Data Dredging (Data Fishing) là gì? Tìm hiểu để tránh sai lệch trong phân tích dữ liệu
BÀI LIÊN QUAN
Khái niệm data integrity và vì sao quy trình này quan trọngData In Use là gì? Cách bảo mật dữ liệu đang sử dụngData ingestion là gì? Các kiểu data ingestion phổ biếnData Dredging (Data Fishing) là gì?
Data dredging (Nạo vét dữ liệu) - đôi khi được gọi là Data fising (Đánh bắt dữ liệu) - là một phương pháp khai phá dữ liệu (data mining), trong đó, phân tích lượng dữ liệu lớn để tìm ra tất cả các mối quan hệ có thể có giữa dữ liệu. Sau đó, các nhà khoa học dữ liệu sẽ đưa ra các giả thuyết về lý do các mối quan hệ này tồn tại. Ngược lại với Data dredging (Data fishing), các phương pháp phân tích khoa học dữ liệu truyền thống bắt đầu từ giả thuyết, sau đó là kiểm tra dữ liệu để chứng minh hoặc bác bỏ giả thuyết.
Khi được thực hiện cho các mục đích không đúng nguyên tắc, Data dredging (Data fishing) thường phá vỡ các kỹ thuật khai phá dữ liệu truyền thống để dẫn đến kết luận sớm.
Tìm hiểu thêm về Data dredging (Data fishing)
Data dredging đôi khi được mô tả là "tìm kiếm nhiều thông tin hơn từ một tập dữ liệu so với nó thực sự chứa".
Data dredging là một cách hữu ích để tìm ra các mối quan hệ đáng ngạc nhiên giữa các biến mà có thể sẽ không phát hiện được bằng cách khác.
Tuy nhiên, hầu hết việc nạo vét dữ liệu đều được sử dụng không đúng cách, đa phần là do vô ý hơn là ác ý. Thông thường, điều này bắt nguồn từ sự thiếu hiểu biết về cách áp dụng các kỹ thuật khai phá dữ liệu nhằm tìm ra các mối quan hệ chưa biết trước giữa các biến khác nhau. Và nó dẫn đến kết quả không được công nhận rằng mối tương quan được phát hiện thực ra chỉ là sự ngẫu nhiên.
Data dredging (data fishing) có thể dẫn đến sự gia tăng kết quả dương tính giả. Điều này xảy ra khi các nhà điều tra công bố mối quan hệ giữa các biến là "có nghĩa" trong khi trên thực tế, dữ liệu cần được nghiên cứu kỹ càng hơn trước khi có thể xác định mối quan hệ và công bố một cách hợp pháp. Các biến cô lập cũng cần được đối chiếu với một nhóm kiểm soát để đưa ra đánh giá hợp lệ về mối quan hệ giữa hai biến bất kỳ và để đảm bảo mối quan hệ đó không chỉ là trùng hợp ngẫu nhiên.

P-value và mối quan hệ với Data dredging (Data fishing)
P-value, giá trị P, là trị giá xác suất, một đại lượng giúp các chuyên gia quyết định tính đúng sau của giả thuyết. Giá trị P càng nhỏ thì độ tin cậy của kết luận sẽ càng cao và giá trị ảnh hưởng của nó càng lớn. Khi P-value nhỏ hơn hoặc bằng 0,05, giả thuyết được chấp nhận.
Để chứng minh rằng họ đã thu thập được dữ liệu "quan trọng", các nhà nghiên cứu có thể chọn dữ liệu phù hợp với giả thuyết hoặc yêu cầu của họ và loại trừ dữ liệu không phù hợp với giả thuyết này. Cho dù họ thực hiện việc chọn này một cách có ý thức hay vô thức, dữ liệu có thể cho thấy mối tương quan giữa các biến chỉ đơn giản ngẫu nhiên hoặc không tồn tại. Những kết luận như vậy dẫn đến sự sai lệch thật nghiêm trọng và lan truyền thông tin không đúng sự thật.
Cũng tồn tại một số trường hợp các nhà nghiên cứu phi đạo đức thực hiện nạo vét dữ liệu và báo cáo một kết quả có ý nghĩa thống kê mặc dù kết quả là dương tính giả và không đáng tin cậy. Tuy nhiên, nhóm đối tượng này không phổ biến và nguyên nhân chính thường phát sinh từ sự thiếu nhận thức.
Ví dụ về Data dredging (Data fishing)
Data dredging (Data fishing) gồm hai loại:
- Nạo vét dữ liệu bằng mẫu không đại diện
- Nạo vét dữ liệu khi chưa kiểm tra kỹ ý nghĩa thống kê (Statistical Significance)
Nạo vét dữ liệu với mẫu không đại diện
Ví dụ bạn đang làm việc cho một chiến dịch tranh cử và nhiệm vụ của bạn là cho mọi người thấy ứng viên đã làm tốt như thế nào trong nhiệm kỳ trước. Chiến dịch yêu cầu bạn tìm kiếm sự thay đổi của những chỉ số xã hội như tỷ lệ xoá mù chữ, tỷ lệ nghèo đói, tỷ lệ nợ y tế và tỷ lệ đói?
Điều hiển nhiên là bạn muốn đem đến những thông tin tích cực nhưng chắc chắn bạn không thể nói dối. Vì vậy, bạn tìm đến một số nguồn và thu thập dữ liệu liên quan trong nhiệm kỳ 8 năm ứng viên của tại vị. Chẳng hạn tập dữ liệu mẫu trông như sau:
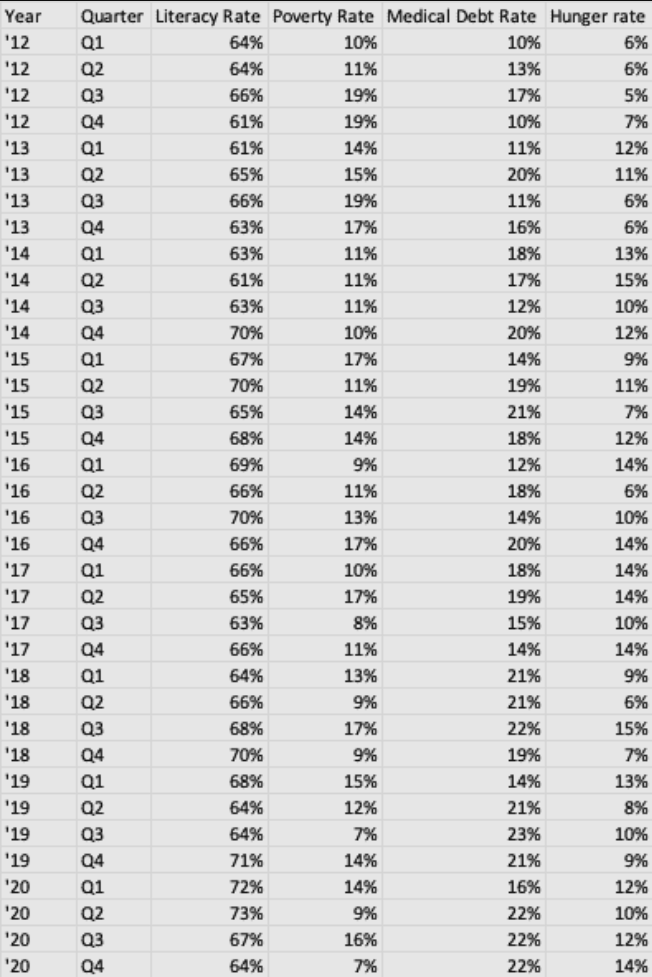
Nhìn vào tập dữ liệu này rất khó để thấy xu hướng, do đó bạn quyết định trực quan hóa nó bằng biểu đồ:
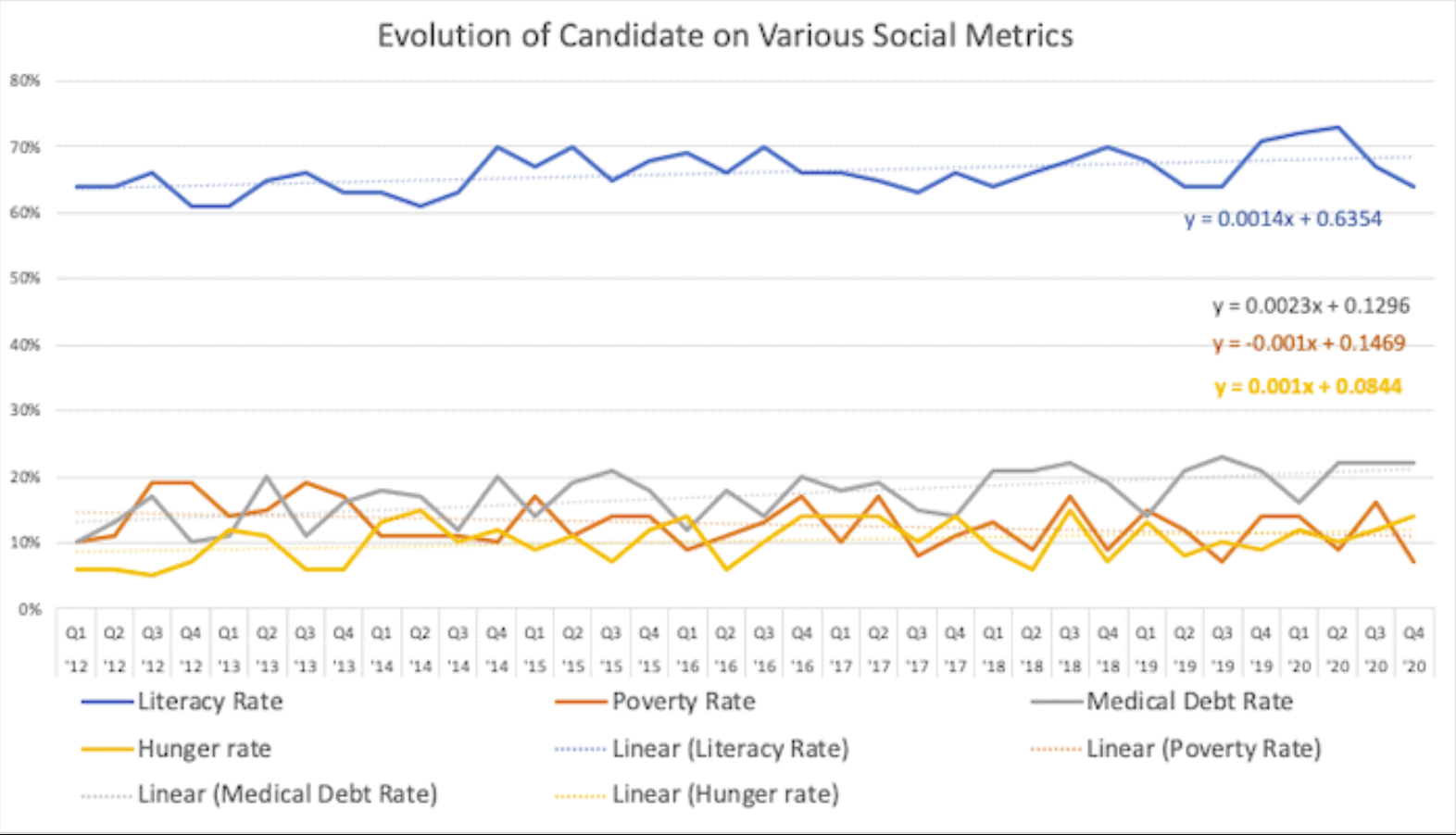
Nói một cách dễ hiểu, có vẻ như trong nhiệm kỳ 8 năm, ứng cử viên đã cải thiện một chút tỷ lệ xoá mù chữ và giảm nhẹ tỷ lệ nghèo. Đồng thời, tỷ lệ nợ y tế trung bình tăng nhẹ và tỷ lệ đói tăng nhẹ. Nói cách khác,ứng cử viên thực sự không làm được gì nhiều, và các dữ liệu là vô dụng cho chiến dịch tranh cử.
Dưới áp lực, bạn quyết định chỉ lấy những chỉ số tốt. Từ cuối năm 2017 đến năm 2018, tỷ lệ xoá mù chữ đã tăng lên đáng kể nhưng số liệu đã quá cũ. Nhìn nhận những dữ liệu gần đây nhất, mọi số liệu, trừ tỷ lệ nghèo, đều có vẻ tiêu cực. Do đó bạn đã cô lập hai quý cuối năm 2020 và đưa ra biểu đồ sau:
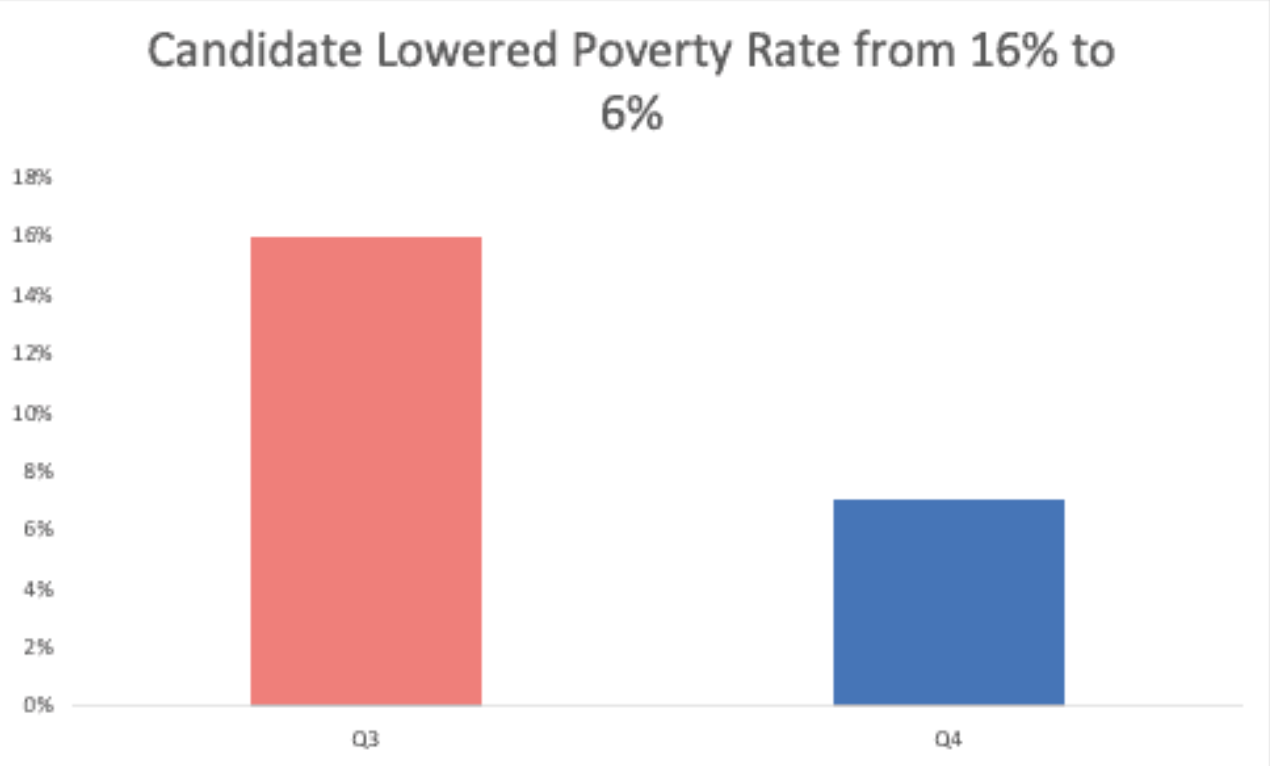
Chúng ta có thể thấy rõ cách biểu đồ này sử dụng lấy mẫu chọn lọc để truyền đạt một thông điệp tích cực nhưng không phản ánh đúng sự thật của tập dữ liệu đầy đủ.
Nạo vét dữ liệu khi chưa kiểm tra kỹ ý nghĩa thống kê
Vị dụ bạn được giao nhiệm vụ tìm hiểu thêm về tác động của các chỉ số thị trường đối với hiệu quả hoạt động của công ty. Lãnh đạo yêu cầu bạn xác định mọi mối tương quan có thể có giữa một tập hợp các chỉ số thị trường và doanh thu của công ty.
Đây là một thách thức rất lớn đối với bạn. Làm thế nào bạn có thể giải quyết vô số mối tương quan khác nhau để tạo ra một nghiên cứu chất lượng mà vẫn giao đúng thời hạn? Bạn nhận ra điều đó là không thể, vì vậy bạn quyết định sử dụng ngôn ngữ lập trình R để thực hiện hồi quy một biến và hồi quy đa biến giữa một tập hợp các chỉ số thị trường và doanh thu của công ty. Các chỉ số bao gồm:
- GDP
- GNI
- Thu nhập khả dụng
- Tỷ lệ thất nghiệp
Đây là lúc rủi ro xuất hiện. Giả sử bạn chạy 4 phép hồi quy một biến, tất cả đều cho thấy giá trị p lớn hơn 10% đối với doanh thu của bạn. Giá trị p cao hơn 5% đã được cho là bằng chứng khẳng định không có mối liên hệ nào giữa hai biến. Tuy nhiên, khi bạn chạy kết hợp các biến độc lập ấy với doanh thu trong hồi quy đa biến, bạn có thể nhận được mối tương quan giữa GDP và Tỷ lệ thất nghiệp với giá trị p nhỏ hơn 5%, tức là có ý nghĩa thống kê.
Điều này diễn ra do quá trình cộng tuyến (collinearity), khi nhiều biến độc lập có liên hệ tương quan chặt chẽ với nhau, chúng biến đổi cùng nhau, dẫn đến làm sai lệch các hệ số và giá trị P của nhau.
Nguyên nhân là vì bạn đang bị ràng buộc trong suy nghĩ GDP và Tỷ lệ thất nghiệp có mối quan hệ chặt chẽ với doanh thu. Dù có những kết quả trái ngược nhau về ý nghĩa thống kê của hai mối tương quan, nhưng vì một mặt của bằng chứng hỗ trợ cho tuyên bố mà bạn muốn đưa ra, nên bạn quyết định chấp nhận nó. Một nhà phân tích thực sự sẽ không đưa ra tuyên bố như vậy.
Tác động của Data dredging (Data fishing)
Data dredging (data fishing) có thể có tác động tiêu cực đến các nghiên cứu mà người thực hiện không hề hay biết. Khi được thực hiện một cách có chủ ý, đây là một hành vi phi đạo đức, có thể làm sai lệch hoàn toàn kết quả nghiên cứu và thử nghiệm. Nó cũng có thể đánh lừa công chúng hoặc bất kỳ ai liên quan đến kết quả.
Một số tác động phổ biến của việc nạo vét dữ liệu bao gồm:
- Tạo ra các kết quả dương tính giả, ảnh hưởng đến độ tin cậy của kết quả;
- Gây hiểu lầm cho các nhà điều tra khác và ảnh hưởng đến kết quả nghiên cứu của họ;
- Tăng sự thiên vị của một nghiên cứu;
- Mất các nguồn lực quan trọng, đặc biệt là nhân lực;
- Buộc các nhà nghiên cứu phải rút lại các nghiên cứu đã công bố; dẫn đến lãng phí kinh phí thử nghiệm.
Data Mining so với Data Dredging
Các thuật ngữ data mining - khai phá dữ liệu và data dredging - nạo vét dữ liệu thường được sử dụng thay thế cho nhau, tuy nhiên chúng là các khái niệm khác biệt. Nạo vét dữ liệu thường diễn ra khi việc khai phá dữ liệu bị lạm dụng.
Trong khai phá dữ liệu, các tập dữ liệu lớn được kiểm tra để xác định các liên kết giữa các biến khác nhau. Sau đó, một giả thuyết được hình thành về lý do tại sao những mối quan hệ này tồn tại. Khi có nhiều sức mạnh tính toán hơn, data mining nổi lên như một công cụ nghiên cứu hữu ích để phân tích khối dữ liệu lớn hơn so với trước đây.
Ngược lại, việc nạo vét dữ liệu thường liên quan đến việc kiểm tra một tập dữ liệu cụ thể nhiều lần để tìm mối quan hệ giữa các biến. Thông thường, những mối quan hệ này là sự ngẫu nhiên và là kết quả dương tính giả hơn là kết quả thực sự. Nếu không thực hiện các biện pháp phòng ngừa, data dredging có thể được sử dụng theo những cách phi đạo đức nhằm tạo ra kết quả trông có vẻ chân thực nhưng thực ra không đáng tin cậy.
Làm thế nào để tránh Data dredging (Data fishing)?
Lời khuyên dành cho các nhà phân tích là hãy tin vào trực giác của bạn. Hầu hết các nhà phân tích đều đã nắm chắc các nguyên tắc khoa học và khi có điều gì đó không ổn, họ sẽ lập tức cảm nhận thấy.
Khi có cảm giác đó, bạn nên tự hỏi những câu hỏi sau:
- Có phải tất cả các bằng chứng, cả về mặt thống kê và trực giác, đều hỗ trợ cho tuyên bố mà tôi đang đưa ra không?
- Có phải tôi muốn lấy kết quả này vì tôi áp lực thực hiện không?
- Tôi có đang sử dụng một tập hợp con dữ liệu để đưa ra yêu cầu mà tôi muốn đưa ra không, ngay cả khi tập hợp con này không đại diện cho tổng thể?
- Tôi có đang sử dụng phép kiểm tra ý nghĩa thống kê trên nhiều biến số khác nhau, trong các kết hợp khác nhau, để đạt được kết quả như mong muốn không?
Nếu bạn trả lời Không cho câu hỏi 1 hoặc Có cho câu hỏi 2-4, thì bạn nên cân nhắc cách thu thập dữ liệu và xem xét ảnh hưởng của nó đối với kết quả.
Hy vọng bài viết đã giúp bạn hiểu rõ hơn về Data dredging (Data fishing) - Nạo vét dữ liệu (Đánh bắt dữ liệu). Theo dõi Meey Land để đón đọc những thông tin thú vị về thế giới công nghệ!