâu sắc về toàn bộ tổng thể
Quy trình Data Sampling
Trong bất kể phương pháp lấy mẫu dữ liệu nào được sử dụng, các mẫu đều phải có kích thước chính xác và không sai lệch khi thu thập. Các yếu tố cần xem xét bao gồm:
- Dữ liệu được lấy mẫu là dữ liệu liên tục (nghĩa là dữ liệu được tính bằng số) hay dữ liệu phân loại (tức là được đưa vào các danh mục, như xanh lá cây, xanh dương, nam hoặc nữ)
- Độ chính xác cần thiết cho các suy luận thống kê
- Ước tính độ lệch chuẩn cho tổng thể
- Mức độ tin cậy mong muốn (Confidence Level)
Cách xác định kích thước mẫu
Các bước dưới đây là cách xác định kích thước mẫu cho dữ liệu liên tục (continuous data). Để bắt đầu, các biến kích thước mẫu nên được xem xét, gồm những vấn đề sau:
- Quy mô tổng thể
- Sai số và độ tín nhiệm (nghĩa là ước tính ± sai số)
- Mức độ tin cậy (mức độ phổ biến nhất là 90% tin cậy, 95% tin cậy và 99% tin cậy.
- Độ lệch chuẩn (nghĩa là ước tính mức độ khác nhau của các câu trả lời với nhau và so với số trung bình)
Một khi các biến kích thước mẫu đã được xác định, có thể tính toán được kích thước mẫu.
Các bước tính kích thước mẫu
Bước 1: Biến mức độ tin cậy thành điểm Z - một cách thống kê phổ biến để chuẩn hóa dữ liệu trên thang đo để có thể so sánh. Điểm Z cho các mức độ tin cậy phổ biến nhất là:
- 90% - Điểm Z = 1,645
- 95% - Điểm Z = 1,96
- 99% - Điểm Z = 2,576
Công thức tính điểm Z là:
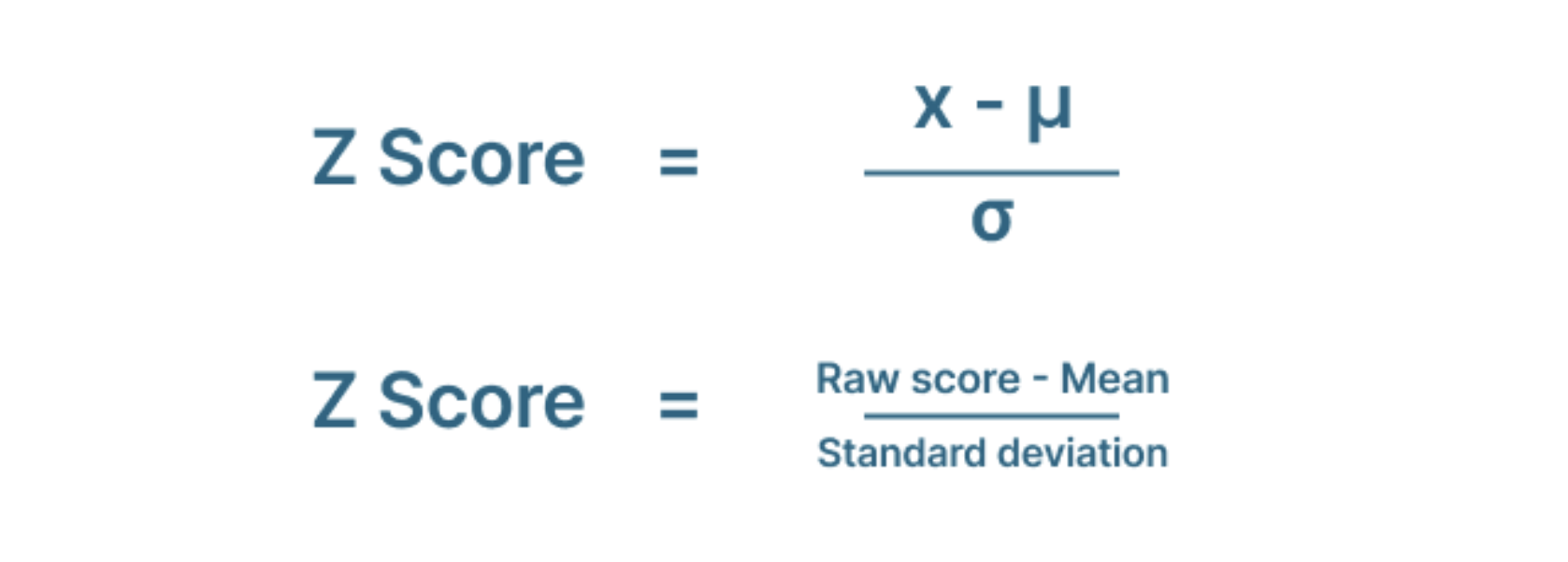
Bước 2: Sử dụng công thức kích thước mẫu để tính toán
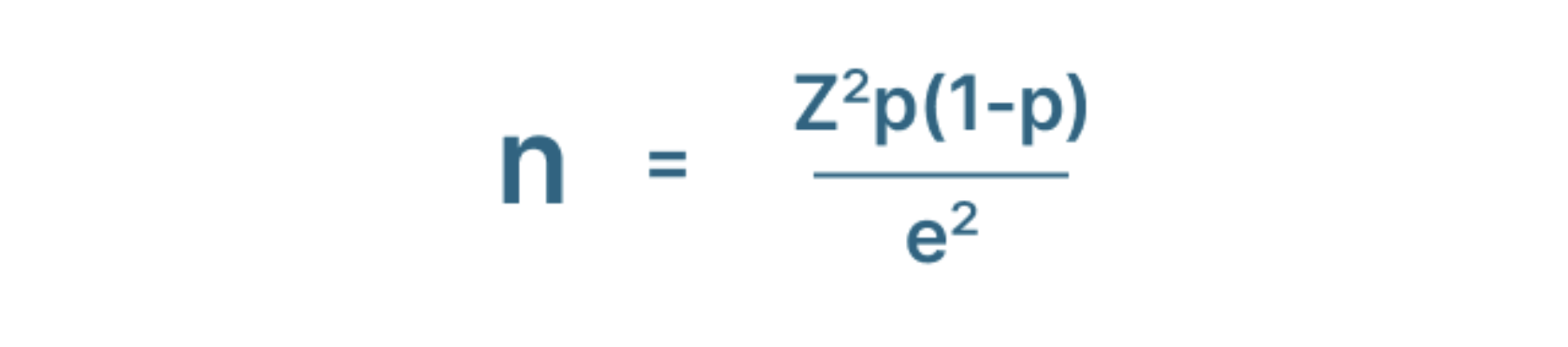
n: kích thước mẫu cần thiết
Z: Điểm số Z
p: độ lệch chuẩn
e: biên độ lỗi
Một số lỗi Data Sampling phổ biến
Một trong những lỗi lấy mẫu dữ liệu thường thấy là độ lệch giữa ước tính của mẫu lý tưởng so với tổng thể trên thực tế. Data Sampling nghĩa là tạo ra các mẫu là tập hợp con, đại diện cho tổng thể, với giá trị trung bình của mẫu bằng giá trị trung bình của tổng thể.
Lỗi lấy mẫu xảy ra khi không đạt được mục đích đó, đồng thời do tính không xác định vốn có của các hệ thống tự nhiên. Có hai loại không chắc chắn trong bất kỳ hệ thống nào là không xác định về nhận thức - epistemic uncertainty (lỗi dự kiến do thiếu dữ liệu) và không xác định về ngẫu nhiên - aleatoric uncertainty (lỗi không thể đoán trước).
Mặc dù theo định nghĩa, các nhà nghiên cứu không thể làm gì nhiều với aleatoric uncertainty, nhưng họ có thể thừa nhận sự hiện diện của nó trong các mô hình và cố gắng giảm thiểu epistemic uncertainty càng nhiều càng tốt.
Để có thể giảm thiểu sự không xác định về nhận thức, bước đầu tiên là hiểu các loại lỗi lấy mẫu phổ biến trong quá trình nghiên cứu.
Các loại lỗi Data Sampling
- Lỗi tổng thể: Xảy ra khi người nghiên cứu không biết ai để khảo sát
- Lỗi lựa chọn: Xảy ra chỉ khi những người tham gia hứng thú với khảo sát trả lời các câu hỏi
- Lỗi khung mẫu: Xảy ra khi một mẫu được chọn từ dữ liệu tổng thể sai
- Lỗi không phản hồi: Xảy ra khi không nhận được phản hồi hữu ích
Thiên kiến Data Sampling
Thiên kiến lấy mẫu dữ liệu liên quan đến sai lệch lấy mẫu do cách thức thu thập mẫu gây ra. Điều này dẫn đến một số phần tử trong tổng thể có thể có ít hoặc nhiều xác suất được lấy mẫu hơn các phần tử khác. Các loại thiên kiến lấy mẫu dữ liệu bao gồm:
- Thiên kiến phản hồi: Xảy ra trong quá trình thu thập dữ liệu khi người tham gia đưa ra câu trả lời không đúng sự thật, dễ gây hiểu lầm
- Thiên kiến trả lời tự nguyện: Xảy ra khi các cá nhân tự lựa chọn (self-selected) hoặc lựa chọn tham gia
- Thiên kiến không trả lời: Xảy ra khi người tham gia không trả lời toàn bộ hoặc một phần
- Thiên kiến thuận tiện: Xảy ra khi một mẫu được lấy từ các cá nhân có sẵn
Ba cách để loại bỏ lỗi Data Sampling
1. Tăng cỡ mẫu
2. Thực hiện lặp đi lặp lại các phép đo, sử dụng nhiều đối tượng hoặc nhiều nhóm
3. Sử dụng lấy mẫu dữ liệu ngẫu nhiên để thiết lập cách tiếp cận có hệ thống để chọn mẫu
Ưu điểm của Data Sampling
- Mở rộng năng lực nghiên cứu
- Thu thập dữ liệu chuyên sâu và đầy đủ
- Cải thiện độ chính xác của dữ liệu
- Tăng cường mối quan hệ giữa các nhà nghiên cứu và đối tượng
- Chi phí thu thập thông tin về tổng thể thấp hơn
- Thu nhỏ phạm vi nghiên cứu
- Giảm tác động đến nguồn lực của tổ chức nghiên cứu (ví dụ: con người, hệ thống)
- Tiết kiệm thời gian tiến hành nghiên cứu
Data Sampling đóng một vai trò quan trọng trong việc xác định tính hợp lệ của kết quả trong phân tích thống kê. Với nhiều kỹ thuật được tinh chỉnh cho phù hợp với trường hợp sử dụng cụ thể, lấy mẫu dữ liệu là một phương pháp nghiên cứu các quần thể lớn. Nếu được thực hiện đúng cách, data sampling là một công cụ mạnh mẽ cho phép các nhà nghiên cứu làm việc với các bộ dữ liệu thuộc mọi kích cỡ và loại để rút ra những hiểu biết có nghĩa.